01引言
对大部分用户来说,为 Flink 算子配置合适的并行度并不是一件容易的事。对于批作业,小的并行度会导致作业运行时间长,故障恢复慢,而不必要的大并行度会导致资源浪费,任务部署和数据 shuffle 开销也会变大。
为了控制批作业的执行时长,算子的并行度应该和其需要处理的数据量成正比。用户需要通过预估算子需要处理的数据量来配置并行度。但准确预估算子需要处理的数据量是一件很困难的事情:需要处理的数据量可能每天都在变化,作业中可能会存在大量的 UDF 和复杂算子导致难以判断其产出的数据量。
为了解决这个问题,我们在 Flink 1.15 中引入了一种新的调度器:自适应批作业调度器(Adaptive Batch Scheduler)。自适应批作业调度器会在作业运行时根据每个算子需要处理的实际数据量来自动推导并行度。它会带来以下好处:
- 大大降低批处理作业并发度调优的繁琐程度;
- 可以根据处理的数据量为不同的算子配置不同的并行度,这对于之前只能配置全局并行度的 SQL 作业尤其有益;
- 可以更好的适应每日变化的数据量。
02用法
使 Flink 自动推导算子的并行度,需要进行以下配置:
- 启用自适应批作业调度器;
- 配置算子的并行度为 -1。
2.1 启用自适应批作业调度器
启用自适应批作业调度器,需要进行以下配置:
- 配置 jobmanager.scheduler: AdaptiveBatch;
- 将 execution.batch-shuffle-mode 配置为 ALL-EXCHANGES-BLOCKING (默认值)。因为目前自适应批作业调度器只支持 shuffle mode 为 ALL-EXCHANGES-BLOCKING 的作业。
此外,还有一些相关配置来指定自动推导的算子并行度的上下限、预期每个算子处理的数据量以及 source 算子的默认并行度,详情请参阅 Flink 文档 [1]。
2.2 配置算子的并行度为 -1
自适应批作业调度器只会为用户未指定并行度的算子(即并行度为默认值 -1)推导并行度。所以需要进行以下配置:
- 配置 parallelism.default: -1;
- 对于 SQL 作业,需要配置 table.exec.resource.default-parallelism: -1;
- 对于 DataStream/DataSet 作业,避免在作业中通过算子的 setParallelism() 方法来指定并行度;
- 对于 DataStream/DataSet 作业,避免在作业中通过 StreamExecutionEnvironment/ExecutionEnvironment 的 setParallelism() 方法来指定并行度。
03实现细节
接下来我们将介绍自适应批作业调度器的实现细节。在此之前,我们简要介绍一下涉及到的一些术语概念:
- 逻辑节点(JobVertex)[2] 和逻辑拓扑(JobGraph)[3]:逻辑节点是为了更优的性能而将几个算子链接到一起形成的算子链,逻辑拓扑则是多个逻辑节点连接组成的数据流图。
- 执行节点(ExecutionVertex)[4] 和执行拓扑(ExecutionGraph)[5]:执行节点对应一个可部署物理任务,是逻辑节点根据并行度进行展开生成的。例如,如果一个逻辑节点的并行度为 100,就会生成 100 个对应的执行节点。执行拓扑则是所有执行节点连接组成的物理执行图。
以上概念的介绍可以参见 Flink 文档 [6]。需要注意的是,自适应批作业调度器是通过推导逻辑节点的并行度来决定该节点包含的算子的并行度的。
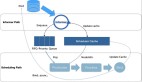
实现细节主要包括以下几部分:
- 使调度器能够收集执行节点产出数据的大小;
- 引入一个新组件 VertexParallelismDecider [7] 来负责根据逻辑节点需要处理的数据量计算其并行度;
- 支持动态构建执行拓扑,即执行拓扑从一个空的执行拓扑开始,然后随着作业调度逐渐添加执行节点;
- 引入自适应批作业调度器来更新和调度执行拓扑。
后续章节会对以上内容进行详细介绍。

