1. IDS 的简介
Intsig Data Studio(IDS)是上海合合信息科技股份有限公司,大数据平台基于微众WDS社区开源的 Linkis&DSS 组件构建的一站式敏捷数据应用开发管理门户,面向的主要用户群体包括数据开发、数据分析、数据产品经理和数据质检人员等。
对外提供的核心能力包括一站式数据开发交互平台,支持数据从进来(数据集成),到处理(数据探查、作业调度),到出去(数据服务,BI 报表),到运维(任务运维、数据质量)等全链路的可视化操作。
下图展示了 IDS 在我们大数据平台中的定位,其上层衔接用户或各种应用系统,底层联通各种各样的计算或存储引擎。
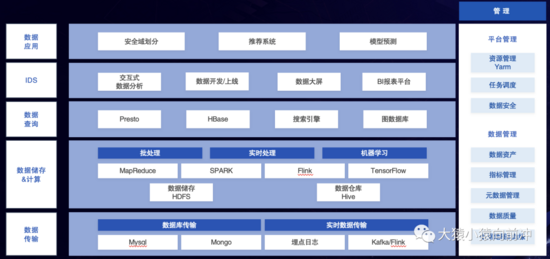
IDS的定位
2. IDS 的诞生背景
在未引入 Linkis 和 DSS 之前,公司内部缺少一个统一的开发入口,数据平台中的用户在进行数据探查、业务上线的过程中要分别登入到不同的组件中进行操作,比如:对库表元数据的访问需求,需要使用自研的指标系统或数据地图;做数据分析时,又要借助于 zeppelin 或 ipython 等工具进行交互式数据查询;作业流调度发布时,又重度依赖于平台组同事来编写Airflow底层复杂的任务依赖描述代码。
在数据开发的整条链路中,涉及到的系统之间无法做到有效联通,应用孤岛问题日渐严重,用户也疲于在各种组件之间反复切换,这种现状一直影响着大数据平台用户的开发效率和使用体验。同时,多个开发入口的存在,也增加了我们大数据平台的运维成本,其潜在的数据流出风险也被叠加放大。
在此背景之下,我们需要一个统一的一站式数据开发、分析和可视化的平台。为此,我们先后调研或试用了商业化的大数据中台产品,如网易的数帆和阿里的dataworks等。一线大厂开发出来的产品,确实有着一套业界非常领先的标准和规范,以及拥有着非常强大而全面的数据治理能力,但综合考量我们现有的需求场景和成本投入等多方面因素,我们最终没有接受商业化的数据中台解决方案。
不得已,我们又把目光投向了开源界的产品,WDS 顺理成章地闯入了我们的视野,虽记不清与 WDS 相识的具体日子,但 WDS 社区及其生态组件所展现出来的能力,着实让我们怦然心动。
WDS 是一站式、金融级、全连通、开源开放的大数据平台套件。目前支持的开源组件包括,DataSphere Studio 、Linkis,Qualitis 等。WDS 社区运营给力,成员活跃,自 19 年以来发布的 9 个开源组件,填补了业界“开源体系大数据平台套件”的空白,受到了各行业的广泛好评和采用。基于包装好的轮子,让众多中小企业依托开源社区的力量来搭建内部一站式大数据平台的梦想变得不再遥不可及。
3. IDS——合数据工坊的实践之路
