














【技术DNA】

【智慧场景】
********** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ***************** | ***************** |
场景 | 自动驾驶 / AR | 语音信号 | 流视频 | GPU 渲染 | 科学、云计算 | 内存缩减 | 科学应用 | 医学图像 | 数据库服务器 | 人工智能图像 | 文本传输 | GAN媒体压缩 | 图像压缩 | 文件同步 | 数据库系统 | 通用数据 |
技术 | 点云压缩 | 稀疏快速傅里叶变换 | 有损视频压缩 | 网格压缩 | 动态选择压缩算法框架 | 无损压缩 | 分层数据压缩 | 医学图像压缩 | 无损通用压缩 | 人工智能图像压缩 | 短字符串压缩 | GAN 压缩的在线多粒度蒸馏 | 图像压缩 | 文件传输压缩 | 快速随机访问字符串压缩 | 高通量并行无损压缩 |
开源项目 | SFFT | Ares | LZ4 | DICOM | Brotli | RAISR | AIMCS | OMGD | rsync | FSST | ndzip |
引言
- 近年来,为了追求让深度神经网络(DNNs)在复杂的机器学习任务中能够表现出更良好的性能,采取了不断扩大 DNNs 尺寸的方式,这就使模型在内存方面变得越来越复杂,不仅意味着更大的内存需求,还很可能造成更慢的运行时和更多的能量消耗,因此便需要对它们进行有效的压缩已满足多方面要求。DeepCABAC 是一种用于 DNN 的通用压缩算法,它基于应用于 DNN 参数的上下文自适应二进制算术编码器(CABAC)。CABAC 最初是针对于 H.264 / AVC 视频编码标准而设计的,并且成为了视频压缩无损压缩部分的最先进技术。DeepCABAC 运用了一种新的量化方案,实现了最小化信息率失真函数,同时也考虑了量化对 DNN 性能的影响。
- 深度神经网络成功可以归因于三个现象:(1)获得大量数据(2)研究人员设计了新的优化算法和模型架构,允许训练非常深入的神经网络(3)增长计算资源的可用性。

- 在资源受限的设备(如移动可穿戴设备)和分布式学习场景(如联邦学习)上部署深度模型的需求也越来越大。这些方法在隐私、延迟和效率问题上有直接的优势。然而,这些模型所需参数数量不断增长,这意味着模型在内存方面变得越来越复杂。高内存复杂性极大地增加了神经网络在用例中的适用性,特别是在联邦学习中,因为网络的参数是通过带宽有限的通信信道传输的。

- 而引出模型压缩显得尤为重要:只留下解决任务所需的内存,降低通信和计算成本,压缩算法有利于生成更高的熵,因为它们使数据更加紧凑。我们使用一个基础数据集,用各种算法压缩每个文件。
信源编码
- 通常所谓的编码,更确切地说是“压缩”,即去掉一些多杂的信息一保留必要的信息,再进行传输,因此在传输前要进行多种处理。其中为 了提高传输效率的有效性编码叫做信源编码。信源编码是信息论的一个分支,研究所谓码的性质。 通常由编码器和解码器两部分组成。
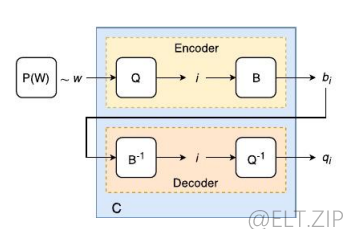
- 如图,首先,编码器通过两个过程将概率源 P(w)的输入样本 w 映射到二进制表示b,将输入量化,将其映射为整数 i = Q(w)。然后,通过一个二值化过程将该整数映射为其对应的二进制表示形式 b = b (i)。 解码器通过应用逆函数 B−1(B) = i 类比地将二进制表示映射回其整数值,并为其分配一个重构值(或量化点)Q−1(i) = Q。我们强调 Q - 1 不一定是 Q 的倒数。
简单地说,源编码研究的是查找最大限度地压缩一组输入样本的代码,同时在容错约束下保持输入值和重构值之间的误差。我们同时还可以分为两种类型的码,所谓的无损码和有损码(往期的文章里讲述过,感兴趣可以回顾,篇幅原因只做简述)。
无损编码
- 无损码也称熵编码或可逆编码:Huffman 编码、算术编码、字典编码。
有损编码
- 有损码也称不可逆码:标量量化、向量量化、预测编码、变换编码、JPEG、子带编码、小波编码、JPEG2000、分析-综合编码。
信道编码
信道是指传输信号的通道,但信号在传输过程中往往由于各种原因,在传输中会产生误码,只要接收设备能判别出1码和0码,信号就不会丢失,因此,在散字信号传输中最重要的,也就是防止误码,也就是要尽量降低误码率,因此,要在信号源的原数码序列中用某些编码,以实现自动纠错或检错的目的,进就是信道编码或纠错编码。

