“Serverless(无服务器)”有很多令人兴奋的地方,包括对其确切含义的争论(例如,考虑到代码仍然在某个服务器上运行,“Serverless”是否是一个有意义的名称)。
不管“Serverless”确切定义如何,Serverless的基本思想是通过将开发人员与执行他们创建的编程逻辑的基础结构分离,达到简化开发人员生活的目的。
与传统单体式应用程序开发中的开发人员的体验不同,在传统单体式应用程序开发中,开发人员往往要花费大量时间考虑其代码如何与整个应用程序的体系结构和操作进行集成和交互。
相比之下,Serverless的承诺是,开发人员只需通过一个简单的API和抽象,专心关注他们的逻辑实现,而由基础架构和操作团队负责处理和执行该逻辑的环境。
目前市场上已经存在不少通用型无服务器框架,但是,相同的概念也可以应用于更具体的技术支持方面。
现在我们来说一说"流处理"。流处理传统上是专用流处理引擎(SPE,即“specialized stream processing engines”)的领域,如Apache Storm、Apache Heron 等。这些SPE提供了复杂的框架和执行模型,能够执行各种各样的处理。
流处理的方法主要基于函数编程概念(如map、flatmap等)和将处理流编译成有向无环图(DAG)等思想,同时,流处理的方法也融入了许多混合流处理系统,包括Apache Spark Streaming、Apache Kafka Streams和Apache Flink。尽管这些框架功能强大且灵活,但大多数开发人员都不熟悉这些框架,学习起来相当繁琐。另一方面,运营团队在生产中管理起来也很复杂。
总之,复杂性和开销一直是数据处理中运用流技术的一个重要障碍。
然而,新技术正在将无服务器概念引入流处理领域。在本文中,我们将探讨Pulsar函数如何将无服务器概念引入Apache Pulsar消息传递系统内的流处理中。
流处理的方法主要基于函数编程概念(如map、flatmap等)和将处理流编译成有向无环图(DAG)等思想,同时,流处理的方法也融入了许多混合流处理系统,包括Apache Spark Streaming、Apache Kafka Streams和Apache Flink。尽管这些框架功能强大且灵活,但大多数开发人员都不熟悉这些框架,学习起来相当繁琐。另一方面,运营团队在生产中管理起来也很复杂。
很多数据处理应用的场景是简单和轻量级的。简单的ETL(提取、转换和加载)操作、基于事件的服务、实时聚合和事件路由都是不需要复杂拓扑或处理框架的应用场景。
虽然这些应用场景可以使用SPE(专用流处理引擎)实现,但开发人员和用户一直受到以下问题的困扰:
1.设置一个单独的流处理集群太复杂和繁重,尤其是考虑到用户只需要SPE功能的一小部分时;
2.对于这种简单的处理来说,操作成本太高,这是因为成熟的SPE有很多特性,以致于它们在部署、监控和维护方面自然具有很高的复杂性;
3.对于大多数简单的应用场景来说,成熟SPE的API过于复杂和复杂,许多SPE都有基于函数编程模型的API(例如map、flatmap、reduce等),这些API可能是一个强大的工具,但对于许多应用场景,尤其是如果用户对函数式编程范式不熟悉时,这一方案可能显得过于复杂和笨拙。
Pulsar函数的创建使得在流数据上开发和部署处理逻辑更加容易。其开发具有以下设计目标。
1.简单API:任何有能力用受支持的语言编写函数的人都应该能够在几分钟内完成工作;
2.多语言:支持Java、Scala、Python、Go和JavaScript等流行编程语言;
3.内置状态管理功能:为了简化开发人员的体系架构,应该允许在计算过程中,让计算保持状态。系统应该以稳固的方式保持这种状态,诸如递增、获取、存储和更新功能等基本功能是必需的;
4.托管运行时:开发人员不必担心在何处以及如何运行计算,开发人员只需提交他/她的计算,系统就会运行之:
5.自动负载平衡:托管运行时应负责为函数分配工作线程。
6.可调整:用户应该能够使用托管运行时调整函数实例的数量。
7.容错:托管运行时还应以可靠和容错的方式运行开发人员的计算,以便最大限度地减少停机时间。
8.多租户:不同的计算应该相互隔离。开发人员应指定其计算所需的资源量,运行时将强制执行这些资源配额。
9.灵活的部署模型:计算应能够作为线程、进程、docker容器等运行。此外,它们还应支持在Kubernetes等外部调度程序上运行。
什么是Pulsar函数?
