缓存是互联网应用中不可或缺的一部分。而提到缓存,就不得不提它的三个经典问题——缓存穿透、缓存击穿和缓存雪崩,我称它们为缓存问题三兄弟。
缓存的作用主要有两个:一来提升访问速度;二来保护数据库。在业务量不大的时候,通常没什么大问题。但当业务量起来以后,如果缓存使用不合理,三兄弟一定会如约而至,让你体验一下现实的残酷。
三兄弟不来则已,一来轻则影响系统性能,重则直接拖垮数据库,导致系统瘫痪。因此,我们不可掉以轻心,要防患于未然。
缓存穿透
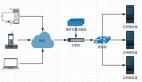
一个请求到达服务器时,正常情况下是按照如下流程进行的。

即按照如下步骤:
- 查询缓存,如果命中则返回。
- 缓存未命中,则查询数据库。
- 将从数据库中查询到的数据写入缓存并返回。
如果每次都是这样按部就班的处理,倒也相安无事。但是,凡事就怕但是。但是总会有例外,假如请求方对一个(数据库中)根本不存在的数据进行访问,那么按照上面的流程,缓存就形同虚设了。因为不存在,所以不会被写入缓存,这样请求每次都会打到数据库,这个现象就是所谓的「缓存穿透」了。
如果只是因为个别请求去查询不存在的数据,那其实也没什么大事。但缓存穿透通常是伴随一些「恶意请求」而来,通常是在短时间内涌入大量请求。如果放任不管,就等着数据库宕机吧。
如何解决
了解了导致缓存穿透的原因,那么解决方案也就明了了。可以从两个方面下手:
- 缓存不存在的记录。
- 过滤不存在的请求。
啥?不存在的记录咋缓存?其实很简单,如果数据库中也查不到,那就将缓存的 value 设置成 null 即可(注意要根据业务特性设置合理的过期时间)。
过滤不存在的请求,当一个请求到达服务器,比如:
GET /api/user/1
过滤器会先判断该资源是否存在,如果存在则放行,不存在则直接返回,从而起到保护系统的作用。
这种方式也有比较成熟的方案。比如布隆过滤器和布谷鸟过滤器(升级版布隆布隆过滤器)。
双重加固
不管请求不存在的资源是有意还是无意,都不是我们想要的。所以,我们可以设定一个访问频率,一定时间内频繁(超出正常用户的极限)访问,可以对请求方加以限制(如 IP 限制)。另外,一些接口可以加入认证,必须登录才能访问。
缓存击穿
通常情况,我们会为缓存设置一个过期时间。而如果在一个资源的缓存过期以后(或者还未来得及缓存),瞬间涌入大量查询该资源的请求,那么这些请求就都会一股脑的奔向数据库,这时,我们的数据库可就惨了,可能秒秒钟挂掉。这种情况我们称之为缓存击穿。
如何解决
要解决缓存击穿也有两种思路:
- 永不过期。
- 加锁。
先看第一种,短时间内被大量访问的通常是热点资源,针对这类资源我们可以不设置过期时间(永不过期),当资源有变化时通过程序去更新缓存。
再来看第二种,我们可以使用加锁的方式(一般 JVM 级别的锁即可)来避免击穿。当缓存过期之后,进来的请求,先要获得一把锁(也就是去数据库查询的资格),然后再去查询数据库,最后将数据添加到缓存。这样就可以保证同一时刻(一个服务实例)只会有一个请求去查库了,其他线程等缓存有值以后,再去缓存取。
加锁伪代码示例:
public String getData() throws InterruptedException {
// 从缓存取值
String result = getFromCache();
// 取到直接返回
if (Objects.nonNull(result)) {
return result;
}
// 尝试获取锁
if (!lock.tryLock()) {
// 加锁失败则休息一会
Thread.sleep(10);
return getData();
}
// 加锁成功则去数据库取值
result = getFromDB();
// 取回后放入缓存
setFromCache();
return result;
}
缓存雪崩
缓存雪崩指的是,缓存中大量的 key 在同一时刻集体过期,导致大量请求涌入到数据库。
有人把缓存服务由于一些原因不可用称为缓存雪崩,我觉得这么叫不太合适。
你想象一下什么是雪崩,大量的雪花集体从山上往下跳就是雪崩。那么对应到缓存的场景,我们可以把 Redis 看做是山,而 Redis 里的 key 就是雪花。Redis 中大量的 key 同时失效,就好比是山上大量的雪花同时往下掉是一样的。所以雪崩用来比喻大量 key 集中失效的情况明显更贴切。而缓存服务挂掉应该属于缓存服务故障,可以采取缓存集群的方式来提高可用性。
如何解决
要解决缓存雪崩的问题,有两种思路:
- 分散过期时间。
- 永不过期。
分散过期时间很容易想到,既然雪崩是因为 key 集体过期导致的,那么把它们过期的时间分散开就可以避免这种问题了。
另一种思路,跟解决缓存击穿一样,将缓存设置为永不过期。
永不过期的方案有一定的局限性,要看具体的业务,不能粗暴的将所有缓存都设置成不过期。
总结
每种技术方案都有其适用的业务场景,也都有其局限性。没有一个方案能够应对所有问题,合适即是好。但从上面的方案中还是能看到一些通用的思想的,比如:尽早返回。咋理解呢?就是让调用链尽量的短,能拦在应用服务之前的绝不放行(布隆过滤);能从缓存取到的绝不再去查库。