- 人类在信道编码上的第一次突破发生在1949年。R.Hamming和M.Golay提出了第一个实用的差错控制编码方案——汉明码。
CABAC
CABAC的发展
- 比较早流行的是 H.264/AVC ,CABAC(上下自适应二进制算术编码Context-adaptive binary arithmetic coding )是一种用于 H.264/AVC 和 HEVC 的熵编码形式。高效视频编码 (HEVC)由视频编码联合协作团队 (JCT-VC) 开发,它的编码效率有望比 H.264/AVC 提高 50%。HEVC 使用几种新工具来提高编码效率,包括更大的块和变换大小、额外的环路滤波器和高度自适应的熵编码。

CABAC的优势
- 算术编码是一种熵编码,它可以通过有效地将符号(即语法元素)映射到具有非整数位数的码字来实现接近序列熵的压缩。 在 H.264/AVC 中,CABAC 比基于 Huffman 的 CAVLC 提高了 9% 到 14%。 在 HEVC (HM-3.0) 的早期测试模型中,CABAC 比 CAVLC 提高了 5%–9%。
CABAC涉及三个主要功能
- CABAC 涉及三个主要功能:二值化、上下文建模和算术编码。
二值化
- 二值化将语法元素映射到二进制符号(bins)。二值化的方案共有7种:
- 一元码(Unary)。
- 截断一元码(TU,Truncated Unary)。
- k阶指数哥伦布编码(kth order Exp-Golomb,EGk)。
- 定长编码(FL,Fixed-Length)。
- mb_type与sub_mb_type特有的查表方式。
- 4位FL与截断值为2的TU联合二值化方案。
- TU与EGk的联合二值化方案(UEGk,Unary/kth order Exp-Golomb)。
上下文建模
- 以JM中的上下文结构体为例。
//! struct for context management
struct bi_context_type
{
unsigned long count;
byte state; //uint16 state; // index into state-table CP
unsigned char MPS; // Least Probable Symbol 0/1 CP
};
- 上下文包含两个变量:MPS,pStateIdx(count只是用于计数)。在CABAC编码的过程中会碰到需要修改这两个值的情况(如上面的状态变换),这些修改都是以上下文为单位的。
算术编码
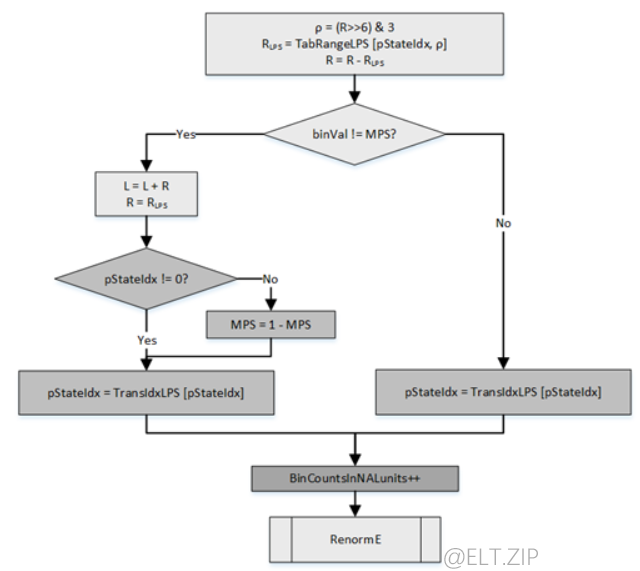
- 该过程可分为5个步骤
1.通过当前编码器区间范围R得到其量化值ρ作为查表索引,然后利用状态索引pStateIdx与ρ进行查表得出RLPS的概率区间大小。
2.根据要编码的符号是否是MPS来更新算术编码中的概率区间起点L以及区间范围R。
3.pStateIdx==0表明当前LPS在上下文状态更新之前已经是0.5的概率,那么此时还输入LPS,表明它已经不是LPS了,因此需要进行LPS、MPS的转换。
4.更新上下文模型概率状态。
5.重归一化,输出编码比特。
由上文, 编码器希望用尽可能少的数据样本找到一个(本地)解决方案。Deep- CABAC被提出。
Deep- CABAC
Deep- CABAC 的编码程序
- Deep- CABAC 按行长顺序扫描网络各层的权值参数。
- 选择一个特定的超参数β,将定义量化点集。
- 对权重值应用量化器,以最小化各自的加权率失真函数。