IDS(合数据工坊)是我们对 Linkis 和 DSS 的统称,Linkis 作为计算中间件,底层对接各种计算或存储引擎,上层衔接各种服务或应用,DSS 则提供一站式数据开发管理门户的基层组件。在现阶段,我们使用的 DataSphere Studio 和 Linkis 组件的版本分别是:1.0.1 和 1.0.3。
在这其中,最重要的工作是完成对 Linkis 的适配和应用,我司目前的大数据平台基于 cdh5.13.1,为此我们修改了 Linkis 中依赖的大数据组件的版本以适配我们的版本,在这个过程中基本没遇到什么太大的坑,因为自 Linkis1.x 版本以来,针对 CDH5、6 以及其他社区组件版本的兼容性都很好,基本不会出现太大的依赖冲突等问题,即使出现问题,依靠强大且活跃的 Linkis 社区,我们也能得到及时而有效的反馈。
除了与内部 hadoop 等组件做适配兼容之外,针对 Linkis1.1.x 版本中的一些大的特性修复,我们也以 patch 的形式打到了内部 1.0.3 版本里,如:
https://github.com/apache/incubator-linkis/issues/1765
https://github.com/apache/incubator-linkis/pull/1780
现阶段是我们 IDS 的建设初期,内部针对 DSS&Linkis 的应用方式或一些小的改造点,我将在下文中从如下几个方面来叙述:
- 用户权限
- 引擎增强
- 作业调度
- 数据治理
- 小型优化
3.1 用户权限
IDS 集成了公司内部的 SSO 登录方式,用户扫码登录系统之后,不可创建新的工作空间,只能使用统一的公共工作空间,在此工作空间下,不同角色身份的用户,对 IDS 中集成的组件入口,拥有不同的访问权限。
IDS
同时,基于 DSS 独有的 AppConn 设计理念,DSS 可以简单快速地集成各种上层 Web 系统。目前,在 IDS 中已集成的组件列表包括:数据传输,数据探查,数据地图,运维平台,数据质量,SLA 治理,数据服务等。
组件列表
DSS AppConn 的相关文档可参考:https://github.com/WeBankFinTech/DataSphereStudio/blob/master/README-ZH.md
各个系统组件的入口访问基于 IDS 中的角色及权限管控,组件之间 SSO 互通,共享同一个登录认证体系。同时,为了更加方便地初始化用户相关数据,我们增加了用户数据初始化服务,负责在每个 Linkis 的安装节点上初始化用户的数据,如:创建 Linux 用户和用户组,创建用户的 workspace 目录,为用户分配统一的工作空间,在 Windows AD 域中创建用户,SSSD 同步用户信息到所有集群节点,为用户导出 keytab 等。
不仅用户对 IDS 组件入口的访问受到权限控制,在进入到组件内部之后,具体组件中受保护的资源同样需要在权限系统上审批。

组件访问权限
