













目前,大多数企业采用Apache Flink与Kafka相结合的方式进行实时数据处理,即kafka从其他端获取数据后,⽴刻到Flink进行计算,Flink计算完后结果导入到数据库,整个过程是数据流式处理。然而,由于Kafka不在磁盘中持久保存数据,在极端情况下,数据可能会丢失。
综合研究了市场上主流的数据库和存储系统以后,笔者发现了一个更有效、更准确的实时数据仓库解决方案,即通过Pravega+TiDB这种架构组合,来构建实时数据仓库。
在这篇文章中,我们将重点介绍Pravega分布式流存储系统、TiDB分布式SQL数据库能给用户带来哪些价值,以及这种组合如何解决Kafka数据持久性挑战。同时,Pravega+TiDB在自动扩展、实时数据仓库的高并发性、可用性和安全性等方面有哪些表现。
Pravega——重构流式存储架构
Pravega 是Dell Emc开源分布式流存储系统,也是全球顶级开源基金会CNCF(云原生计算基金会)的沙盒项目。与Kafka和Apache Pulsar相似,Pravega重点解决了流批统一问题。
除此之外,Pravega功能更丰富:
- 自动化扩展能力更强。
- Pravega,是一个完整的存储接口,提供以 stream 为抽象的接口,支持上层计算引擎的统一访问。

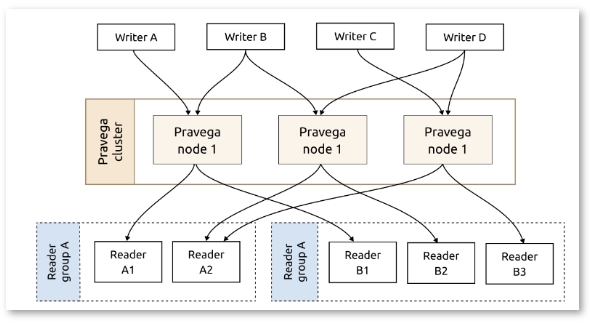
▲Pravega架构
在分布式系统中,客户端应用程序和消息系统之间的异步传递信息,一般基于消息队列来实现。提到消息队列,大家首先会想到Kafka。Kafka是一个基于Zookeeper的分布式日志系统。它支持多分区、多副本和多订阅者。
可以说,Pravega重构了流式存储架构,主要为解决Kafka无法解决的问题而建立。作为一个实时流式存储解决方案,Pravega支持长期数据保留。Pravega在Hadoop分布式文件系统(HDFS)或S3上写入数据,从而消除了对数据持久性的担忧。此外,Pravega在整个系统中只存储一个数据副本,从架构设计上解决了Kafka无法解决的问题。

为什么Pravega胜过Kafka?
你可能会问,"既然已经有了Kafka,为什么还要重新发明轮子?" 答案是,使用Kafka存在一个重要挑战,那就是数据丢失、数据保留和再平衡问题。Kafka吃的数据比它吐出的多,存在着数据丢失的风险。
- 当你设置acks = all时,只有当所有消费者确认消息被保存时才会返回ACK,不会丢失数据。
- 当acks = 1时,如果leader消费者保存了消息,就会返回ACK。如果leader在备份数据之前就关闭了,数据就会丢失。
- 当acks=0时,Kafka不等待消费者的确认。当消费者关闭时,数据就会丢失。
Kafka没有提供一个简单有效的解决方案来将数据持久化到HDFS或S3,所以数据保留成为一个问题。虽然Confluent提供了相关解决方案,但你必须使用两套存储接口来访问不同层的数据。
- 使用Apache Flume通过Kafka -> Flume -> HDFS访问数据。
- 使用kafka-hadoop-loader通过Kafka -> kafka-hadoop-loader -> HDFS来访问数据。
- 使用Kafka Connect HDFS通过Kafka -> Kafka Connect HDFS -> HDFS来访问数据。
消费者再平衡也是有害的。因为新的消费者被添加到队列中,队列可能在重新平衡期间停止消费消息。因为提交间隔时间长,消费者可能会重复处理数据。无论哪种方式,重新平衡都可能导致消息积压,从而增加延迟。
与Kafka相比,Pravega提供了更多的功能。

