














你以为的随机数是不是都是那种很高级的?
比如前两天,区块链平台Solana出现了长达4个小时的宕机事件。
根据联合创始人Anatoly Yakovenko和其他开发人员表示,该问题是由于区块链的持久随机数功能存在错误导致的。Yakovenko表示,该问题“导致部分网络认为该区块无效”,因此“无法形成共识”。

再比如,在2015年与2017年,工行联合中国科技大学实现基于量子通信技术的同城和异地数据加密传输,在电子档案、网上银行等领域落地试点。去年,工行在银行业中率先完成了量子随机数的场景试点。
工行金融科技部总经理表示:“量子随机数被认为是安全性最高的随机数,我们利用其随机性、不可推测和不可重复的特点,运用量子随机数加密、标记、校验重要金融交易信息,以更有效地防范用户身份假冒、交易数据截获重放等攻击,更好地确保用户意愿的真实性、交易要素的完整性和交易过程的安全性。”
但是你可能想都想不到,要生成随机数,其实只要一根香蕉就够了。这个别出心裁的脑洞得到一位即将电子学硕士毕业的博主Valerio Nappi实践支持。
这个香蕉随机数生成器原理是啥?真的靠谱吗?快和文摘菌一起来看看~
让我们从问题的根源开始说起。
计算机是确定性的系统。换句话说,如果我们总是给它们相同的输入数据,它们也总是会返回相同的输出值。这正是我们对计算机的期望。然而,确定性和随机性并不是一种兼容的关系,而计算机本身无法做任何随机的事情。
为了更好地理解随机数,我们必须要理解一组数字成为随机数的两个必要不充分条件:
每个数字出现在列表中的概率必须与其他每个数字相同(取一个参考区间),也即均匀分布。
数字的序列必须是事先无法预测的。
显然,确定型机器的困难在于回答第2点。在只满足第1点的情况下,很有可能生成的是伪随机数,并非真正的随机。
但是,这和香蕉有什么关系?
当我们为计算机提供随机数时,硬件系统是必不可少的,这就是随机数生成器(TRNG)。
TRNG有许多类型,不过他们原理都是类似的,即利用不同的物理随机量并将其转换为数字信息传递给计算机。最常见的是利用物理现象,如电阻的热噪声、二极管的雪崩效应和其他混乱效应。
使用香蕉的话,应该还是放射性衰变。我们知道,香蕉内含有大量的钾,而自然界中存在的钾有一小部分是放射性的,但比例很高。具体来说,这里说的是40K同位素,它占自然界中钾的0.01%。(以及很搭配与柠檬和糖一起吃)

这么来看的话,“以香蕉为动力的随机数生成器”瞬间变得合理了不少。
但有一个问题仍然存在:我们在计算机中对随机数做什么?
——加密。这也是研究随机数及其与计算机关系的主要原因。随机数被用来生成加密密钥,这是决定加密系统有效性的唯一因素。正如Kerckhoffs原理所言,“一个密码系统的安全性不应取决于保持密码算法的隐蔽性,而只应取决于保持密钥的隐蔽性”。
很明显,如果攻击者能够以某种方式预测密钥,我们便会处在一个脆弱的系统中。因此,“好的随机数”是一个好的加密系统的基础。

要用什么来检测“香蕉”
为了分析随机数生成器的质量,我们还需要专门设计的软件工具。目前最流行的两个是ent和dieharder。ent是作为放射性衰变随机数生成器的轻量级测试而设计的,它非常简单和快速,需要的数据很少,但结果只是指示性的。Dieharder是一个被认为是随机数生成器的黄金标准的测试套件,它进行非常彻底的测试,但需要数千兆字节的样本来运行。
在这里我们当然选择ent。
准备一下数据,我们用ent进行第一次测试。数据是由发生器写入串口的,我们用cat /dev/ttyACM0 >> sampletext.txt从linux控制台将它们保存在一个文件中,在append模式下利用bash流重定向命令,这样我们就可以停止采集,以后再继续采集,而不会覆盖文件。
两天内收集的样本包括90628个16位数字,每行一个。这些数字被保存为ascii文本文件,但ent分析的是二进制文件,可以用C语言写一个很短的程序把它们转换成二进制。
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdint.h>
int main(int argc, char const *argv[]) {
FILE * lettura = fopen("textsample.txt", "r");
assert(lettura != NULL);
FILE * scrittura = fopen("sample.txt", "wb");
assert(scrittura != NULL);
uint16_t N = 0; //N is 16 bytes
char bytes[2];
char buffer[6]; // 5 char + terminator
do{
fscanf(lettura,"%s",buffer); // put one line in the buffer
N = atoi(buffer); // from char array to integer
bytes[0] = (N >> 8); // take the 8 msb
bytes[1] = (N & 0xFF); // take the 8 lsb
fwrite(bytes, 1, sizeof(bytes), scrittura); // output raw msb and lsb
}while (!feof(lettura));
fclose(lettura);
fclose(scrittura);
return 0;
}
做完这些,我们就可以第一次运行ent测试了。

Ent给出了几个参数:
- 熵:熵是一部分信息中包含的“随机性”的数量。信息理论告诉我们,理论上可以通过压缩而不损失信息的最小尺寸,由熵值表示。
- 卡方分布:这个测试是用来了解我们的数值分布对理论分布的遵守程度。从ent手册来看,这个值应该尽可能地接近256,百分比值在10-90%之间。
- 算术平均值:比特的简单算术平均值。由于数值在0到255之间,所以它应该大约等于127。
- 用蒙特卡洛方法计算π的值:在这里更多的是一个漂亮的数据,而不是一个有用的方法。
- 自相关:表示系列值之间的依赖性,在最佳情况下必须等于零。
香蕉与卡方的关系
卡方是统计学中的一个概念,主要用于测试一组数值与理论上预测的分布的拟合程度。
如果给定了一个数据集,频率为一个给定的数据项出现的次数,自由度为可能值的数量减去1。为什么要减1?假设抛硬币的情况,我们有两种可能的结果:正面和反面。但出现正面的百分比直接由它出现反面的百分比决定。那如果我们考虑一个有三种可能结果的事件,第三种结果的百分比直接由其他两种决定。