下图展示组件系统中对应功能模块的访问申请与负责人审批。

组件权限申请
3.2 引擎增强
3.2.1 引擎类型扩展
基于 Linkis 官方提供的 JDBC 引擎,我们内部额外增加了 Presto 、 Clickhouse 、 Kyuubi 等引擎,并在 Scripts 中支持了对应引擎类型脚本的提交,以满足用户对不同计算引擎的需要,同时满足用户对不同类型脚本的区分。
引擎类型扩展
多引擎支持:
多引擎支持
3.2.2 Presto 慢查询列表
Presto SQL 在我们内部所占比重最大,针对 Presto 引擎,我们为用户提供了进度提示和慢查询列表等功能。
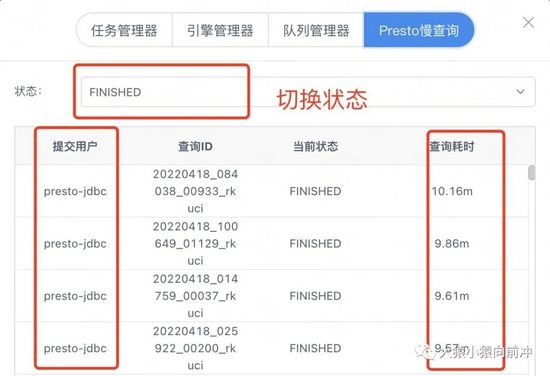
Presto慢查询列表
当前阶段,Presto 慢查询列表的主要功能是为了能直观体现出来每个用户提交 SQL 的执行情况,我们的 Presto 集群在未上 k8s 之前,用户隔离机制还不够完善,有些用户提交的 SQL 会占用较大的资源,耗时较长,对其他用户的 SQL 任务也会产生一定的影响,在旧的平台模式下,这部分指标数据对开发用户是不可见的,需要集群维护人员到 Presto UI 上去排查慢查询的 SQL 任务,无法做到及时有效地响应,这严重影响着用户使用 Presto 查询数据的体验。
在这之后,我们在 K8s 环境中部署了 Presto 集群,在 Presto 集群扩缩容,及资源管理方面进行了较大的优化,后续,如有必要,针对 Presto Query 时输出的指标,我们会继续从多个维度来分析,并以更好地形式展示给用户。
3.2.3 JDBC 引擎多数据源的支持
目前,官方在 DSS&Linkis1.0.3 中,对 JDBC 类型引擎的多数据源连接支持还不够完美,我们在此基础上做了改良。
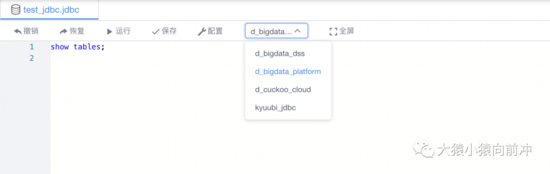
JDBC 多数据源支持
如图,用户通过切换不同的数据源连接标识,来达到连接不同 JDBC 服务的效果。后续官方会在 1.2.0 版本中支持此功能,详见:https://github.com/apache/incubator-linkis/issues/2092
3.3 作业调度
DSS 提供了一套作业流设计与上线功能,其底层调度组件 Schedulis 的调度能力依赖于 Azkaban,但我们内部的调度系统一直使用的是 Airflow,在构建 IDS 之前,我们有一套自研的作业流设计和上线平台—— Cuckoo Cloud ,其 web 化功能类似于 DolphinScheduler ,支持用户拖拽式的设计工作流,并一键发布作业 DAG 到 Airflow 调度平台上,以弥补 Airflow 在任务上线、依赖设计方面缺少可视化工具的不足。
