













【技术DNA】

【智慧场景】
********** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ***************** | ***************** |
场景 | 自动驾驶 / AR | 语音信号 | 流视频 | GPU 渲染 | 科学、云计算 | 内存缩减 | 科学应用 | 医学图像 | 数据库服务器 | 人工智能图像 | 文本传输 | GAN媒体压缩 | 图像压缩 | 文件同步 | 数据库系统 | 通用数据 |
技术 | 点云压缩 | 稀疏快速傅里叶变换 | 有损视频压缩 | 网格压缩 | 动态选择压缩算法框架 | 无损压缩 | 分层数据压缩 | 医学图像压缩 | 无损通用压缩 | 人工智能图像压缩 | 短字符串压缩 | GAN 压缩的在线多粒度蒸馏 | 图像压缩 | 文件传输压缩 | 快速随机访问字符串压缩 | 高通量并行无损压缩 |
开源项目 | SFFT | Ares | LZ4 | DICOM | Brotli | RAISR | AIMCS | OMGD | rsync | FSST | ndzip |
引言:
着高质量多媒体服务的增加,数据压缩已成为使用存储的电子设备的必要条件。
多年来,移动通信和视频服务的质量不断提高,传输和存储数据的需求呈爆炸式增长。对大容量存储和传输的需求增长速度至少是存储和传输容量增长的两倍。本文将为大家介绍一种基于 LZ4 的改进算法和一种优化的移动设备硬件结构。
应用场景
1、移动通信

2、视频服务

移动设备约束条件
- 近年来,随着物联网等场景的不断发展,一些问题也逐渐的暴露了出来,就比如嵌入式设备上的CPU时钟频率,电源等资源都是有限的;对于部分设备来说可能换个时钟频率高的时钟、换个大的电池确实可以解决问题,但对于手机这种嵌入式移动设备来说,像是要做到便携、轻薄等等要求,体积就被限制住了,电源也因此被限制住了。
- 因此,需要一种基于硬件的压缩方法来解决这个问题。
本方案的解法
基于字典的自适应压缩方法都起源于Lempel-Ziv 算法,LZ4 是最快的压缩算法之一。
但下面我们将为大家介绍一种先进的算法和硬件架构,提高了压缩比和速度。为了获得更高的压缩比,本算法可变长度格式,而LZ4 采用定长格式。实验结果表明,该体系结构的压缩吞吐量可达 3.84Gbps,压缩比可达4 。
通过这种方式,我们基于硬件的架构以低功耗提高了移动设备的内存性能和电池寿命。
LZ4 分析
