












Selenium自动化测试的主要目的是为了取代和加快手动测试的进程。为了显著提高测试执行的速度,我们可以选择使用不同类型的等待、Web定位器(Locator)、浏览器偏好,来优化并提升Selenium测试的基础设施。

下面,我们将主要从速度和性能两个方面,向您介绍Selenium Web测试各项优秀实践,以便您能够更好地加快测试并获取测试结果。
加速Selenium测试的优秀实践
随着软件产品的持续更新,维护和升级Selenium测试的过程会变得越来越复杂。不过,无论被测场景如何不同,下面有关Selenium的基本测试步骤都是相似的:
- 使用本地或远程的Selenium WebDriver去打开被测的URL。
- 使用诸如XPath、CssSelector、以及Linktext等恰当的WebSelenium定位器,来定位所需的各种WebElement。
- 对已定位的WebElement执行各项必要的操作,并测试页面上的断言。
- 释放WebDriver所使用的资源。
尽管Selenium测试的效率在很大程度上,取决于测试的方法和内部结构,但是我们可以总结出如下加快执行Selenium测试用例的各种优秀实践:
选择合适的Web定位器
Selenium中的Web定位器往往被认为是任何测试场景的基本构建块。为了自动化与任何Web元素的交互,我们首先应该选对可定位WebElement的Web定位器,然后再对相应的元素执行适当的操作。其中,XPath、CSS Selector、Name、LinkText、Partial LinkText、TagName、以及ClassName都是在Selenium中被广泛使用的Web定位器。我们通常可以将其与find_element或find_elements方法一起使用。
那么,究竟哪一款Web定位器在Selenium中能够最快地定位到元素呢?其实,ID才是最快的Web定位器,毕竟Selenium WebDriver中的ID定位器,对于页面上的每个元素来说都是唯一的。ID定位器可以返回与指定值(或字符串)相匹配的WebElement。如果页面上存在多个具有相同ID的元素,那么document.getElementById()将返回第一个匹配的元素。主流Web浏览器都优化了document.getElementById()方法,因此我们能够以更快的速度,从DOM处提供WebElement。
如果WebElement并没有ID属性,那么请使用NAME属性。而如果WebElement既没有ID、又没有NAME属性,那就应该使用CSS选择器(Selector)的Web定位器。CSS引擎在所有主流浏览器中都是一致的,并且能够通过Selenium中的CSS选择器,来调优它们的性能,以提供更快的元素识别和更少的测试执行时间。因此,您在使用此类特定的Web定位器时,也会鲜少遇到浏览器的兼容性问题。同时,CSS选择器也能适应IE等老旧的浏览器。
此外,与XPath相比,CSS选择器提供了更好的可读性。我们甚至可以说,XPath是最慢的Web定位器,当您从一个浏览器移至另一个浏览器时,很可能会遇到XPath的一致性问题。因此,仅当您无法在Selenium WebDriver中选用其他可靠的Web定位器时,才建议使用XPath来定位Web元素。
小结一下,上述Web定位器按照执行速度从快到慢依次是:ID、NAME、CSS选择器、以及XPath。
使用更少的Web定位器
既然您已经确定了最适合加速Selenium测试的Web定位器,下一步就应该将定位器的数量保持在最低限度了。
如前所述,我们每次需要使用find_element(By)或find_elements(By)方法,来定位所需的Web元素,以执行对DOM树的访问。那么对DOM树的访问次数越多,Selenium脚本的执行时间就会越长。因此,如果您以Selenium脚本的最佳执行速度为目标的话,有必要使用更少的Web定位器。这样,我们不但能够提高测试脚本的可读性,还可以最大限度地减少维护脚本所需的时间。
尽量避免Thread.sleep()
现代网站与Web应用往往会使用AJAX(异步的JavaScript和XML)在网页上动态加载内容。因此,页面上的WebElement可能会以不同的时间间隔被加载,这将对尚未处于DOM中的元素造成执行上的困难。