图 1 - 自动推导并行度的整体结构
3.1 收集执行节点产出的数据量
自适应批作业调度器是根据逻辑节点需要处理的数据量来决定其并行度的,因此需要收集上游节点产出的数据量。为此,我们引入了一个 numBytesProduced 计数器来记录每个执行节点产出的数据分区(ResultPartition)的数据量,并在执行节点运行完成时将累计值发送给调度器。
3.2 为逻辑节点决定合适的并行度
我们引入了一个新组件 VertexParallelismDecider 来负责为逻辑节点计算并行度。计算算法如下:
假设
- V 是用户配置的期望每个执行节点处理的数据量;
- totalBytenon-broadcast 是逻辑节点需要处理的非广播数据的总量;
- totalBytesbroadcast 是逻辑节点需要处理的广播数据的总量;
- maxBroadcastRatio 是每个执行节点处理的广播数据的比例上限;
- normalize(x) 是一个输出与 x 最接近的 2 的幂的函数。
计算并行度的公式如下:

值得注意的是,我们在这个公式中引入了两个特殊处理:
- 限制每个执行节点处理的广播数据的比例;
- 将并行度调整为 2 的幂。
此外,上述公式不能直接用来决定 source 节点的并行度,因为 source 节点不会消费数据。为了解决这个问题,我们引入了配置选项 jobmanager.adaptive-batch-scheduler.default-source-parallelism,允许用户手动配置 source 节点的并行度。请注意,并非所有 source 都需要此选项,因为某些 source 可以自己推导并行度(例如,HiveTableSource,详情请参阅 HiveParallelismInference),对于这些source,更推荐由它们自己推导并行度。
3.2.1 限制每个执行节点处理的广播数据的比例
我们在公式限制每个执行节点处理的广播数据上限比例为 maxBroadcastRatio。 即每个执行节点处理的非广播数据至少为 (1-maxBroadcastRatio) * V。如果不这样做,当广播数据的数据量接近 V 时,即使非广播数据的量非常小,也可能会被计算出很大的并行度,这是不必要的,会导致资源浪费和任务部署的开销变大。
通常情况下,一个执行节点需要处理的广播数据量会小于要处理的非广播数据。 因此,我们将 maxBroadcastRatio 默认设置为 0.5。目前,这个值是硬编码在代码中的,我们后续会考虑将其改为可配置的。
3.2.2 将并行度调整为 2 的幂
normalize 函数会将并行度调整为最近的 2 的幂,这样做是为了避免引入数据倾斜。为了更好的理解本节,我们建议您先阅读子分区动态映射部分。
以图 4(b)为例,A1/A2 产生 4 个子分区,B 最终被决定的并行度为 3。这种情况下,B1 将消费 1 个子分区,B2 将消费 1 个子分区,B3 将消费 2 个子分区。我们假设不同子分区的数据量都相同,这样 B3 需要消费的数据量是 B1/B2 的 2 倍,从而导致了数据倾斜。
为了解决这个问题,我们需要让所有下游执行节点消费的子分区数量都一样,也就是说上游产出的子分区数量应该是下游逻辑节点并行度的整数倍。为简单起见,我们希望用户指定的最大并行度为 2^N(如果不是则会被自动调整到不超过配置值的 2^N),然后将下游逻辑节点的并行度调整到最接近的 2^M(M <= N),这样就可以保证子分区被下游均匀消费。
不过这只是一个临时的解决方案,最终应该通过自动负载均衡来解决,我们将在后续版本中实现。
3.3 动态构建执行拓扑
在引入自适应批作业调度器之前,执行拓扑是以静态方式构建的,也就是在调度开始前执行拓扑就被完全创建出来了。为了使逻辑节点并行度可以在运行时决定,执行拓扑需要支持动态构建。
3.3.1 向执行拓扑动态添加节点和边
动态构建执行拓扑是指一个 Flink 作业从一个空的执行拓扑开始,然后随着调度逐步附加执行节点,如图 2 所示。
执行拓扑由执行节点和执行边(ExecutionEdge)组成。只有在以下情况下,才会将逻辑节点展开创建执行节点并将其添加到执行拓扑:
- 对应逻辑节点的并行度已经被确定(以便 Flink 知道应该创建多少个执行节点);
- 所有上游逻辑节点都已经被展开(以便 Flink 通过执行边将新创建的执行节点和上游执行节点连接起来)。