- 通过应用改编版本的 CABAC 压缩量化参数。
- 对网络进行重构,并对网络的精度进行测量。对于不同的超参数β重复这个过程,直到在精度和网络大小之间达到预期的平衡。
- 对一组超参数β重复该过程,直到所需的精度 vs。实现了-size 权衡。
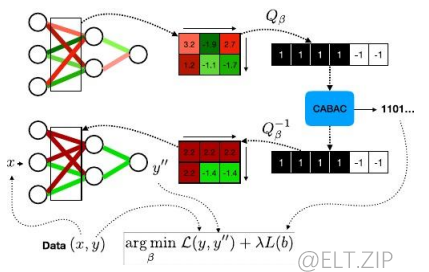
Deep-CABAC 编码器
Deep-CABAC 无损编码器
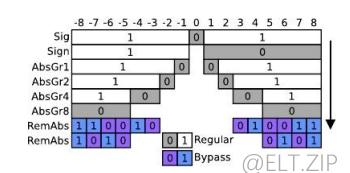
- 第一个SigFlag 决定权重元素是否是一个重要元素,即表示权值是否为 0。然后使用二进制算术编码器对这个 bin 进行编码,根据其各自的上下文模型(用灰色颜色编码)。上下文模型最初设置为 0.5(因此,权重元素为 0 或不为 0 的概率为 50%),但随着 DeepCABAC 编码更多的元素,将自动适应权重参数的本地统计数据。
- 如果元素不为 0,则根据其各自的上下文模型对符号库或 SignFlag 进行类似的编码。
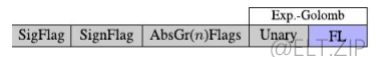
- 一系列容器被类比编码,确定元素是否大于 1,2,…,n∈n。数字 n 成为编码器的超参数。
- 剩余部分使用指数-Golomb 编码代码,其中一元部分的每个 bin 也相对于它们的上下文模型进行编码。只有固定长度的代码部分没有使用上下文模型进行编码(用蓝色颜色编码)。
Deep-CABAC 有损编码器
- 找到将量化点(或聚类中心)最优分配给每个权重参数的量化器 Q。
- 量化点:因为为大量的点找到正确的映射 Q - 1 是非常复杂的,我们用一个特定的步长Δ来约束它们彼此之间的等距离。即,每个点 qk 可以改写为 qk = ΔIk, ik∈Z。这不仅极大地简化了问题,而且也鼓励了定点表示,可以利用定点表示以较低的复杂度执行推理。
- 赋值:因此,量化器有两个可配置的超参数β = (Δ, λ),前者定义量化点的集合,后者定义量化强度。一旦给定一个特定的元组,量化器 Qβ将通过最小化加权率失真函数 将每个权重参数赋给对应的量化点 qk。
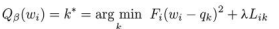
- DeepCABAC-版本1 (DC-v1):在 DC-v1 中,我们首先利用可扩展贝叶斯技术估计 FIM 的对角线。得到了每个参数的平均值μj 和标准差 σj,其中前者可以解释为其(新的)值(即 wi→μi),而后者则是它们对扰动的“鲁棒性”的度量。在估算完 fim -对角线后,我们将考虑的步长集定义如下:
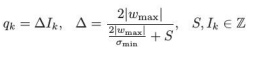
- 其中σmin 为最小标准差,wmax 为幅度值最大的参数。然后 S 是量化器的超参数,控制量化点的 “粗糙程度”。
- DeepCABAC-版本2 (DC-v2):因为版本1需要估计 FIM 的对角线,成本还是很高。考虑对整个 网 络 直 接 尝 试 寻 找 一 个 好 的 候 选 集 合 Δ∈{Δ0 , … , Δm−1}。通过应用第一轮网格搜索算法,同时应用最近邻量化方案(即λ = 0)来实现这一点。在有限的计算预算下,这种方法的优点是我们可以直接搜索更优步长集Δ。
实验
将标量 huffman、csr-huffman和 bzip2无损编码算法应用于量化网络后获得的最佳压缩结果。括号内是结果的top-1精度,括号内是通过非零参数的数量除以参数总数所获得的稀疏比。