因此在现阶段,我们没有使用 DSS 原生的工作流设计和发布能力,而是以 appconn 插件的形式集成了我们内部的工作流设计平台,两个组件之间打通了 SSO 登录,共享一套用户认证体系。
内部的作业流设计组件主要分三层结构,DAG 配置管理、调度单元管理、以及每个调度单元中所包含的任务节点及其依赖关系等。
3.3.1 DAG 配置管理
此处 DAG 配置与 Airflow 上的每个 DAG 信息相对应。
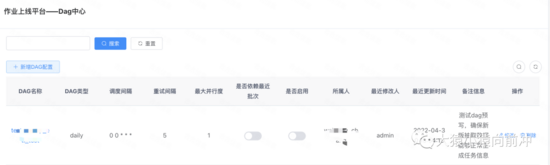
DAG配置
3.3.2 调度单元管理
IDS 平台用户把拥有某一具体业务含义的任务节点及其上下游依赖关系划分到同一个调度单元之中,调度单元的作用不仅强调了某一具体的业务属性,同时也是为了对一个完整 DAG 进行概念意义上的拆分。
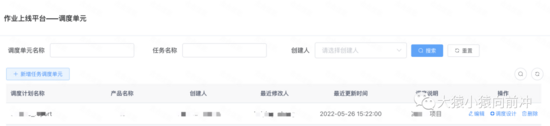
调度单元
3.3.3 调度单元中的任务及其上下游依赖关系
用户在使用调度设计功能时,有丰富的任务类型可供选择和组合,几乎涵盖了公司内部一条数据开发链路中大部分的场景需要,同时,对额外任务节点的支持扩充,也非常快速便捷。

tasks
调度工作流的设计
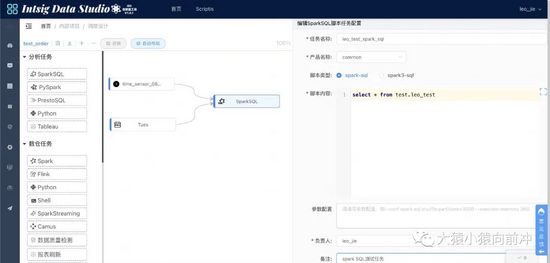 调度设计
调度设计
备注,特殊任务节点,如 Tableau、报表刷新、报表发送类型任务。原有的开发模式是,Tableau 数据源刷新任务的定时执行是需要用户在 tableau server 平台上创建相应数据源的定时刷新计划。这会带来以下几个问题:
- 任务积压,每个调度的时间点,都会有批量的数据源刷新任务提交执行,容易出现 Presto 节点负载过高,Spark Thrift Server 的 driver 进程挂掉等问题,这些问题的产生,都会导致数据源刷新任务的失败。
- Tableau Server 上数据源刷新任务失败之后,缺少自动重试机制,也无法进行有效预警,如高权重报表刷新失败后打电话,低权重报表刷新失败后发企业微信消息等。
- 报表数据源的刷新依赖于数仓批跑任务的完成,但两者之间分散于不同的调度系统之中,只能预估上游任务的完成时间,来设置下游任务的开始执行时间,一旦上游延迟,下游任务无法做到及时感知,这将导致报表数据缺失。
针对上述问题,我们选择把报表数据源刷新任务包装成 Airflow 的任务节点,此举带来的成效有:
- 数据源刷新任务上下游依赖强关联,消除了上游依赖任务缺失导致的下游数据源空刷,报表无数据的问题,同时,任务调度时间被打散,解决了任务运行积压的隐患。
- 数据源刷新任务支持自定义权重,失败之后可以自动重试,并能感知远程计算引擎的健康状态和自身刷新队列的冗余,以选择是否延迟提交刷新任务。在任务重试不过的情况下,可以匹配出不同权重下的报警方式,来告知用户任务运行失败的原因。
