译者 | 朱先忠
审校 | 孙淑娟
当前,数据领域的挑战不再是海量数据的处理能力。现代流媒体平台的高性能以及新一代数据存储允许将计算与存储层分离,使得我们可以通过非常低的操作工作量来提高系统的可伸缩性。
如果我们还记得著名的大数据“五V”(容量、价值、多样性、速度和准确性,即“Volume, Value, Variety, Velocity, and Veracity”)的话,那么,我们今天应该更清醒地认识到,准确性和价值对于今天的大多数公司来说仍然是一个挑战。
数据管道是解决这一挑战的基础。大规模设计和构建数据管道不仅可以提高系统的开发速度,而且可以让整个团队都可以参与维护和理解。
数据卷的处理能力
几年前,大数据领域面临的技术挑战主要表现在以下领域:
- 数据存储仓库(体积和速度方面):接收和管理大量数据。
- 数据处理计算层(速度方面):需要高性能计算层来启动数千条数据管道,允许以非常快速的方式接收大量数据。
- 集成适配器(类型方面):开发适配器以与不同类型的数据库组件集成。
IT团队在开始开发第一条数据管道之前,往往耗费数年时间构建支持这些功能的数据平台。之后,所有的努力都集中于在短时间内接收大量的数据。但这一切都发生在没有关注真实商业价值的情况下。此外,操作这些数据平台往往需要付出巨大的努力。
现在,随着云技术方案的应用——开源社区、最新一代云软件和新的数据架构模式的出现等,实现上述这些功能不再成为一种挑战。
数据存储仓库
当前,已经存在多种方法可以提供高性能数据存储库,以便以低操作工作量实时管理大量数据。
n 数据仓库:新一代数据仓库将存储层与计算层分离,并提供基于不同技术的新的可扩展功能,如NoSQL、数据湖或具有AI功能的关系数据仓库。
- 关系数据库:使用分片和内存功能的最新关系数据库,提供OLTP和OLAP功能。
- 流媒体平台:Apache Kafka或Apache Pulsar等平台,能够提供每秒处理数百万个事件的能力,并支持构建实时管道。
在这种情况下,成功的关键是为企业的应用场景选择最佳方案的问题。
计算层
当前计算层能够提供以下功能,以支持执行大量并发管道:
- 无服务器:云平台提供了简单的按需扩展。
- 新数据存储库的计算层:与存储分离,允许在数据库上执行大部分操作,而不会像旧的内部部署系统那样影响其他负载或扩展限制。
- Kubernetes:我们可以使用Kubernetes API动态创建作业容器作为Kubernetes Pods。
集成适配器
开源社区与新的云软件供应商一起,提供了各种数据适配器来快速提取和加载数据。这简化了不同软件组件(如数据存储库、ERP和许多其他组件)之间的集成。
当前面临的数据挑战
大数据公司当前面临的关键挑战是如何以更全面和可靠的方式提供数据。数据处理是复杂性的主要因素之一。作为数据或业务分析师,除了在正确的时间获得信息外,我们还需要了解所分析数据的元数据,以便做出决策。
- 这些数据意味着什么?它提供了什么数值?(数值方面)
- 如何计算数据?(数值方面)
- 数据的来源是什么?(数值方面)
- 数据的更新程度如何?(准确性方面)
- 数据的质量如何?(准确性方面)
在大型企业中,存在很多数据,但也有很多部门有时使用相似但不同的数据。例如,零售公司有两种类型的库存:
- 额定库存:该库存是理论库存,基于采购订单和交货单。
- 真实库存:此库存代表他们在仓库和商店中拥有的物品。
通常,由于递送延迟或其他人为错误等多方面的原因,这两种数值并不匹配。但是,库存数据是计算例如销售、销售预测或库存补充等指标的主要依据。根据理论库存购买新货物的决定可能会给公司造成数千美元的损失,并导致一种不可持续的状况。但事实情况是,我们只能想象这些决定对其他部门(例如库存健康度)的影响。
当分析师做出决策时,他们需要知道他们正在使用哪些数据来评估风险并做出有意识的选择。接下来,我们讨论的是如何将数据转换为业务价值的问题。
数据管道扮演什么角色?
