目前随着微服务化建设的普及,存在越来越多的跨系统数据交互情况,跨系统数据一致性问题越发凸显,那如何有效保证跨系统数据的一致性呢?
本文旨在总结沉淀工作中问题的解决经验,整理解决跨系统数据不一致问题的经验方法。
1、为什么会有跨系统数据一致性问题?
提到数据一致性,我们很容易想到的就是数据库中的事务操作。
事务的原子性和持久性可以确保在一个事务内,操作多条数据,要么都成功,要么都失败。这样在一个系统内部,我们可以很自然地使用数据库事务来保证数据一致性。但是在微服务的今天,一项操作会涉及到跨多个系统多个数据库的时候,用单一的数据库事务就没办法解决了。
另外常见的一种情况就是:存在依赖情况的系统服务,例如业务端与用户端(业务端负责生产数据,用户端负责展示数据),需要数据同步来保障跨系统服务的数据一致性,很多时候采用何种数据同步方式,来保障数据应用的时效性至关重要。
2、一致性问题的难点分析
为了更好的描述和理解问题,我们用一个案例来阐述:
假设存在订单系统与库存系统,在实际业务中订单的创建会伴随着库存的减少。两个系统为微服务化部署,其应用数据也存放在独立的数据库中,两个系统间通过网络进行通信。
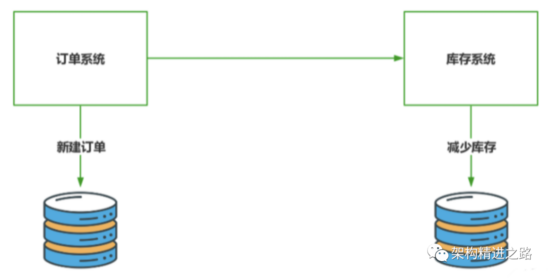
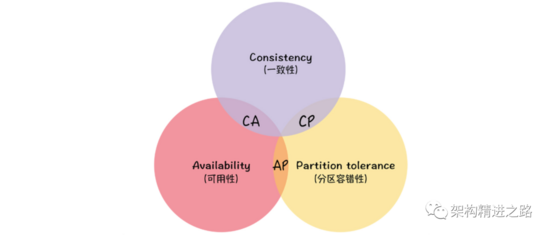
2.1 CAP 原则
CAP 指的是 Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性)。
放弃 A (可用性)来保障 CP
具体表现为产生通信故障后,应用会进入阻塞状态,一直尝试与库存系统恢复通信直到完成所有数据处理。这种方案是优先保障数据完整性,但此方案用户体验极差,因为在所有操作完成前用户会一直处于等待的状态。
CAP 本身就是互斥的,只能从三者中选两个,对于 CA、AP、CP 都有它们自己的应用场景,要结合实际进行选择。
CA 因为不考虑分区容忍度,所以它的所有操作需要在同一进程内完成(也就是我们常说的单体应用);
AP 因为放弃数据一致性,适合数据要求不高但强调用户体验的项目,如博客、新闻资讯等;
CP 反之放弃了可用性,适合数据要求很高的交易系统,如银行交易、电商的订单交易等,就算是用户长时间等待,也要保障数据的完整可靠。
CAP 原则在实际项目中的运用,对于互联网应用来说,如果为了用户体验完全放弃数据一致性这也是不可取的,毕竟数据才是应用的根本。
那该怎么解决呢?
保障最终一致性的措施有很多,主要包括: 分布式事务和 TCC 一致性方案 。
MySQL 其实有一个两阶段提交的分布式事务方案(MySQL XA),但是该方案存在严重的性能问题。
比如,一个数据库的事务与多个数据库之间的 XA 事务性能可能相差 10 倍。另外,在 XA 的事务处理过程中它会长期占用锁资源,所以一开始我们并不考虑这个方案。
在此,我们主要讨论一下 TCC 一致性方案。
2.2 TCC 一致性方案
TCC 是一种数据一致性方案,我们会把原来的一个接口分为三个接口:
- Try 接口用来检查数据、预留业务资源。
- Confirm 接口用来确认实际业务操作、更新业务资源。
- Cancel 接口是指释放 Try 接口中预留的资源。
在 TCC 中,它将分布式处理过程分为两个阶段:
1、Try 是第一个阶段,用于尝试并锁定资源;
2、如果资源锁定成功,第二个阶段开始进行 Confirm 提交完成数据操作;
3、如果资源锁定失败,第二个阶段就会进行 Cancel 将数据回滚;
TCC 实施过程中有哪些注意事项呢?