让我们再摇骰子为例。掷骰子有6个可能的结果,这给了我们五个自由度。那投掷1000次骰子,我们要验证统计学中所谓的零假设,或者验证在一定的概率范围内,我们的结果是真正随机的。
这些是从实验中得到的数据:

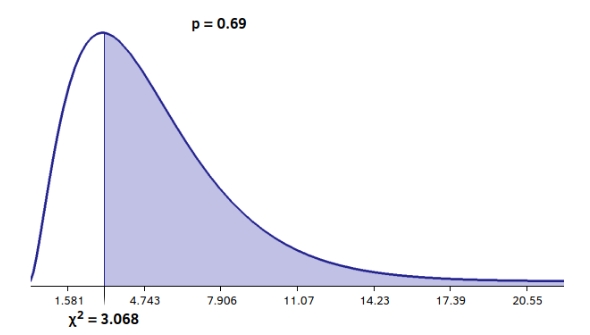
于是我们得到了实验的卡方值,3068。
现实情况下的数据完全反映理论分布是极不可能的,一个太接近于零的卡方值也是值得怀疑的。另一方面,我们离理论分布越远,分子就越大,而分母不变。这导致了卡方值的增长。这对卡方值而言,意味着能够拒绝无效假设,从而知道你所处理的数据不仅仅是偶然的结果,而是有一定的意义。
但然而,对于我们来说,这是一则坏消息,因为这意味着我们的数据不是均匀分布的。

表中的行代表系统的自由度,在模具案例中,有5个自由度。列代表计算值大于表格中的值的概率水平。也有一些表格表示计算值小于的概率,这些表格被称为左尾表,上面显示的表格是右尾表。这是因为在一种情况下考虑的是图形的右边,而在另一种情况下考虑的是左边。案例中chi^2=3.068,这介于90%和25%的情况之间。这足以说明,从我们可以归类为随机的行为来看,没有过度的变化。

让我们回到香蕉上,把90%和10%作为参考百分比,对于255个自由度,从ent对生成器记录的数值的测试中,能得到498.15的值,超出了可接受的范围,ent返回的概率百分比为<0.01%。

关于香蕉的猜测
但可能有人马上注意到,字节1的计数明显少于其他的,字节2的计数则多得多。仔细一看,那些“缺少”的计数被分配给了2。
经过一些测试,我决定将偶数位置的字节与奇数位置的字节分开。这是因为每生成一个16位数字(2个字节),就会产生两个字节,一个是偶数位置,一个是奇数位置。


MSB没有报告任何重大问题,但LSB组是问题所在。为了了解问题来源,我们必须首先了解数字是如何在内部产生的。
盖革管通过一个接口电路,当它被辐射击中时,在单片机的引脚2(PB2/INT0)上发送一个信号,引脚2被配置为在收到上升沿时产生一个中断:attachInterrupt(digitalPinToInterrupt(2), randomCore, RISING);。中断将调用randomCore()函数,其定义如下:

该函数被调用时,反过来调用单片机的micros()函数。这个函数返回一个32位的数字,代表自系统开启以来已经过去的微秒数。作为一个32位无符号数,它将在4294.96秒后溢出,或每70分钟左右溢出一次。由于微控制器的速度不足以获得更准确的更新,micros()以4微秒为单位进行更新,始终保持两个最小有效位为零。
出于这个原因,我们将micros()返回的值向右移动了两个比特。这样我们就得到了一个30比特的值。如果我们也使用最小有效位,我们将得到渐进的数字,直到下一次定时器溢出。在溢出发生的70分钟内,每个数字肯定会比前一个大,也肯定会比后一个小。这绝对不是随机的。
因此,让我们只保留micros()的前16字节。这个值每隔262144微秒就会有一次溢出,使得上述情况发生的可能性极小。

注意到,这个值每4*2^8=1024微秒出现一次,或者说大约1毫秒,是产生中断溢出后的下一个值。然后我们把注意力放到单片机核心的millis()函数的代码上来。
millis()函数通过将TIMER0的预分频器设置为64来工作,对于一个时钟为16MHz的8位定时器来说,这导致每1.024毫秒就有一次定时器溢出。定时器溢出会产生一个中断,向量为TIMER0_OVF。如果盖革管脉冲与TIMER0溢出同时到达,我们将有两个相互竞争的中断:TIMER0_OVF和INT0。这种情况由微控制器的中断优先级系统来处理,其优先级顺序在数据手册中标明。

TIMER0溢出的优先级比外部中断低得多,所以就有了以下猜测:
情况1:INT0中断与TIMER0_OVF中断同时到达。由于它有更高的优先级,外部中断首先被执行,牺牲了millis(),影响了函数的准确性,但对生成的数字没有产生明显的影响。
情况2:INT0中断比TIMER0_OVF中断在下一个时钟周期到达。由于已经过了一个时钟周期,TIMER0_OVF中断已经在执行了。当执行结束时,micros()已经是2的值了,所以生成的数字将被注册为2的值。
但也有可能使用串行对延迟产生了影响,但还需要进一步调查




