Pulsar函数是一个轻量级的处理框架,位于Apache Pulsar消息传递和流媒体平台内部。Pulsar函数的灵感不仅来自Apache Heron和Apache Storm等流处理引擎,还受到AWS Lambda和Google云函数等函数即服务(FaaS)产品的影响。
Pulsar函数可以使用Java、Python等通用语言编写处理函数,并将这些函数部署到Pulsar集群,并不需要使用复杂的SDK。Pulsar负责设置函数的执行环境,提供弹性支持,并确保遵循消息传递保证。处理逻辑可以是在函数中容纳的任何内容,包括数据转换、动态路由、数据丰富(data enrichment)、数据分析等。
总之,Pulsar函数的美妙之处在于,开发者可以享受SPE(服务资源调配环境,即“Service Provisioning Environment”)的好处,而无需部署SPE。如果开发者已经在使用SPE或仍然需要部署SPE,那么可以轻松地将Pulsar连接到任何流处理引擎(包括Apache Spark Streaming、Apache Storm、Apache Heron或Apache Flink)。
脉冲星函数的工作原理
Pulsar函数使用来自一个或多个Pulsar主题的数据,支持使用自定义逻辑处理数据。
并且,在必要时支持使用简单的API将结果写入其他Pulsar主题。同一个Pulsar函数的一个或多个实例能够执行用户定义的处理逻辑。其中,一个函数可以使用提供的状态接口来持久化中间结果,而其他函数负责查询该状态以检索这些结果。
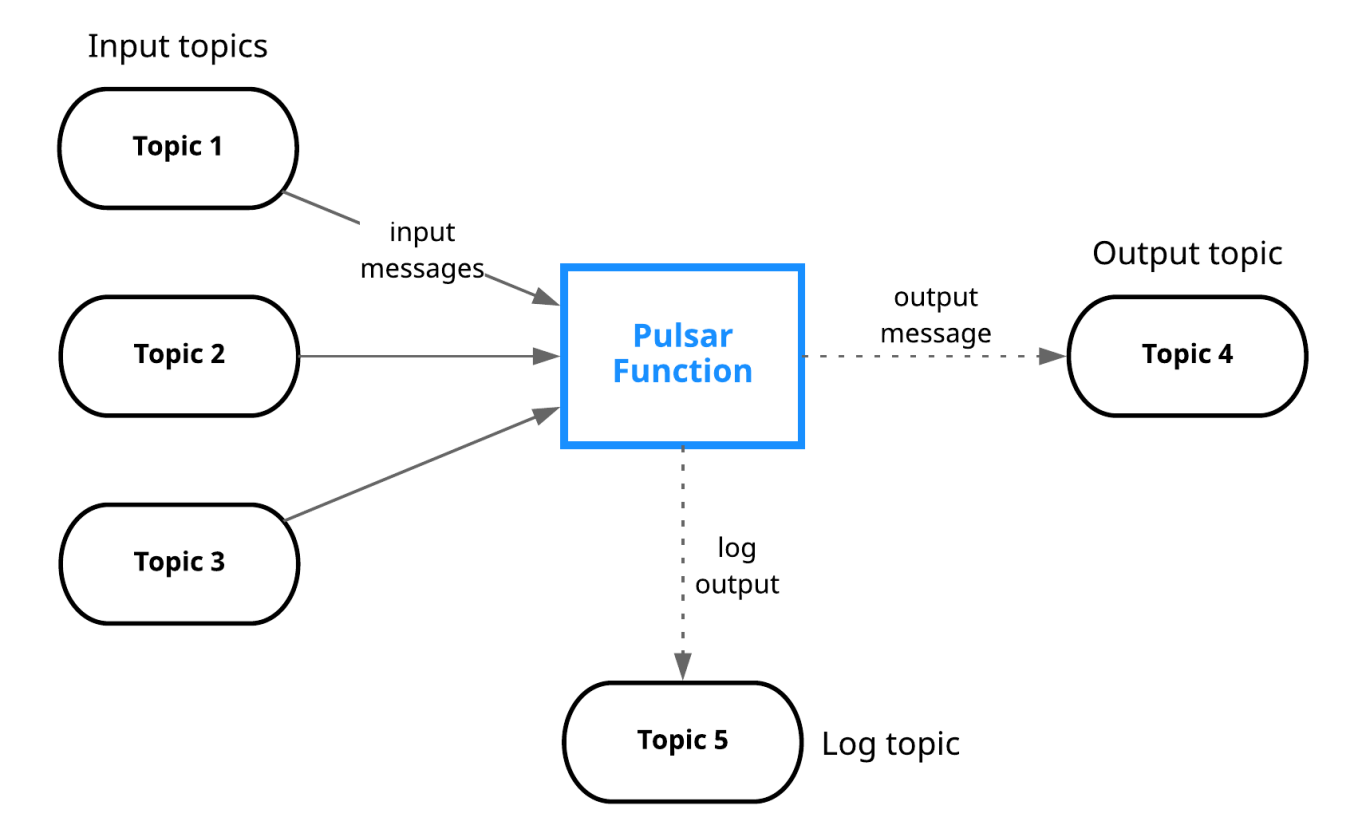
在最简单的情况下,您甚至不需要SDK来实现Pulsar函数。例如,在Java中,用户可以仅实现只有一个apply方法的java.util.function.Function接口。下面是一个Pulsar函数的示例,该函数对消息应用了一种简单的转换操作(在字符串中添加一个字符“!”):
import java.util.Function;
public class ExclamationFunction implements Function<String, String> {
public String apply(String input) { return String.format("%s!", input); }
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
如果用户需要与上下文相关的信息,例如函数的名称,那么用户可以只实现PulsarFunction接口而不是Java的Function接口。下面给出一个相应的示例:
public interface PulsarFunction<I, O> {
O process(I input, Context context) throws Exception;
}- 1.