▲Pravega VS Kafka
Pravega的特别之处在于,使用Apache BookKeeper来处理低延迟、高并发和数据的实时写入等问题。然而,BookKeeper只作为一个缓存层,用于批量写入。所有对Pravega的读取请求都是直接向HDFS或S3发出,以利用其高吞吐量能力。
换句话说,Pravega不使用BookKeeper作为数据缓冲层,而是提供一个基于HDFS或S3的存储层。这个存储层既支持低延迟的尾部读写,也支持高吞吐量的追赶式读取的抽象。当数据在BookKeeper和HDFS或S3之间移动时,使用BookKeeper作为独立层的系统可能表现不佳。相比之下,Pravega可以确保令人满意的性能。
Pravega的优势与价值
通常,DBA有三个主要关注点:数据准确性、系统稳定性和系统可用性。
- 数据的准确性是非常重要的。任何数据丢失、损坏或重复都将是一场灾难。
- 系统的稳定性和可用性使DBA从繁琐的维护程序中解脱出来,让他们将时间投入到改善性系统应用中。
Pravega解决了DBA的这些担忧。它长期保留保证了数据的安全性,并且以精确的一次语义保证了数据的准确性,尤其是自动扩展性,使系统维护变得轻而易举。
实时数据仓库是怎样一个架构?
问题是,实时数据仓库应该包含哪些关键组成部分?
一个实时数据仓库通常有四个组成部分:数据采集层、数据存储层、实时计算层和实时应用层。通过将多种技术整合到一个无缝的架构中,我们可以建立一个可扩展的大数据架构,可以支持数据分析和挖掘,在线交易,以及统一的批处理和流处理等等。

▲实时数据仓库的四个组成部分
数据存储层有多种选择,但不是所有的都适合实时数据仓库:
- Hadoop或传统的OLAP数据库不能提供令人满意的实时处理。
- 像HBase这样的NoSQL解决方案可以实时扩展和处理数据,但不能提供分析。
- 独立的关系型数据库不能扩大规模以适应大量数据。
然而,TiDB解决了所有这些需求。
为什么选用TiDB?
TiDB是一个开源的分布式SQL数据库,支持混合交易和分析处理(HTAP)工作负载。它与MySQL兼容,具有水平扩展性、强一致性和高可用性。
与其他开源数据库相比,TiDB这种HTAP架构更适合于建立实时数据仓库。TiDB拥有一个混合存储层,由TiKV(行存储引擎)和TiFlash(列存储引擎)组成。这两个存储引擎使用TiDB作为一个共享的SQL层。TiDB回答在线事务处理(OLTP)和在线分析处理(OLAP)查询,并根据执行计划的成本从任何一个引擎中获取数据。

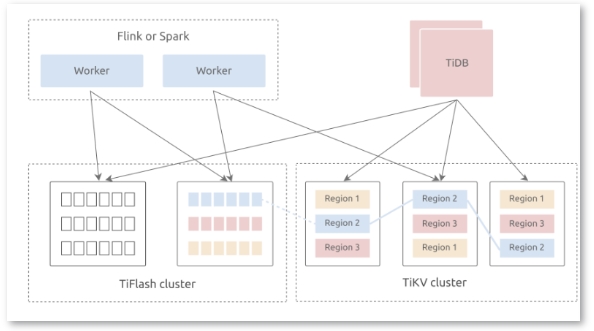
▲TiDB HTAP架构
此外,TiDB 5.0引入了大规模并行处理(MPP)架构。在MPP模式下,TiFlash补充了TiDB的计算能力。在处理OLAP工作负载时,TiDB成为一个主节点。用户向TiDB服务器发送请求,所有的TiDB服务器执行表连接,并将结果提交给优化器进行决策。优化器评估所有可能的执行计划(基于行、基于列、索引、单服务器引擎和MPP引擎),并选择最佳计划。

▲TiDB的MPP模式
例如,一个订单处理系统在销售活动中可能会遇到一个突然的流量高峰。在这个高峰期,企业需要进行快速分析,以便及时对客户行为做出反应和回应。传统的数据仓库很难在短时间内应对泛滥的数据,而且可能需要很长的时间来进行后续的数据分析处理。
通过MPP计算引擎,TiDB可以预测即将到来的流量高峰,并动态地扩展集群,为活动提供更多的资源。并且,它可以轻松地在几秒钟内响应聚合和分析请求。
当TiDB遇到Pravega
在Flink的帮助下,当TiDB遇到Pravega,构成了一个实时、高吞吐量、稳定的数据仓库,该数据仓库能够满足用户对大数据的各种要求,并能一站式地处理OLTP和OLAP工作负载。





