- LZ4 是 LZ77 的一个变种算法,是 Collet 在2011年提出的固定的(fixed),面向字节(byte-oriented)的算法。
- LZ4 的伸缩数据如图所示,它由令牌(Token) 、 字面量长度(Literal length) 、 偏移量(Offset) 和 匹配长度(Match length)组成。
- LZ4 和 LZ77 类似,它有一个滑动窗口,由一个搜索缓冲区和一个向前查找缓冲区组成。
- LZ4 搜索之前没有压缩数据流中的重复数据,并用索引替换它。
- LZ4 通过哈希表来匹配数据,从而提高了压缩速度。
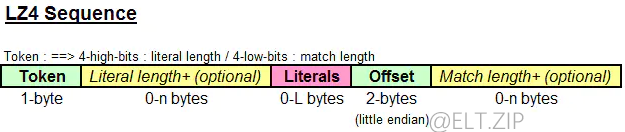
令牌(Token)
- 令牌(Token) 长一个字节,其中前4个字节为字面量长度(Literal Length),其后四个字节为匹配长度(Match Length)。
- Token[3:0]表示匹配长度,表示 0 ~ 15 的文字长度。
- Token[7:4]表示字面量长度,是比较不重要的位,匹配长度从0 ~ 15。

- Token [7:4]的值如果为0,则代表没有文字。
- Token [7:4]的值如果为15,则表示文字长度必须有从 0~255 的额外字节来表示字面量的完整长度。
- Token [3:0]的如果值为0,则表示最小匹配长度为4,称为min match。
- 因此,Token [3:0]的值从0到15意味着匹配长度值从4到19。如果Token[3:0]的值为15,则匹配长度中有更多字节。
字面量长度(Literal Length)
- 当Token[7:4]值为 15 时,字面值长度(Literal Length)就是额外的字节。
- 如果字面量长度为 0~254,则没有更多的字节。如果字面量长度是255,在下一个字面量长度中有产生更多的字节。
偏移量(Offset)
- 偏移量(Offset)占用2字节,采用little-endian格式,它表示要复制的匹配的位置。
- 偏移值为 1 表示当前位置为 1 byte。最大偏移量为 65535。
匹配长度(Match Length)
- 匹配长度(Match Length)类似于上面说到的字面量长度(Literal Length)。
- 当Token[3:0]达到可能的最高值 15 时,额外的字节被添加到匹配长度中。
总结
- LZ4 总是为偏移量(Match Length)分配 2字节,但其实这对压缩比的性能影响不大。
- LZ4算法最初是为了在一般处理器上进行软件实现而提出的,因此在一些硬件上实现 LZ4 存在一定的约束。