1)在 Try 阶段做尽可能多的事情
要把绝大多数的业务逻辑在 Try 阶段完成,因为 TCC 设计之初认为 Confirm 或 Cancel 是一定要成功的,因此不要二阶段包含任何业务代码或者远程通信,只通过最简单的代码释放冻结资源。
2)保障 Confirm 或 Cancel 执行成功
假如 Confirm 或 Cancel 执行时出现错误,那具体应用时也会不断重试执行操作来尽量保证执行成功,这个过程中可能会多次执行 update 语句,因此要注意代码的幂等性。
3)Confirm 或 Cancel 执行失败的兜底方案
极小概率下,Confim 或 Cancel 在多次重试后宣告失败,便会出现数据最终不一致的情况,这就需要自己开发额外的数据完整性校验程序补救或者通过人工进行补录。
TCC 归根结底是一种理论设计,需要厂商实现相应的框架给予支撑。
在 Java 开源领域著名的 TCC 框架有:ByteTCC、Hmily、Tcc-transaction 与 Seata。
3、有效数据同步方案实践
问题描述:我们还是以之前的案例场景,数据需要从订单系统同步到库存系统中。
解决数据一致性常用的三类数据同步方案: 实时同步、定时同步、手动同步 。
3.1 实时同步
实时同步可以从数据库、应用处理两个层面来解决。
3.1.1 数据库层面
通用采用数据库的数据同步,主从解决,当 master(主)库的数据发生变化的时候,变化会实时的同步到 slave(从)库。
优势:
- 水平扩展数据库的负载能力。
- 容错,高可用,Failover(失败切换)/High Availability
- 数据备份。
如何实现主从一致
关于 MySQL 主从复制主要同步的是 binlog 日志,涉及到三个线程,一个运行在主节点(log dump thread),其余两个(I/O thread, SQL thread)运行在从节点,如下图所示:
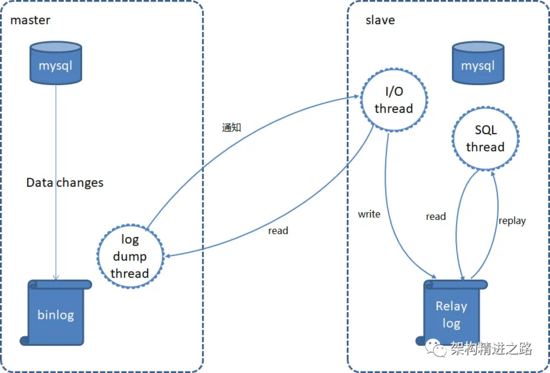
(1)主节点 binary log dump 线程
当从节点连接主节点时,主节点会创建一个 log dump 线程,用于发送 binlog 的内容。在读取 binlog 中的操作时,此线程会对主节点上的 binlog 加锁,当读取完成,在发送给从节点之前,锁会被释放。
(2)从节点 I/O 线程
当从节点上执行 start slave 命令之后,从节点会创建一个 I/O 线程用来连接主节点,请求主库中更新的 binlog。I/O 线程接收到主节点 binlog dump 进程发来的更新之后,保存在本地 relay-log(中继日志)中。
(3)从节点 SQL 线程
SQL 线程负责读取 relay log 中的内容,解析成具体的操作并执行,最终保证主从数据的一致性。
3.1.2 API 调用
一次业务数据操作,需要调用多方 API 实现实时数据的同步。
劣势比较明显,主要表现在:
1)处理耗时长,需要串行调用多方 API 并等待响应,用户体验较差;
2)会有一定几率出现数据不一致情况(个别 API 调用出错、未响应等情况)。
3.2 异步同步
3.2.1 异步消息队列
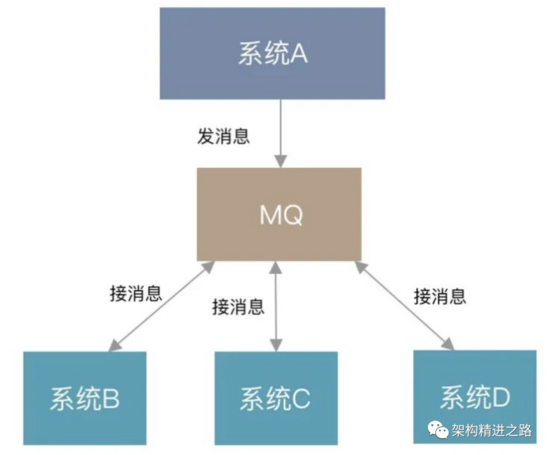
Message Queue(MQ),消息队列中间件
MQ 通过将消息的发送和接收分离来实现应用程序的异步和解偶,同时 MQ 屏蔽底层复杂的通讯协议,定义了一套应用层的、更加简单的通讯协议。
应用 MQ 的优点:解耦,削峰,数据分发。
在业务系统设计中,我们常常会存在一个平台系统 A,它关联同步了许许多多的系统的对接(系统 B、C、D 等)。
利用 MQ 可以很好的解决系统对接和数据同步问题,同时可以忽略对接系统的稳定性等诉求。
3.2.2 定时同步
定时任务在系统中并不少见,主要目的是用于需要定时处理数据或者执行某个操作的情况下,如定时关闭订单,或者定时备份。
常见的定时任务分为 2 种:
1)第一种:固定时间执行,保障同步并校准数据
如:每分钟执行一次,每天执行一次。
2)第二种:延时多久执行,即动作发生后,定时多久后执行任务
如:15 分钟后关闭订单付款状态,24 小时候后关闭订单并且释放库存等。
4、应用经验总结
技术还是要解决实际问题来落地的,应用场景很关键,不要单纯为了技术而技术,技术归根结底还是为应用场景和产业落地服务。
软件设计过程中,不需要刻意去应用看起来高大上的解决方案,而当需要引入时,要同时考虑开发、维护成本以及对应性能的提升的性价比,否则得不偿失。
(1)任何架构方案都是不断演进的
任何数据同步本身没有优劣之分,都有其适合的应用场景。
(2)架构的目的是解决业务问题
能够解决当前问题的架构方案,同时兼具易于扩展及维护,那就是一个优秀的架构。
随着互联网的告诉发展,跨系统数据一致性应用需求一定会越来越迫切,跨地域跨系统场景的真正痛点也会越来越清晰,希望我们在跨系统数据一致性方面的调研和探索可以给大家一个思路和参考。
希望今天的讲解对大家有所帮助,谢谢!