当我们坐在办公室想象数据(或者阅读高级文章)时,我们常常想到的只是一个其中包含几个数据域的非常简单的世界:
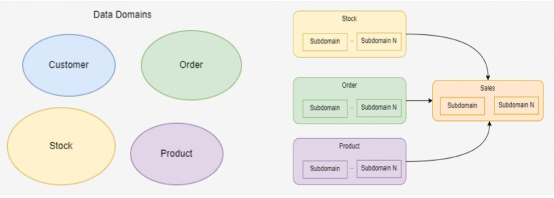
但现实情况往往远比上面的情形更为复杂:
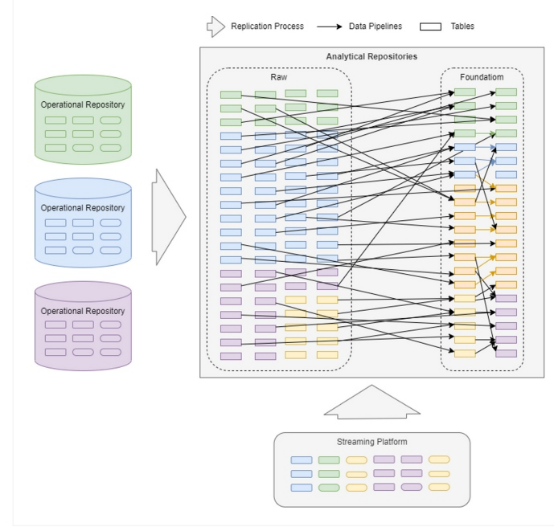
在大数据场景中,有数千条不同级别的数据管道在数据域或数据存储库之间不断摄取和整合数据。数据管道是提供成功数据平台的最重要组成部分之一;但是,即使在今天,我们在大规模构建数据管道方面也面临着与多年前相同的挑战,这体现在:
- 以动态和灵活的方式提供元数据,如历史数据沿袭
- 实现数据分析师、数据工程师和公司股东之间的轻松协作
- 轻松向数据分析师和利益相关者提供有关数据质量和新鲜度的信息
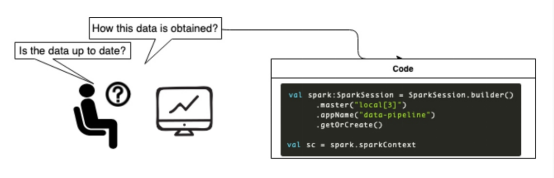
大规模构建数据管道的挑战是什么?
数据管道的目标主要集中在以下四个领域:
- 团队协作和理解
- 动态数据沿袭
- 可观测性
- 数据质量
团队协作和理解
规则变化很快,公司必须快速适应。数据和信息比以往任何时候都更加重要。
为了快速提供价值,我们需要一个由数据科学家、数据工程师、分析师和公司股东组成的异构团队共同工作。他们需要使用一种类似的语言才能变得更为敏捷。当我们所有的数据管道都使用Spark或Kafka Streams等技术构建时,技术人员和非技术人员之间的敏捷通信就太复杂了。
从数据到信息的旅程始于数据管道。
数据沿袭
元数据对于将数据转换为业务信息非常重要。它提供了每个人都可以访问的摘要沿袭,提高了数据的可见性、理解力和信心。我们必须动态提供这些信息,而不是通过永不改变的静态文档或永久持续的复杂检查过程。
可观测性
数据管道的可观测性是一个重大挑战。通常,可观察性面向技术团队,但我们需要提高所有利益相关者(业务分析师、数据分析师、数据科学家等)的可视性。
数据质量
我们需要改进我们处理数据的方式,并开始应用传统软件开发的最佳实践。从数据到作为代码的数据,我们可以借助版本控制、持续集成或测试等方法实现。
数据管道是如何发展的?