改进的LZ4
本文作者改进了LZ4的数据格式的序列和哈希计算。
- 通过指定压缩单元的大小,可以优化哈希表的大小。
- 将压缩单元的大小设置为 4KB,可以为内存页进行优化并节省内部内存。
数据格式
- 这里作者改变了 LZ4的首部(Header)和偏移量(Offset),下图分别是 改进后的 LZ4 与 LZ4 的格式。
Header | Token | Literal | Length Literals | Offset | Match Length |
2 Bytes | 1 Byte | 0-n Bytes | 0-L Bytes | 1-2 Bytes | 0-n Bytes |
Token | Literal Length | Literals | Offset | Match Length | |
- | - | - | - | - | |
1 Byte | 0-n Bytes | 0-L Bytes | 2 Bytes | 0-n Bytes |
首部(Header)
- 头部位于每个压缩单元的开头,包含压缩大小(Compressed Size)和原始标志(Raw Flag)。
- 如果压缩后的数据大小大于原始数据大小,则原始标志(Raw Flag)则被标记为1,原始数据将被添加在首部(Header)之后,压缩符号将不被添加,解压器也不需要解压该压缩单元。
- 在数据根本没有压缩的最坏情况下,原始标志(Raw Flag)使解压缩程序更快。
- 在最坏的情况下,压缩单元大小被添加到原始数据的头部大小中。
偏移量(Offset)
- 偏移量(Offset)由大小标志(Size Flag)和偏移量大小(Offset Size)组成。
- 大小标志(Size Flag)是最重要的位。如果大小标志值为 0,偏移量大小则使用 7 bit,即{offset [7], offset[6:0]}。
- 如果大小标志值为 1,偏移量大小则使用 15 bit,即{offset [15], offset[14:0]}。
- 偏移量大小表示匹配的位置,最大偏移大小值为32768。
- 可变偏移字节长度使我们的方法比LZ4有更好的压缩比。哈希计算
- 哈希函数的目的是将任意大小的数据映射到固定大小的数据。对于匹配检测,使用哈希表的搜索算法要比其他算法快得多。
- 理想的哈希表的大小是输入数据位乘以压缩单位字节的大小。但是,由于哈希表的大小是有限的,因此哈希计算计算输入的比特数要比输入的比特数小。
- 哈希计算的性能取决于不同的输入得到相同结果的频率。
