作者 | 孙越,单位:中移(杭州)信息技术有限公司 | 中国移动杭州研发中心
Labs 导读
随着5G网络的不断普及,大量用户开始接触并使用5G网络。5G网络不仅可以传送传统网络的语音、视频、文本等信息,还可以凭借更加低时延及高精准的定位能力,被使用在更多具有实用价值的应用场景中,如:战地实况信息、卫星定位导航等等。
网络信息时常会夹杂不良信息,如涉政信息、涉黄信息、涉黑信息、涉诈信息、商业广告消息等,且不良信息数量呈现逐年上升趋势,给用户造成了巨大骚扰。为了净化网络环境,有效管控不良信息传播,中国移动5G不良消息安全管控平台应运而生。

数据来源:中国移动集团信息安全中心
1、5G不良信息管控平台的应用场景
该平台在面对繁杂的网络信息环境时,诸如文本消息、语音信息、视频信息、富媒体信息等,将信息归类为:涉政、涉黄、涉黑、涉诈、商业广告消息、正常消息等等,再通过对应策略进行及时拦截,并根据不良消息的严重程度进行后续惩处处理,从根源净化网络环境,营造良好的网络空间。

2、现有5G不良信息管控平台的技术要点
该平台主要通过以下几种方法对不良信息进行拦截:
①设定一级关键词:一级关键词通常设置为一些极度敏感词汇,若用户发送信息中包含一级关键词内容,即立即拦截该信息,信息内容无法下发,并对该用户进行标记。
②设定普通关键词: 普通关键词设置为一些较为敏感词汇,若用户发送信息中包含普通关键词内容,且在一定时间内,用户发送该敏感消息的次数超过系统预先设定的拦截阈值,则系统会将用户拉入黑名单,在一定时间内,该用户无法使用完整5G网络服务。
③设定复杂文本信息监控:如用户发送PDF文件,其中该文件中包含文字和图片,将文件中文字提取出来,过滤一级关键词和普通关键词机制,图片则进行富媒体机制过滤,分别根据文本和图片的过滤结果,采用从重处置的原则,作为该文件的处置结果。
3、现有5G不良管控平台的技术弱点
现有5G不良消息安全管控平台的过滤机制仅能过滤指定且有限的短语、短句,而随着网络普及,新鲜词汇每天都会大量涌现,仅靠人工手动添加词汇,已经无法做到及时、快速的更新词汇库。而且当今大量用户在发送文本信息时,虽然整个文本信息没有违规词汇,但表达的思想及情感却可能带有大量不良情感倾向,仅靠词汇及短句无法成功拦截不良情感内容。因此,利用文本情感分析,将富含不良情感倾向的句子进行送审拦截,可以进一步加强不良信息管控的效果,减少垃圾信息对用户的侵蚀与毒害。
通过建立包含网络流行短句及新闻消息的文本情感库,将文本中富含的情感分为三类:积极情感、中性情感、消极情感,并按照这三种分类对每一个文本加上相应标签,利用深度学习网络对情感库中文本进行训练,便可将训练好的模型用在5G不良消息管控平台中对不良情感消息进行拦截。
4、基于深度学习的5G不良管控系统技术实现细节
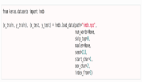
该技术中包含三大主体:jieba分词系统、词组向量化,文本情感识别算法,各个主体之间的交互如下图:

各模块交互流程图
通过爬虫技术爬取网络词语及新闻消息作为原始文本,并将原始文本按照8:2的比例分为训练集和测试集,对训练集中的文本信息进行标签化,然后将测试集中文本信息通过jieba分词工具进行分词处理,比如:他来到移动杭研大厦。通过jieba分词工具分词后,结果为:他/来到/移动/杭研/大厦,最后将分词后数据组建成语料库。由于训练集和测试集文本信息量很大(通常在百万级数据),所以会导致分词后语料库中的数据量也十分庞大(千万级数据量)。虽然可以将这些语料以编号的形式储存在语料库中,但由于数据量庞大,极易出现维度灾难。因此,针对文本信息中出现的语气助词,比如:“了”、“的”、“吗”等等,这些词虽然出现十分频繁,但对情感作用几乎没有贡献,我们会选择在语料库中剔除这些词组,达到减少维度的目的。
我们将训练集中已经向量化的词组送入深度学习网络中进行学习训练,获取相应模型,最后将测试集中的数据放入到模型中查看对应的识别结果,当该模型能够获得较好的正确率时,该模型联接到5G不良管控平台,用户发送端到端的信息进行过滤。在过滤过程中,若发现不良信息及时进行拦截,使5G不良信息管控系统对于不良信息的拦截更加系统、全面。

具体步骤如下:
- 从网上爬取原始文本语料,并将原始文本进行预处理,包括:去除语气词,删除文本中出现的标点符号、空白区域,删除文本中出现的终止词、稀疏词和特定词;使用jieba库进行分词,将文本句子按照词组精确地切开,分成一个一个单独的词组;
- 将爬取到的文本数据集按照一定比例划分成训练集和测试集,对训练集中文本句子进行人工标注,分为:积极情感、消极情感、中性情感。并分别使用jieba库对训练集和测试集内文本句子进行分词,将分词后的训练集构建成语料库;
- 将步骤1中词组进行向量化,让每一个分词映射为一个多维的连续值向量,得到整个数据集的词向量矩阵。
- 通过先抽取情感词所在的子句,减少句子的复杂度,再在子句中根据各种特征预测情感对象的位置,然后再从相应位置进行情感抽取。情感抽取是为了获取文本中有价值的情感信息,判断一个单词或词组在情感表达中扮演的角色,包括情感表达者识别、评价对象识别、情感观点词识别等任务。
- 通过将上述操作获得的情感向量送入到深度学习网络获得文本情感识别模型,再将测试集中情感向量送入该模型中,查看测试结果,并将检测结果正常的数据继续进行常规策略过滤,如:文本匹配、富媒体识别等。
5、融入深度学习的5G拦截系统的优点
与现有5G拦截系统相比,融入深度学习的5G拦截系统具有以下优点:
- 利用深度学习技术提供高可靠性、高真实性的有效鉴别;
- 利用深度学习技术进行情感识别,人工介入少,工作效率高;
- 利用文本情感识别,可有效补充关键词拦截的不足;
- 利用文本情感识别,可将在策略中及时自动更新补充新的词条信息,提高效率。
写在最后:
目前,深度学习应用领域十分广阔,依靠其重复训练、自我学习的方式,可以大大降低人工的工作量,提升效率及准确度。不仅适用于上述不良信息拦截系统,相信在不久的将来,该技术在其他新兴领域也会大放异彩。当然,深度学习本身也不尽完美,并不能解决所有棘手问题。正因为如此,我们应该继续将深度学习技术投入到新场景、新领域以期获得新突破,共创美好的未来智能生活。