- 与 SLA 管理平台打通,实现核心任务全生命周期的 SLA 标准化管理流程,自动为核心报表任务的上游依赖划分高权重资源队列,并可以动态调整上游链路任务运行时所需的资源,同时,还可以实时监控核心报表上下游任务链路的运行状况,实时进行延迟告警,SLA 任务链路未准时指标收集,并发送给各个业务方核心任务的准时率统计指标等。
用户完成工作流的设计之后,点击发布按钮,工作流便会被 Airflow 感知,渲染,继而进行后续的定时执行,对应 Airflow 上工作流如下图:
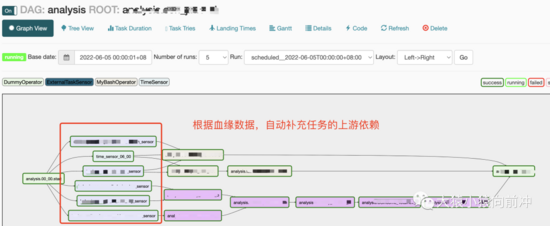
IDS工作流
未来工作流设计平台的一些需要提升的地方:
- 目前工作流中一些脚本任务开发的时候,不支持脚本的直接执行,需要用户在 IDS 中执行成功之后,把脚本贴回到工作流平台上去发布上线。
- 其次,工作流不支持多环境发布、暂停调度及版本管理等高级功能,后续会考虑迁移工作流设计功能到 DSS 中或考虑迁移调度至 DolphinScheduler 中。
3.4 数据治理
3.4.1 数据地图
数据地图以不同的安全等级、主题域或业务标签来划分数仓库表和其他存储系统中的库表元数据,并对外提供数据检索能力,用户通过该平台可以以较小的成本找到所需的数据、报表、中间件、以及相关实体的血缘。
用户在 IDS 平台中查询数仓、CK 或其他存储系统中的线上表时,会经过 SQL 拦截器解析出来待操作的表,用户只有在数据地图中提交这些表的访问申请,并被审批通过之后,才被允许继续执行 SQL。
对应的,Scripts 中库表元数据列表所能展示的也仅限于授权过的资源,以及用户在数据地图中分类创建的一些主题库的资源,如下图:
主题库
数据地图及主题库建设
数据地图
3.4.2 数据流出管理
现阶段,IDS 平台上的数据流出包含如下两种形式:
- 少量数据下载,主要以 csv、excel 两种文件格式。
- 全量数据导出,主要以 csv、excel、json 三种文件格式。并且,只有用户在数据地图中申请过表的导出权限后,才被允许导出服务器上的全量数据到内网隔离环境。
用户提交的 SQL 正确接收到结果集之后,便会激活结果集的导出功能,用户点击导出按钮,填写好数据导出申请的表单,提交之后,数据导出服务检测到数据导出任务,便开始处理用户的数据导出需求。
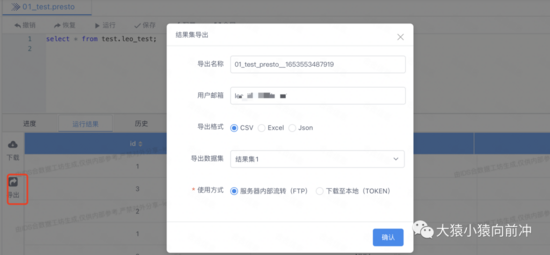
数据导出
用户可以在数据导出列表页面中查看自己的数据导出任务最新的执行状态。
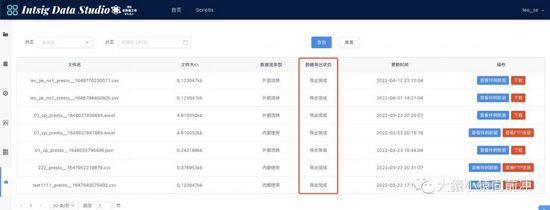
download-data-list
3.4.3. 数据同步
主要用于多种异构数据源之间的数据交换,可实现各部门业务数据在应用层面的互联互通和信息共享。功能特性:
- 多种数据源支持,包含但不限于 mysql、mongo、odps、es、oss、hive 之间的相互传输
