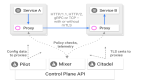
围绕于 ArchGuard,我们一直在探索适合于大多数企业的治理模式。通常来说,对于应用架构的治理来说,我们的预期目标是,对应的 架构设计 (广义上的)能被采纳和遵守。如果过程中出现有流程上的问题,导致了架构在实施过程中,架构会不断偏离预期的设计。那么,我们就会致力于匹配设计相应的规范、规则和函数,来确保后续在实施过程中是能正确的落地。
也因此,在架构治理上,我们可以用一些简单的元素来进行概括。
- 模式。寻找坏的味道,并使用好的设计来改进它。
- 规范。一个关于架构决策的文档化。
- 规则 。规范的工具化与形式化表示
于是乎,在我们的场景下,架构治理方案就可以围绕于三个要素来构建。
模式:坏的味道与好的方案
在我们的行业里,会将解决特定问题的解决方案称之为模式,如设计模式、架构模式。这些广为流传的编程模式,都是好的、最佳的实践。但是,就个人而言,而另外一类,不好的模式其实也是模式,不过,我们往往把它们称为有味道(Smell)的,代码里的是 代码坏味道 ,架构里的便是 架构的坏味道 。
在一个组织里,代码随着人员的内部流动、自定义框架的编码风格、公司级别的规范定义,使得整体的代码模式会趋向于一致。这种一致性会受到人员变更带来短期的影响,些许的高水平 “新人” 可能会带给团队一股新鲜备注;大量的新人的涌入,也会可能使得原来的好的模式被冲淡。但是呢,不论如何,替换的只是模式本身,而不是模式的存在。而坏味道本身即是与好的模式进行比较,即好的实践应该是怎样的。
也因此,在治理的第一步就是让坏味道能浮出来。它可以是通过人为地看项目代码,进而得到一些初步的结论,并基于结论构建出洞见;也可以是像 ArchGuard 一样的专家系统,可以通过 AST 从语法中分析到坏的味道,并将它们可视化出来。
规范:架构决策的文档化
规范是我们在日常的开发过程中约定俗成的标准,其本质是对于一系列架构决策的文档化。作为架构师/开发者,我们定义所有的 API 应该是怎样的?如何去处理数据?如何构建质量防护?在另种一个话题: 轻量级架构决策 里,我们定义的是架构决策应该编写出来,以格式化的文档。
好的规范的本质是 推荐 一系列的 最佳实践 。“年轻” 的开发者往往不能理解诸多实践的意义,为什么它应该这么做?不这么做会影响到什么?有时候,需要经验丰富的开发者告他们,WHY + WHAT + HOW。不过呢,在一些大型 IT 组织的里,人们往往依旧会采用 “考试” 的方式,用一种简单粗暴的方式来确保:对于什么是好的模式/实践认知是一切的。
而规范不论是明文规定,还是约定俗成,我们都可以发现,在业务繁荣或者新的加入的时候,慢慢都会被破坏。所以,我们又开始寻找一些能让规范有效力的方式。
规则:规范的工具化与形式化表示
规则从某种意义上来说,是一种规范的工具化手段。其最常见的方式是 Linter,一种基于语法树/语法结构的规则化工具。
这种规则可以是我们在学习英语时的语法规则,它是语言中高度抽象的组合关系和聚合关系的约定俗成的语言的规则,包括组合规则和聚合规则。诸如于在英语中,常见的句型可以是:主语-谓语-宾语-宾语补足语(英语四级没过,这简直是噩梦)。围绕于这些规则,便可以构建一系列的自动化检测工具。
这样的工具,也可以是我们使用 Java 编写企业应用时,用的 Checkstyle;又或者是使用 TypeScript 编写前端应用时,用的 ESLint。从这一点上来说,它们就是对于常见规则的形式化。
治理:匹配模式,展示问题,规则化与演进
模式、规范、规则都依赖于编写工具的人,他应该即是一个架构上的专家,又需要精通 编码 + 语言 本身。又或者是两者一起进行结对,才能设计一个如此的系统。
回到编程来治理问题上,从过程上来说,我们治理架构问题的方式是:
- 设计、寻找对应的规范(即最佳实践)
- 人为识别代码中的模式,随后通过编写代码匹配,即规则。
- 通过可视化 + 分析的方式,展示出代码中的问题。
- 将规范规则化,并配合上度量指标
- 构建适应度函数,指导系统进行演进。
以 ArchGuard 中的 SQL 规则检查为例,如下是代码中的 SQL(经过修改):
override fun getById(systemId: Long): SystemInfo? {
val sql = "select * from system_info where id=:systemId"
return jdbi.withHandle<Long, Nothing> {
it.createQuery(sql)
.bind("systemId", systemId)
.mapTo(SystemInfo::class.java)
.firstOrNull()
}
}
从 SQL 性能等角度来说,这里的 select * 应该是禁止的。但是呢,从识别的难度来说,它是存在的,我们需要结合着语法分析的结果,即 createQuery 的被调用 + 参数表中对应值的存在,才能将 SQL 从代码中解析出来。展开来说,在这个案例里,因为想治理的是 SQL,所以我们所做的是:
- 寻找通用的 SQL 规范。
- 结合人为查阅的方式,从 SQL 规范中寻找第一个易于实现的案例
- 编写代码,从语法树抽取 SQL,和对应的 SQL 规则
- 将所有的问题展示到一起
从治理的层面来说,最大的难点在于 模式逃逸 —— 即开发者可能根据识别的模式,修改代码的实现方式,导致度量无用。不过,这就是另外一个关于度量如何改进的问题。