- LZ4的哈希计算算法基于Fibonacci哈希原理,计算公式如下:
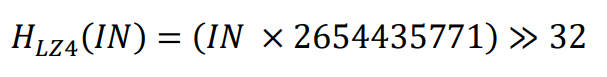
- 上述公式中的IN为32位值,LZ4的哈希计算公式在硬件上实现复杂,并且计算周期长。于是作者改进了该哈希计算公式,公式如下:
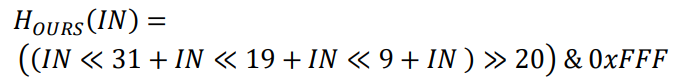
- 这里压缩单元大小为4KB,改进后的公式被 12 bit 屏蔽,仅使用位操作就可以将32位输入映射到12位。因此,一个很小的硬件资源就足以计算改进后的哈希计算公式,并且只需要一两个周期。
建议的硬件架构
总模块
- 这里作者提出了一种建议使用的硬件架构。它主要由核心模块(压缩模块和解压缩模块)和高级微控制器总线体系结构(AMBA)接口组成,实现应用处理器的互连。
- 核心模块通过高级外设总线(APB)与处理器进行控制信号通信。输入数据和输出数据通过高级可扩展总线(AXI)处理。
- 下图为总体的硬件架构:
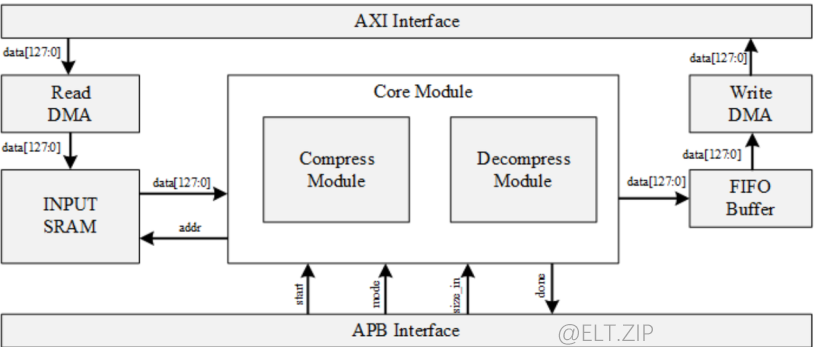
- 下表描述了是各个模块的数量,面积以及总面积。
模块 | 模块数量 | 面积 | 总面积(mm2) |
Compress | 1 | 0.01320 | 0.01320 |
Decompress | 1 | 0.01345 | 0.01345 |
Hash Table | 2 | 0.00515 | 0.01029 |
SRAM | 8 | 0.00652 | 0.05215 |
AXI(DMA) | 1 | 0.01187 | 0.01187 |
APB | 1 | 0.00133 | 0.00133 |
压缩模块
- 压缩模块主要由SRAM控制组件、哈希计算组件、字节匹配组件和流生成组件组成,下图为压缩模块的架构图。
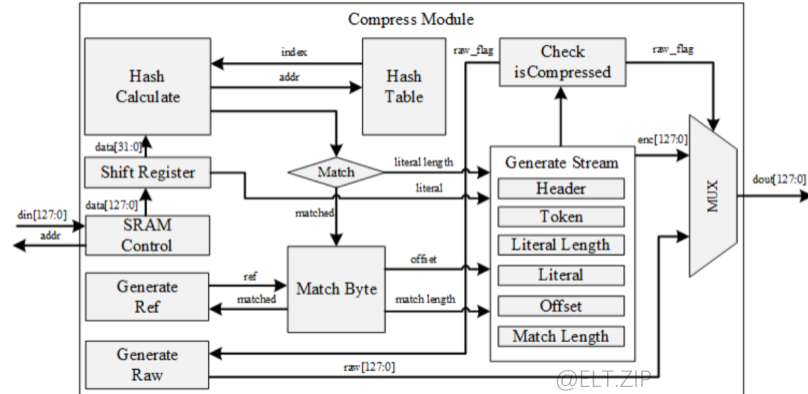
- 为了避免数据输入的瓶颈,压缩模块将输入数据写入8个独立的SRAM。
- 之后压缩机从SRAM移位寄存器读取128 bit 数据。
- 对于每个 4 byte 的输入数据,哈希计算模块计算哈希值,读取哈希表来比较和更新索引。
- 如果在哈希表中搜索计算出来的哈希值,则移动到该位置并开始匹配字节。当匹配长度大于4时,因为哈希值已经从前面的文字计算出来了,此时可以跳过哈希计算。
- 压缩单元最后一次数据处理完毕后,压缩机检查压缩尺寸是否大于原始尺寸。如果大于原始尺寸,压缩模块将原始标志(Raw Flag)设置到首部(Header)并输出原始数据。