深度压缩包括应用稀疏化技术,然后是k-Means算法,然后是CSR-Huffman熵编码器,最后是将聚类中心微调到损失函数。相比之下,我们可以通过简单地 应用DeepCABAC 获得更高精度的压缩性能,而无需对量化点进行任何后先验微调。
使用三种不同的量化器对Small-VGG网进行量化,然后使用不同的通用无损编码器对它们进行压缩。具体地,我们利用 DC-v2、加权Lloyd算法和最近邻量化器对模型进行量化。然后应用标量Huffman代码、CSR- Huffman代码 、bzip2算法和DeepCABAC的cabac组件。此外,我们还计算了量化网络的一阶熵,从而测量了网络的熵无损压缩所获得的压缩比不同。

轻易看到,CABAC 能够在所有量化版本的 Small-VGG16 网络中获得更高的压缩增益。使用 CABAC 的好处在于其固有的灵活性,它可以用于获取权重参数的先验统计数据。DeepCABAC通过定义前文所述的二值化过程,能够快速捕获最大值接近于0的单峰分布和非对称分布的统计信息。此外,也方便CABAC捕获一行中元素之间的相关性。这也很重要,因为 CABAC的估计是以自回归的方式更新的,因此,它的压缩性能也取决于扫描顺序。如上表所示,CABAC能够捕捉权重参数之间的相关性,从而将它们压缩到参数分布的一阶熵之外。与之前提出的通用熵编码器(如标量 Huffman、CSR-Huffman)相比,由于其平均码长受到一阶熵的限制,因此不可能获得比 CABAC更低的码长,因此该特性更加突出了它的优越性。
总结
- H.264/HEVC 和 H.265/HEVC 视频编码标准中采用的最先进的通用无损编码器——上下文的自适应二进制算术编码器 (CABAC),论文中提出了一种新的深度神经网络压缩算法DeepCABAC,码长更短更灵活,减少训练次数和大量数据的访问。技术一代一代更新,后浪奔涌,前浪不是沉舟或病树,而是巨人的肩膀,引领后辈,奔向更神秘的新世界。






