图 2 - 动态构建执行拓扑
3.3.2 子分区动态映射
在引入自适应批作业调度器之前,在部署执行节点时,Flink 需要知道其下游逻辑节点的并行度。因为下游逻辑节点的并行度决定了上游执行节点需要产出的子分区数量。以图 3 为例,下游 B 的并行度为 2,因此上游的 A1/A2 需要产生 2 个子分区,索引为 0 的子分区被 B1 消费,索引为 1 的子分区被 B2 消费。

图 3 - 静态执行拓扑消费子分区的方式
但显然,这不适用于动态图,因为当部署上游执行节点时,下游逻辑节点的并行度可能尚未确定(即部署 A1/A2 时,B 的并行度还未确定)。为了解决这个问题,我们需要使上游执行节点产生的子分区数量与下游逻辑节点的并行度解耦。
我们通过以下方法实现解耦:将上游执行节点产生子分区的数量设置为下游逻辑节点的最大并行度(最大并行度是一个可配置的固定值),然后在下游逻辑节点并行度被确定后,将这些子分区均分给不同的下游执行节点进行消费。也就是说,部署下游执行节点时,每个下游执行节点都会被分配到一个子分区范围来消费。假设 N 是下游逻辑节点并行度,P 是子分区的数量。对于第 k 个下游执行节点,消费的子分区范围应该是:

以图 4 为例,B 的最大并行度为 4,因此 A1/A2 有 4 个子分区。然后如果B的确定并行度为 2,则子分区映射将为图 4(a),如果B的确定并行度为 3,则子分区映射将为图 4(b)。

图 4 - 动态执行拓扑消费子分区的方式
3.4 动态更新并调度执行拓扑
自适应批作业调度器调度作业的方式和默认调度器基本相同,唯一的区别是:自适应批作业调度器是从一个空的执行拓扑开始调度,在处理任何调度事件之前,都会尝试决定所有逻辑节点的并行度,然后尝试为逻辑节点生成对应的执行节点,并通过执行边连接上游节点,更新执行拓扑。
调度器会在每次调度之前尝试按照拓扑顺序决定所有逻辑节点的并行度:
- 对于 source 节点,其并行度会在开始调度之前就进行确定;
- 对于非 source 节点,需要在其所有上游节点数据产出完成后才能确定其并行度。
然后,调度程序将尝试按照拓扑顺序将逻辑节点展开生成执行节点。一个可以被展开的逻辑节点应该满足以下条件:
- 该逻辑节点并行度已确定;
- 所有上游逻辑节点都已经被展开。
04未来展望 - 自动负载均衡
运行批作业时,可能会出现数据倾斜(某个执行节点需要处理的数据远多于其他执行节点),这会导作业出现长尾现象,拖慢作业的完成速度。如果 Flink 可以自动改善或者解决这个问题,可以给用户很大的帮助。
一种典型的数据倾斜情况是某些子分区的数据量明显大于其他子分区。这种情况可以通过划分更细粒度的子分区,并根据子分区大小来平衡工作负载来解决(如图 5)。自适应批作业调度器的工作可以被认为是迈向它的第一步,因为自动重新平衡的要求类似于自适应批作业调度器,它们都需要动态图的支持和结果分区大小的采集。
基于自适应批作业调度器的实现,我们可以通过增加最大并行度(为了更细粒度的子分区)和简单地更改子分区范围划分算法(为了平衡工作负载)来解决上述问题。在目前的设计中,子分区范围是按照子分区的个数来划分的,我们可以改成按照子分区中的数据量来划分,这样每个子分区范围内的数据量可以大致相同,从而平衡下游执行节点的工作量。

图 5 - 自动负载均衡
注释
[1] https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/deployment/elastic_scaling/#adaptive-batch-scheduler
[2] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/JobVertex.java
[3] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/JobGraph.java
[4] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionVertex.java
[5] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionGraph.java
[6] https://nightlies.apache.org/flink/flink-docs-master/zh/docs/internals/job_scheduling/#jobmanager-数据结构
[7] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/scheduler/adaptivebatch/VertexParallelismDecider.java