- 当压缩内存数据时,对于未压缩的页,只将页头写入输出。在这种情况下,CPU读取头中的原始标志(Raw Flag),解压时执行memcpy
解压缩模块
- 解压缩模块比压缩模块简单,它主要由SRAM控制组件、流解析组件和缓冲区组件组成。
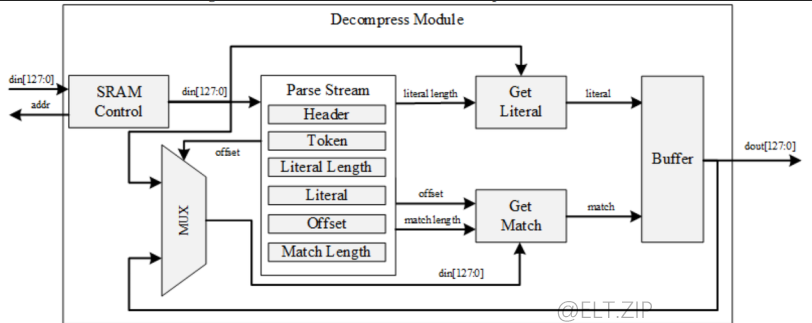
- 解析器流通过从SRAM读取输入数据来解析报头和每个符号。
- 字面量通过复制文字长度从输入数据中获得的
- 匹配部分是通过匹配长度从已经解压的数据中的偏移位置复制的。
- 如果与当前数据的偏移距离太近,后续管道可能不会写入数据。因此便有了缓冲区来保存没有写入的数据。
实验及结果
- 在这里,作者将提出的设计与原来的 LZ4 进行了比较,并展示了压缩比与压缩速度以及各种数据类型之间的关系,这些数据类型包括二进制数据、文本数据、Android应用程序包、字体数据、JPEG图像以及 HTML页面数据。
- 本实验所提出设计运行在 400MHz 的处理环境下。数据的吞吐量也取决于总线条件,在考虑总线条件的情况下,要考虑整个模块的压缩速率。
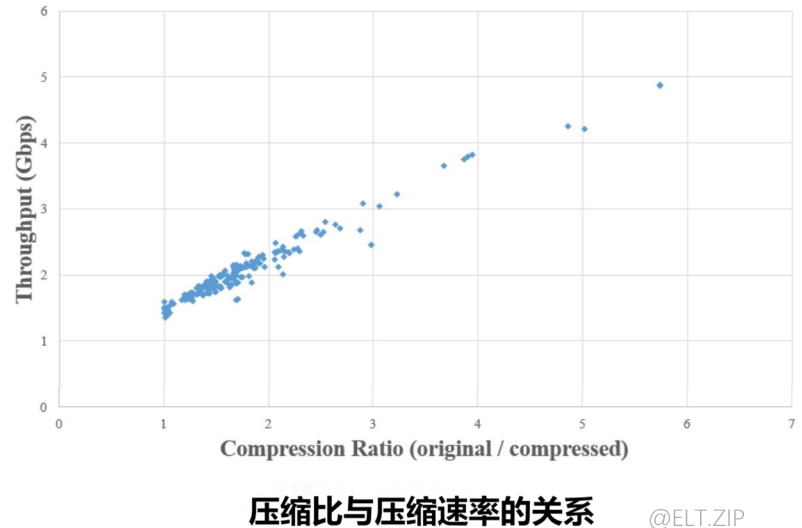
- 由图 【压缩比与压缩速度的关系】 可知,压缩比与压缩速率呈线性关系。
- 较低的压缩比意味着大多数的输入字节都被处理,因此压缩速率变慢。
- 相反地,压缩速率很快的情况下,将会跳过部分匹配的字节,压缩比会增大。
- 总的来说,压缩速率取决于压缩比,压缩速率也与压缩比呈正比。
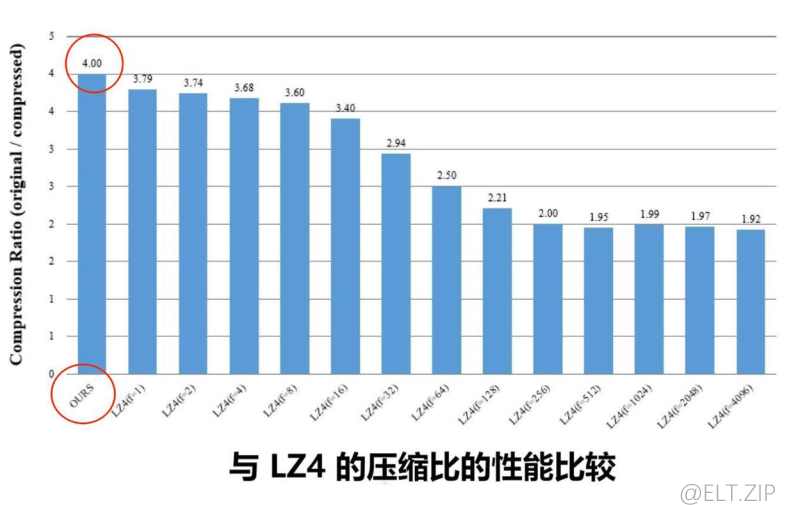
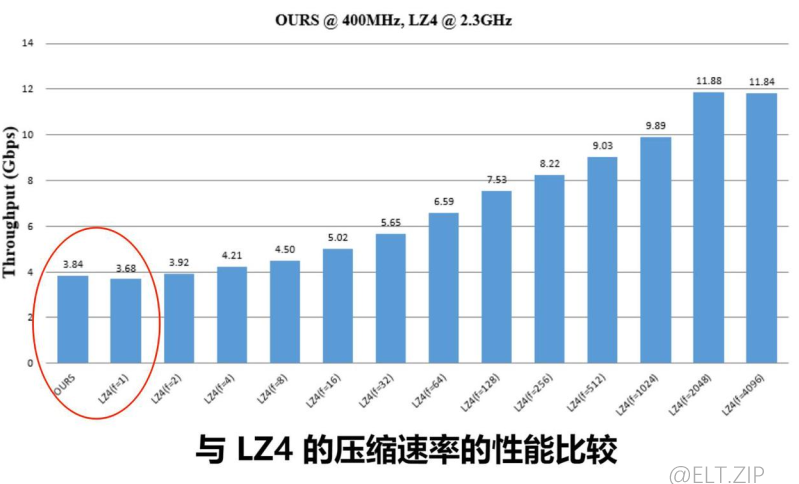
- 由于在LZ4中有一个加速选项,加速值越高,压缩越快;相应的,压缩比会降低。这里便有了上述两图与LZ4各加速方案进行了比较的实验。
总结
本文提出了一种改进的 LZ4 算法和硬件结构。可变长的偏移量、优化的哈希算法以及硬件流水线都提高了压缩速率和压缩比。
- 该设计可实现高达3.84Gbps的压缩吞吐量和高达4的压缩比。
- 它的压缩速度比 LZ4 算法快4%,压缩比比 LZ4 算法高5%,但它的最高时钟频率比 LZ4 慢。
- 文中所提出的硬件架构可以针对移动设备环境进行优化,因此它不仅可以用于压缩移动设备中的内部存储,还可以用于压缩RAM,从而有望提高内存性能。
- 该硬件架构还可以实现低电流驱动和低功耗驱动,从而提高电池寿命。






