在此,我建议您通过监控document.readyState的状态,来检查DOM状态。document.readyState的完成标志着页面上的所有资源都已加载完毕,因此我们可以开始对页面上存在的WebElement进行相关操作。
由于测试代码中的几秒钟等待,都会增加页面上资源加载所需的延迟,因此我们需要尽量避免使用Thread.sleep(sleep_in_miliseconds)。Selenium中的Thread.sleep()方法将会让代码的执行暂停指定的时间间隔。
/* Pauses test execution for specified time in milliseconds */
Thread.sleep(5000);
如上述代码段所示,我们添加了5秒的等待时间。如果页面元素在指定的持续时间之内(例如2秒钟)就已完成了加载,那么剩下3秒的等待就不必要地增加了测试的执行时间。由于页面的加载时间往往取决于诸如:服务器负载、页面设计、缓存、以及网络带宽等各种外部参数,因此我们无法预测页面的加载时间。可见,无论网页的状态如何,Thread.sleep()方法都会执行固定时间的休眠,因此为了加速Selenium测试,我们需要避免使用它。
重用现有的浏览器实例
目前,能够与Selenium一起使用的所有自动化测试框架,都可以通过提供注释,来加快测试的开发和执行。同时,注释还有助于执行具有不同输入值的测试。当然,只有根据测试的要求,使用正确的注释集,才能加快Selenium测试。
以下是被各个主流自动化测试框架所广泛使用的注释列表:
自动化测试框架 | 注释 |
JUnit [Selenium Java] | @BeforeClass, @Before, @Test, @After, @AfterClass, @Ignore |
TestNG [Selenium Java] | @BeforeSuite, @BeforeTest, @BeforeClass, @BeforeMethod, @Test, @AfterMethod, @AfterClass, @AfterTest, etc. |
NUnit [Selenium C#] | [SetUp], [TearDown], [Test], [TestCase], [OneTimeSetUp], [OneTimeTearDown], [Ignore], [Category], etc. |
XUnit [Selenium C#] | [Theory], [InlineData], [Fact], etc. |
有时候,您可能需要在相同的浏览器和操作系统类型的组合中,反复运行某个或某组测试。此时,如果您在每个测试的开始时,都创建一个新的Selenium WebDriver实例,显然会增加测试执行的额外开销。
Selenium的JUnit
下面是Selenium的JUnit中注解的执行顺序:
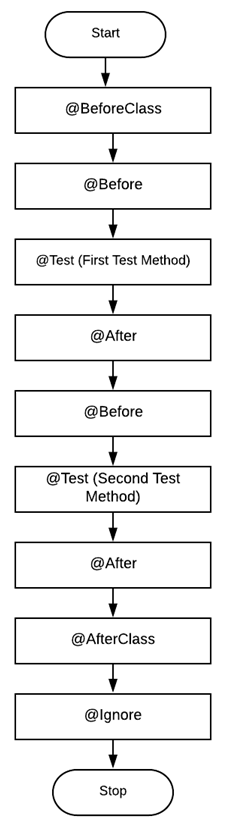
在使用JUnit框架的Selenium自动化测试中,Selenium WebDriver实例是在@Before注释下实现的SetUp方法中创建的。已创建的实例是在@After注解下实现的TearDown方法中被销毁的。
Selenium的TestNG
下面是Selenium的TestNG中注解的执行顺序:
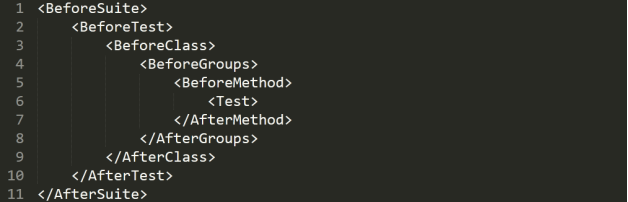
同理,对于Selenium中的TestNG测试,SetUp方法是在@BeforeMethod注解下实现的,而TearDown方法是在@AfterMethod注解下实现的。
在浏览器和操作系统的组合上运行一系列测试
下面,我们来讨论不同的框架在同一个浏览器和操作系统组合上执行三个测试的情况:
JUnit 框架
测试 - 1 @Before 注解下的 setUp() -> Test-1 -> @After 注解下的 tearDown()
测试 - 2 @Before 注解下的 setUp() -> Test-2 -> @After 注解下的 tearDown()
测试 - 3 @Before 注解下的 setUp() -> Test-3 -> @After 注解下的 tearDown()
TestNG 框架
测试 - 1 @BeforeMethod 注解下的 setUp() -> Test-1 -> @AfterMethod 注解下的 tearDown()