当我们研究新的数据技术趋势时,我们可以观察到存在于开源社区或商业软件初创公司(如Airbyte、Meltano、dbt labs、DataHub或OpenLineage)中的一些积极举措。
上面这些应用案例显示了数据处理领域如何演变为:
- 利用新的数据存储库增强功能,从ETL(提取、转换、加载)模型过渡到ELT(提取、加载、转换)模型
- 提供以代码形式管理数据的功能
- 提高数据理解和可观察性
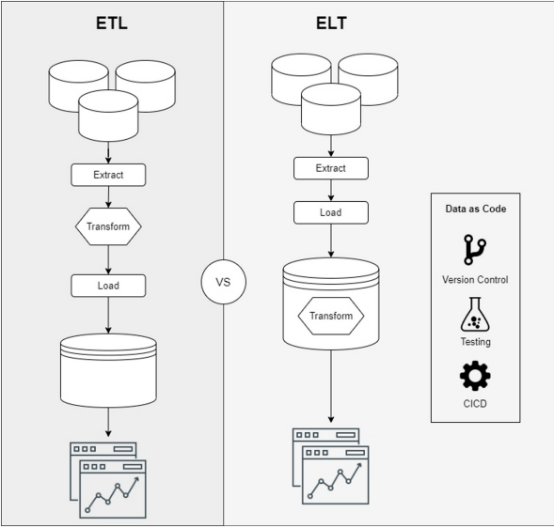
上述功能是使我们能够大规模构建数据管道并提供业务价值的关键。
从数据准备到数据理解的历程
理解是将数据转化为信息的第一步。转换层在这个过程中起着关键作用。通常,转换层是瓶颈,因为数据工程师和业务分析师的语言不同,所以协作很复杂。然而,诸如dbt之类的新工具正试图改进这一点。
什么是dbt?
dbt(数据构建工具,即“Data Build Tool”)是一种用于转换层的开源CLI工具,它支持业务数据分析师和工程师在数据生命周期中使用通用语言以及软件开发最佳实践(如版本控制、连续集成/部署和连续测试)进行协作。
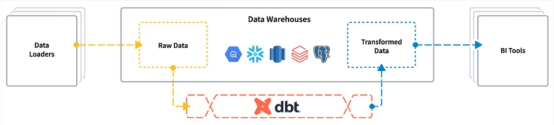
公司范围内的通用语言
SQL是公司的通用语言,允许所有利益相关者在整个数据生命周期中参与讨论。SQL使数据和业务分析师能够使用版本控制工具通过SQL语句协作编写或修改转换。
ELT(提取、加载、转换)
数据世界发生了很大变化。目前,大多数数据存储库都具有良好的性能和可扩展性。而且,新的场景改变了转换过程的规则。在许多情况下,数据存储库比外部流程更适合工作。dbt执行ELT过程的转换,利用新数据存储库的功能并在数据仓库中运行数据转换查询。
数据作为代码
dbt允许在Git存储库中以代码的形式管理数据转换,并应用持续集成最佳实践。它提供了测试功能,包括基于SQL查询的单元测试模块,或使用宏对其进行扩展,以增加更复杂场景中的覆盖率。
沿袭和元数据
dbt允许我们在每次运行数据转换时动态生成数据沿袭和元数据。如今存在许多成熟的平台(例如阿里云的DataHub或Datakin的OpenLineage)能够与企业的业务进行集成,而且这些平台都提供了丰富的企业可见性支持。
结论
近年来,很多大数据公司在提高数据处理性能和摄取能力方面都投入了大量精力,但质量和理解仍然是导致决策艰难的问题领域。如果我们不理解大量数据,或者数据质量很差,那么我们很快就会收到大量无关的数据。然而,为了提供增加业务价值的信息,必须有一层可扩展、可维护和可理解的数据管道。
请牢记:不做决定比根据不准确的数据做决定更好——尤其是当你没有意识到数据是错误的时候。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
原文标题:Challenges to Designing Data Pipelines at Scale,作者:Miguel Garcia