- 数据传输限流,除了基本的限流算法还支持控制全局的传输并发
- 数据传输类型丰富,全量、增量、增量融合、拉链表
- 自动调参,以达到最好的抽取效率
- Web 端可视化配置,随工作流设计与调度发布
数据同步
3.4.4 数据质量
数据质量中心通过事前定义监控规则、事中监控数据的生成过程以及事后评估和问题追溯,围绕完整性、一致性、准确性、有效性和及时性五个方面衡量数据质量, 并依托离线开发中心的数据质量配置,提升企业数据价值。
现有数据质量平台功能
- 可以添加自定义质量模板规则,模板规则支持 udf、正则
- 有质量评估评分,可以查看表和字段的质量评分
- 可以对脏数据进行保存,方便查看脏数据问题
- 支持强规则的熔断机制,防止脏数据影响下游数据
- 拥有试跑机制,并且可以查看试跑结果
- 指标看板可以查看历史的脏数据趋势
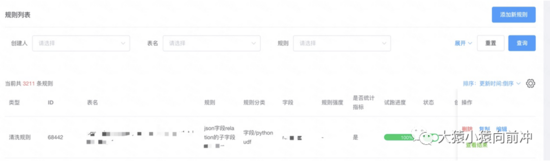
规则列表
数据质量指标
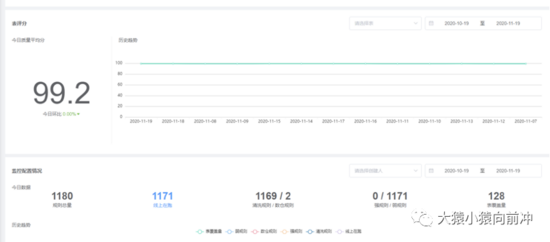
数据质量指标
3.4.5 SLA 治理
SLA 平台为用户提供核心数据的申报、SLA 的在线签署,及签署后的 SLA 运维管理功能,通过协同全链路能力,共同保障申报节点的数据质量。
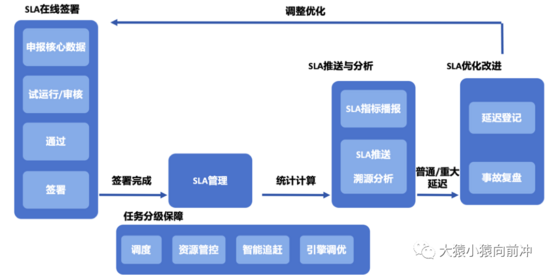
数据SLA
SLA 指标
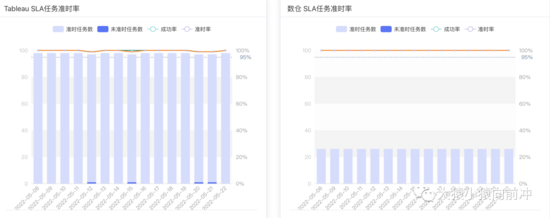
SLA指标
3.5 IDS 中一些小的功能改造点或应用项
以下列举的是一些小的优化项,主要是为了优化用户的一些使用体验。
- Scripts 中脚本目录的复制和剪切功能
- 脚本执行过程中,改变任务进度拉取的固定频率为渐次递增频率
- 脚本文件共享机制,用户可以共享单个(或多个脚本文件)给其他用户,并设置该用户对此脚本的读写权限。
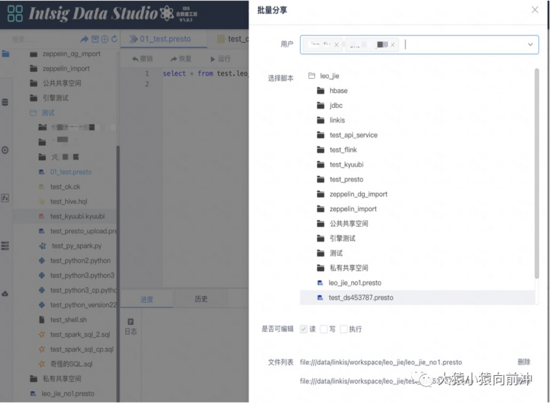 share-file
share-file
- 组件使用的文档指引、及视频教程等完善,以提供给用户更好的使用体验。
- 把 Spark 引擎的一些高级参数,增加到配置项中
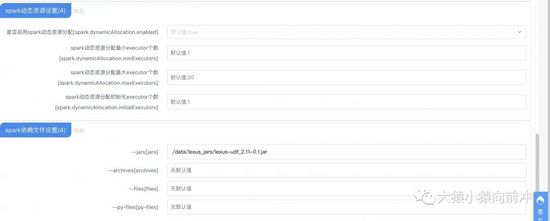
spark-engine-conf
- IDS 中增加用户意见反馈一键发布功能
意见反馈
4. 总结
当前阶段,我们基于 DSS 和 Linkis 完成了内部 IDS 平台的初步构建,获取了部分用户从 zeppelin 平台过渡到 IDS 平台的阶段性成果,并为社区伙伴们,分享了我们内部实践过程中的一些自认为值得说一说的点,以及一些小的功能或体验改造项,以期望各位在调研或初步在使用 WDS 套件的公司或团队,从我们的“答卷”中能获取到一些有用的经验,最后,再次感谢微众及社区其他开发者大佬们,对我们集成过程中的解疑答惑。