测试 - 2 @BeforeMethod 注解下的 setUp() -> Test-2 -> @AfterMethod 注解下的 tearDown()
测试 - 3 @BeforeMethod 注解下的 setUp() -> Test-3 -> @AfterMethod 注解下的 tearDown()
如上表所示,在每个测试场景都会在注释之后创建和销毁浏览器实例。
在JUnit和TestNG框架中重用浏览器实例
相反,我们可以使用适当的注释在脚本之间共享相同的浏览器实例:
JUnit 框架
测试 - 1、测试 - 2 和测试 -3 @BeforeClass 注解下的 setUp() -> Test-1、Test-2 和 Test-3 -> @AfterClass 注解下的 tearDown()
TestNG 框架
测试 - 1、测试 - 2 和测试 -3 @BeforeTest(或@BeforeClass)注解下的setUp() -> Test-1、Test-2和Test-3 -> @AfterTest(或@AfterClass)注解下的tearDown()
在这种情况下,所有测试场景都会使用同一个浏览器实例,并且一旦所有测试执行完成后,该实例就会被销毁。当然,如果测试必须在不同的浏览器和操作系统组合上运行时,则不能使用相同的技术,而必须在每个测试场景之后创建和销毁测试组合。
使用Selenium进行自动化测试的显式等待
Selenium中的隐式等待被应用于测试脚本中的所有Web元素。而隐式等待的主要缺点在于您无法在元素可见、可点击、可选择等条件下执行等待。与此同时,Selenium中的显式等待则允许您对页面上存在的WebElement执行有条件的等待。例如,如果某个被指定的WebElement在显式等待所规定的持续时间内可见,那么就会触发ElementNotVisibleException。如果已定位的元素是可点击的,那么elementToBeClickable方法将返回一个WebElement。
WebDriverWait和ExpectedConditions类的组合可被用于在WebElements上执行显式等待。显式等待的好处在于它是在代码层面,而非远程Selenium部分上运行的。显式等待无需等到设定时间的结束,而是在满足指定条件时,便可立即退出等待。如果设定的条件一旦找到了WebElement,就会将该元素作为结果予以返回。如果WebElement在DOM中并不存在,即使条件中指定时间已过,它也会触发TimeoutException。
在下面的代码段中,我们对visibilityOfElementLocated条件执行了5秒钟的显式等待。如果ID = 'element'的WebElement在5秒内被找到,那么该显式等待就会退出,并返回所需的WebElement。
Java
/* Trigger an explicit wait of 5 Seconds */
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(5));
WebElement element = wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("element"))
由于只要找到元素就可以访问WebElement,因此实际的等待时间可能会少于设定的等待时间,那么显式等待的测试脚本的性能会更好,也会使得Selenium测试运行得更快。
创建原子性和自主式测试脚本
无论测试场景有多么复杂,我们都需要将复杂的场景分解成为多个“独立和原子性”的测试用例。
像TestNG之类的自动化测试框架能够支持通过诸如dependsOnMethods(用于各种方法)和dependsOnGroups(用于各个组)等注释,来声明测试方法之间的显式依赖关系。但是,只有当您希望在测试方法之间共享数据和状态时,才应该在Selenium测试脚本中使用测试依赖项。
同时,由于原子性测试可被用于故障检测,因此我们需要通过保持测试的简短和原子态,来减少维护测试的工作量。可以说,有了原子性的保证,我们不但可以最大限度地减少测试的依赖性,而且有助于隔离测试中出现的问题,并加快Selenium测试的整体效率。
在Selenium自动化中利用并行测试
Selenium中的并行测试可以让您在不同的测试环境中,同时运行相同的测试。如果您计划使用内部Selenium Grid进行分布式测试,那么您可以利用Selenium Grid 4所提供的功能,来加速测试场景的执行。
