一种快速、内存高效的注意力算法来了,被命名为 FlashAttention。通过减少 GPU 内存读取 / 写入,FlashAttention 的运行速度比 PyTorch 标准注意力快 2-4 倍,所需内存减少 5-20 倍。

这项研究由斯坦福大学、纽约州立大学布法罗分校的研究者共同完成。共同一作是两位斯坦福计算机博士生 Tri Dao 和 Dan Fu。
下面我们介绍一下论文具体内容。
FlashAttention
Transformer 已然成为自然语言处理和图像分类等应用中最广泛使用的架构。随着研究的不断前进,Transformer 尺寸变得越来越大、层数也越来越深,但是给 Transformer 配备更长的上下文仍然很困难,因为 Transformer 核心自注意力模块的时间复杂度以及内存复杂度在序列长度上是二次方的。
有研究者提出一些近似注意力的方法,旨在减少注意力计算和内存需求。这些方法包括稀疏近似、低秩近似以及它们的组合。从序列长度来看,尽管这些方法可以将计算降低到线性或接近线性,但它们并没有显示出针对标准注意力的 wall-clock 加速,因而没有被广泛使用。这其中一个主要原因是这些研究专注于减少 FLOP(这可能与 wall-clock 速度无关)并且倾向于忽略来自内存访问 (IO) 的开销。
在本文中,该研究认为应该让注意力算法具有 IO 感知——即考虑显存级间的读写。现代 GPU 计算速度超过了内存速度,transformer 中的大多数操作都被内存访问所阻塞。IO 感知算法对于类似的内存绑定操作至关重要,这种重要性体现在当读写数据占据很大运行时——例如数据库连接、图像处理、数值线性代数等。然而,用于深度学习的常见 Python 接口,如 PyTorch 和 Tensorflow,不允许对内存访问进行细粒度控制。

论文地址:https://arxiv.org/pdf/2205.14135.pdfGitHub 地址:https://github.com/HazyResearch/flash-attention
该研究提出了一种新的注意力算法 FlashAttention,它可以使用更少的内存访问来计算精确的注意力。FlashAttention 旨在避免从 HBM(High Bandwidth Memory)中读取和写入注意力矩阵。这需要做到:(i) 在不访问整个输入的情况下计算 softmax reduction;(ii) 在后向传播中不能存储中间注意力矩阵。
该研究采用两种成熟的技术来应对这些挑战:
(i) 该研究重组注意力计算,将输入分成块,并在输入块上进行多次传递,从而逐步执行 softmax reduction(也称为 tiling);(ii) 该研究存储前向传递的 softmax 归一化因子,在后向传播中快速重新计算片上注意力,这比从 HBM 中读取中间注意力矩阵的标准方法更快。
该研究在 CUDA 中实现 FlashAttention ,以达到对内存访问的细粒度控制,并将所有注意力操作融合到一个 GPU 内核中。即使由于重新计算导致 FLOPs 增加,但其运行速度更快(在 GPT-2 上高达 7.6 倍,图 1 右图)并且使用更少的内存(序列长度线性),主要是因为大大减少了 HBM 访问量。

该研究分析了 FlashAttention 的 IO 复杂度,证明它需要𝑂(𝑁^2𝑑^2^𝑀−1)HBM 访问,其中𝑑是 head 维度,𝑀是 SRAM 的大小,而标准的注意力需要Ω(𝑁𝑑 + 𝑁^2 )HBM 访问。对于𝑑 和 𝑀 的典型值,与标准注意力相比,FlashAttention 需要的 HBM 访问次数要少很多(最多减少 9 倍,如图 2 所示)。此外,该研究还提供了一个下限,表明没有精确的注意力算法可以渐近地提高所有 SRAM 大小的 HBM 访问次数。

该研究还表明,FlashAttention 可以作为一种原语(primitive),通过克服内存访问开销问题来实现近似注意力算法。作为概念证明,该研究实现了块稀疏 FlashAttention,这是一种稀疏注意力算法,比 FlashAttention 快 2-4 倍,可扩展到 64k 的序列长度。该研究证明了块稀疏 FlashAttention 比 FlashAttention 具有更好的 IO 复杂度。

值得一提的是,该研究还开源了 FlashAttention。
实验结果
BERT:FlashAttention 得到了最快的单节点 BERT 训练速度。该研究在 Wikipedia 上用 FlashAttention 训练了一个 BERT-large 模型。表 1 将 FlashAttention 训练时间与 Nvidia MLPerf 1.1 进行了比较,结果表明 FlashAttention 的训练速度提高了 15%。

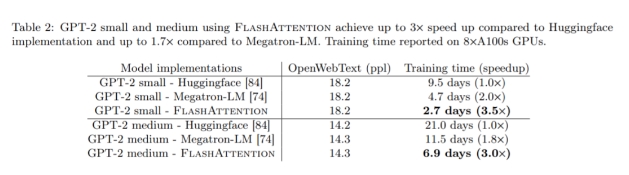
GPT-2:表 2 显示,与 HuggingFace 相比,FlashAttention 端到端加速可达 3 倍,与 Megatron-LM 相比,加速可达 1.7 倍

Long-range Arena:该研究在 long-range arena (LRA) 基准上进行了实验,他们测量了准确率、吞吐量、训练时间。每个任务有不同的序列长度,从 1024 到 4096 不等。此外,实验遵循 Tay 和 Xiong 等人的实验设置。表 3 显示,与标准注意力相比,FlashAttention 的速度提高了 2.4 倍。块稀疏 FlashAttention 比所有近似注意力方法都要快。

具有长上下文的语言模型:FlashAttention 的运行时间和内存效率允许我们将 GPT-2 的上下文长度增加 4 倍,同时仍然比 Megatron-LM 的运行更快。从表 4 可以看出,上下文长度为 4K 的 FlashAttention GPT-2 仍然比上下文长度为 1K 的 Megatron 的 GPT-2 快 30%,同时 perplexity 提高了 0.7。

表 5 表明,在 MIMIC 上序列长度为 16K 的性能比长度为 512 的高出 4.3 个点,而在 ECtHR 上,序列长度为 8K 的比长度 512 高出 8.5 个点。

表 6 展示了 Transformer 模型可以解决 Path-X、Path-256 问题。该研究在 Path-64 上预训练 transformer,然后通过空间插值位置嵌入迁移到 Path-X。FlashAttention 在 Path-X 上达到 61.4 的准确率。此外,块稀疏 FlashAttention 使得 Transformers 将序列扩展到 64K,在 Path-256 实现 63.1 的准确率。

图 3(左) 报告了以毫秒为单位的 FlashAttention 和块稀疏 FlashAttention 前向 + 后向传播的运行时间与基准比较,图 3(右) 显示了与各种精确、近似和稀疏注意基线相比,FlashAttention 和块稀疏 FlashAttention 的内存占用情况。