- 2.
- 3.
Pulsar函数可以使用多种配置来进行部署。下面,我们将展开详细讨论。
Pulsar函数部署方案选择
Pulsar函数由称为实例的执行器运行。单个实例执行函数的一个副本。Pulsar函数具有内置的并行性,因为一个函数可以有许多实例,这些实例的数量可以在函数的配置中设置。
为了最大限度地提高部署灵活性,Pulsar函数提供了多种执行环境来支持多种部署选项,并提供了大量运行时来执行用不同编程语言编写的函数。当前支持以下执行环境:
运行时 | 描述 |
进程运行时 | 每个实例都作为一个进程运行。 |
Kubernetes / Docker 运行时 | 每个实例都作为Docker容器运行 |
线程运行时 | 每个实例都作为线程运行,这种类型仅适用于Java实例,因为Pulsar Functions框架本身是用Java编写的 |
每个执行环境都会产生不同的成本,并提供不同的隔离保证。
运行Pulsar函数
运行Pulsar函数最简单的方法是实例化一个运行时和一个函数,并在本地运行它们(本地运行模式)。有一个助手命令行工具使这一点非常简单。在本地运行模式下,该函数作为独立运行时运行,可以由可用的任何进程、Docker容器或线程控制机制进行监视和控制。
用户可以手动在机器上生成这些运行时,或者使用复杂的调度程序(如Mesos/Kubernetes)将它们分布到集群中。以下是在“本地运行”模式下启动Pulsar函数的命令示例:
$ bin/pulsar-admin functions localrun \
--inputs persistent://sample/standalone/ns1/test_src \
--output persistent://sample/standalone/ns1/test_result \
--jar examples/api-examples.jar \
--className org.apache.pulsar.functions.api.examples.ExclamationFunction- 1.
- 2.
- 3.
- 4.
- 5.
用户还可以在Pulsar集群内与代理一起运行函数。在这种模式下,用户可以向正在运行的Pulsar集群“提交”其功能,Pulsar将负责在集群中分发这些功能,并监视和执行这些功能。
该模型允许开发人员专注于编写他们的函数,而不用担心管理函数的生命周期。下面是提交要在Pulsar集群中运行的一个Pulsar函数的示例:
$ bin/pulsar-admin functions create \
--inputs persistent://sample/standalone/ns1/test_src \
--output persistent://sample/standalone/ns1/test_result \
--jar examples/api-examples.jar \
--className org.apache.pulsar.functions.api.examples.ExclamationFunction \
--name myFunction- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
另一种选择是将函数的整个配置放置在一个YAML文件中,如下所示:
inputs: persistent://sample/standalone/ns1/test_src
output: persistent://sample/standalone/ns1/test_result
jar: examples/api-examples.jar
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
name: myFunction- 1.
- 2.
- 3.
- 4.
- 5.
如果开发者选择通过YAML方式配置一个函数的话,则可以使用更简单的create命令:
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
name: myFunction- 1.
- 2.
如果开发者选择通过YAML方式配置一个函数的话,则可以使用更简单的create命令:
Pulsar函数提供以下功能,可针对不同的函数进行专门的指定:
1.最多一次(最多一次)
2.至少一次(至少一次)
3.有效一次(有效一次)
其中,有效的一次(Effective once)处理是通过将至少一次(A这意味着,状态更新可以发生两次,但状态更新只能应用一次,而任何重复的状态都会在服务器端被丢弃。
小结
通过本文的介绍,我希望能够激起读者对Pulsar函数的兴趣。此外,本文还向读者展示了Pulsar函数的扩展功能:如何允许开发者将Pulsar用作处理数据流的统一系统。
当然,Pulsar函数还蕴藏着更多的能力和可能性:读者可以在Apache Pulsar网站上了解到更多有关Pulsar函数的信息。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成 ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
参考链接:
https://dzone.com/articles/an-introduction-to-stream-processing-with-pulsar-f