根据所测场景的不同,您可以选择“类”级别或“方法”级别中的任何一种开展并行化测试。而此类测试主要可以对如下三个方面予以增强:
- 对测试场景分组
- 测试场景的参数化
- 选择基于云的Selenium Grid
对测试场景分组
随着更多的测试文件和测试方法被添加,测试套件的复杂性会成倍增加。为了最大限度地减少测试套件在实现和维护上的复杂性,我们需要根据被测的功能,对测试进行分组。
正如下面对TestNG测试用例进行分组所展示那样,我们创建了两个测试组(即Search和ToDo),并在“方法”级别并行执行。TestNG中的线程计数属性允许您通过指定在测试执行期间要创建的最大线程数,来并行开展测试。
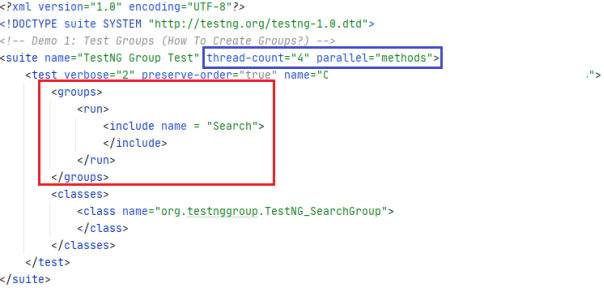
可见,分组测试场景降低了维护测试套件的复杂性,同时也加快了执行时间。当然,这些都取决于为实现并行化而选择的方法。
使用Selenium 4(而不是Selenium 3)
Selenium 4是Selenium自动化框架中最受期待的版本之一。目前,Selenium 4的最新版本为4.0.0-beta-1。它在如下方面进行了显著的改进和增强:
- 改进和优化了Selenium Grid
- 对Selenium WebDriver予以了W3C标准化
- 增强了Selenium 4的IDE
- 引入了Chrome DevTools
- 引入了相对定位器(Relative Locators)
总地说来,Selenium 4中的增强功能可以在加速Selenium测试方面发挥重要的作用。
过去,Selenium 3使用JSON有线协议,在Web浏览器和测试代码之间进行通信。这会导致使用W3C协议对API请求进行编、解码而产生额外的开销。而Selenium 4直接使用WebDriver W3C协议,从而加快了与Web浏览器的通信。这种架构更改不但加快了Selenium测试,而且提高了测试的稳定性。
下图展示的是在Selenium 4中新引入的相对定位器。当它在访问临近的特定WebElement时,非常实用。

与页面上的每个WebElement使用find_element()和find_elements()方法不同,相对定位器通过与TagName(在Selenium 4的Java中)结合使用,可以让您以更快的速度访问到相对WebElement。因此,在您必须访问相对于DOM元素的WebElement场景时,相对定位器可以加速Selenium测试。
值得一提的是,从Selenium 3升级到Selenium 4是无缝的,您应当检查版本,以确认是否真的能够利用Selenium 4所提供的特性和功能,来加速Selenium测试。
使用基于云的Selenium Grid进行自动化测试
当涉及到网格的可扩展性和可靠性时,在本地Selenium Grid上并行运行测试,存在着一个严重的缺陷:它并不适用于在大量浏览器、操作系统和设备的组合上,并行地执行针对大型Web应用的多个测试套件。
所谓云端的Selenium测试,是指在可靠且可扩展的、基于云服务的Selenium Grid上并行开展测试,因此它有助于加快Selenium测试。由下面显示的testng.xml文件示例可知,该并行是在“测试”级别上实现的。即:每个<test>标记都在单独的线程中运行。
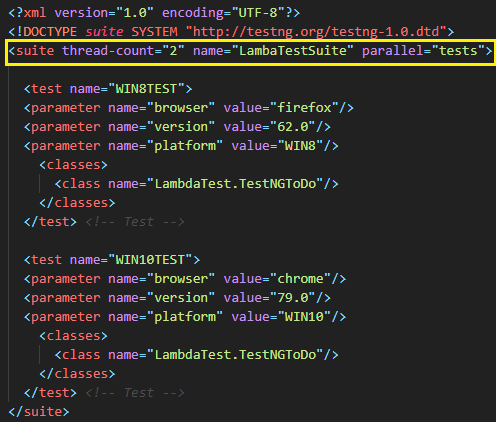
从下面的执行快照中可以看出,这两个测试都是在基于云端的Selenium Grid上并行运行的。
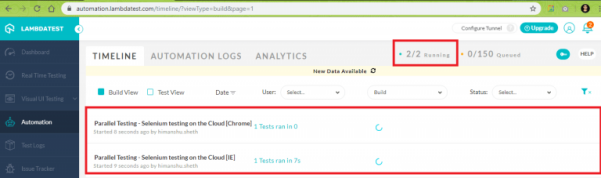
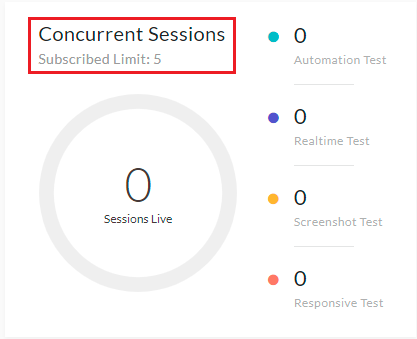
使用由基于云端的Selenium Grid所提供的功能,您可以并行运行“N”个测试(此处的“N”取决于您计划支持的“最大并发会话数”),进而加快Selenium测试。
通过禁用网页上的图像来实现更快的页面加载
一旦创建了Selenium WebDriver实例,Selenium中的driver.get()方法将被用于打开被测页面。网页的加载速度往往取决于页面的组成。如果页面上有大量的图像的话,那么页面的加载时间就会增加。
因此,通过使用特定于浏览器的设置,您可以按需禁用在相应的Web浏览器中加载图像,以加快网页的加载速度。
运行Selenium脚本时,禁用Chrome中的图像加载
如下代码段展示了如何实现在Chrome中禁用图像的加载,以加快Selenium测试:
Java
package com.disableimages;
import org.openqa.selenium.*;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
import org.openqa.selenium.firefox.FirefoxProfile;
import org.testng.annotations.AfterTest;
import org.testng.annotations.Test;
import java.util.HashMap;
public class test_disable_image_demo
{
String test_url = "https://www.amazon.com";
WebDriver driver = null;
(enabled=true, priority = 1)
public void test_disable_images_chrome() throws InterruptedException
{
ChromeOptions options =new ChromeOptions();
HashMap<String, Object> prefs = new HashMap<String, Object>();
prefs.put("profile.managed_default_content_settings.images", 2);
options.setExperimentalOption("prefs", prefs);
driver = new ChromeDriver(options);
driver.get(test_url);
driver.manage().window().maximize();
Thread.sleep(5000);
}
public void tearDown()
{
if (driver != null)
{
driver.quit();
}
}
}
在上述代码实现中,我们通过将Firefox的首选项--permissions.default.image设置为2,以禁用从Amazon处加载图像。该方法对于需要加载大量图像的测试页面的情况,非常有效。
使用数据驱动测试进行参数化
在某些情况下,您需要跨多个浏览器和操作系统的组合,或针对不同输入的组合,运行特定的场景测试。众所周知,对测试方法中的值进行硬编码,并不是一个好的习惯。您应该使用参数化,来针对大量的数据集运行测试。目前,所有主流的自动化框架,包括:用于Selenium C#的MSTest、NUnit等,用于Selenium Java的JUnit、TestNG等,以及用于Selenium Python的PyTest等,都支持参数化测试。
针对那些必须在多个测试组合(或测试输入)中运行相同测试的需求,您可以通过诸如TestNG之类的自动化测试框架,让testng.xml来传递参数,进而在“测试”级别实现并行的参数化测试,以显著地加快Selenium测试,并提高测试的覆盖率。
按需使用无头(Headless)浏览器和驱动程序
运行Selenium自动化测试的一个目的是,检查并验证底层UI元素的交互。对此,您需要通过在非无头(non-headless)模式下调用浏览器驱动程序,来验证交互。
同时,无头浏览器允许您在没有浏览器或任何其他GUI下,运行浏览器UI测试。目前,Chrome、Firefox等流行的浏览器都可以在无头模式下运行。由于跨浏览器测试是在后端运行的,因此无头测试提高了跨浏览器测试的整体性能。请参考如下代码段:
Java
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("build", "your build name");
capabilities.setCapability("name", "your test name");
capabilities.setCapability("platform", "Windows 10");
capabilities.setCapability("browserName", "Chrome");
capabilities.setCapability("version","89.0");
capabilities.setCapability("headless",true);
当您不打算检查通过测试脚本、以及相应的浏览器驱动程序去实现的UI交互时,就可以使用无头浏览器测试。可以说,没有浏览器UI和无头浏览器的各种UI,都可以起到加速Selenium测试的效果。
目前,此类主流无头浏览器(或驱动程序)包括:HtmlUnit、Splash、PhantomJS、TrifleJS、ZombieJS、以及SimpleBrowser。其中,基于HtmlUnit的HtmlUnitDriver是Selenium WebDriver无头浏览器的轻量级实现。HtmlUnitDriver是与Chrome和Firefox类似的浏览器驱动程序,不过它并不提供GUI。因此,您可以灵活地在主流浏览器的无头版本、以及HtmlUnitDriver上,执行跨浏览器测试。
用Java编写的HtmlUnit浏览器能够支持AJAX和JavaScript的处理。同时,它也提供了部分渲染的功能。下面展示的是用于创建HtmlUnitDriver实例,并使用它在Selenium中执行浏览器测试的代码片段:
JavaScript
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/* Create a new instance of the HtmlUnitDriver */
WebDriver driver = new HtmlUnitDriver();
/* Perform necessary actions as per the desired test requirement */
.
.
/* Release the resources held by HtmlUnitDriver */
driver.quit();
而PhantomJS是另一种流行的、基于JavaScript API的无头浏览器选择项。它使用QtWebKit作为后端,并为流行的Web标准提供了诸如JSON、Canvas、SVG、以及DOM等原生的处理支持。PhantomJS 2.1是其最新的稳定版本,其中集成了GhostDriver。不过, PhantomJS项目(https://github.com/ariya/phantomjs)目前处于暂停状态。
PhantomJS不但可以被用于Windows、Linux和macOS X等流行平台,而且能够被广泛地用于诸如:无头Web测试、页面自动化、屏幕截图、以及网络监控等用例中。
下面显示的是创建PhantomJS驱动程序实例,并使用它在Selenium中执行浏览器测试的代码片段:
JavaScript
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
/* Create a new instance of the PhantomJS Driver*/
WebDriver driver = new PhantomJSDriver();
/* Perform necessary actions as per the desired test requirement */
.
.
/* Release the resources held by PhantomJS Driver */
driver.quit();
根据测试要求,我们在上述代码中使用了无头浏览器测试,来加速Selenium测试。当然,除了HtmlUnitDriver和PhantomJSDriver之外,Chrome和Firefox等无头版本的浏览器,也可被用于在Selenium测试中加速,并获取更高的准确性。
小结
在编写Selenium测试时,影响性能的主要因素之一便是测试的运行速度。其中,基于云端的Selenium Grid和Selenium并行测试是加速该过程的两种主要方法。同时,我们也介绍了如何通过采用不同的语言和自动化测试框架,来加速Selenium测试,提高测试性能与覆盖率、以及交付出更好的产品质量。
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:How To Speed Up Selenium Test Cases Execution,作者:Himanshu Sheth
















