摘要:本文整理自顺丰大数据研发工程师覃立辉在 5月 21 日 Flink CDC Meetup 的演讲。主要内容包括:
- 顺丰数据集成背景
- Flink CDC 实践问题与优化
- 未来规划
一、顺丰数据集成背景

顺丰是快递物流服务提供商,主营业务包含了时效快递、经济快递、同城配送以及冷链运输等。
运输流程背后需要一系列系统的支持,比如订单管理系统、智慧物业系统、以及很多中转场、汽车或飞机上的很多传感器,都会产生大量数据。如果需要对这些数据进行数据分析,那么数据集成是其中很重要的一步。
顺丰的数据集成经历了几年的发展,主要分为两块,一块是离线数据集成,一块是实时数据集成。离线数据集成以 DataX 为主,本文主要介绍实时数据集成方案。
2017 年,基于 Jstorm + Canal 的方式实现了第一个版本的实时数据集成方案。但是此方案存在诸多问题,比如无法保证数据的一致性、吞吐率较低、难以维护。2019 年,随着 Flink 社区的不断发展,它补齐了很多重要特性,因此基于 Flink + Canal 的方式实现了第二个版本的实时数据集成方案。但是此方案依然不够完美,经历了内部调研与实践,2022 年初,我们全面转向 Flink CDC 。

上图为 Flink + Canal 的实时数据入湖架构。
Flink 启动之后,首先读取当前的 Binlog 信息,标记为 StartOffset ,通过 select 方式将全量数据采集上来,发往下游 Kafka。全量采集完毕之后,再从 startOffset 采集增量的日志信息,发往 Kafka。最终 Kafka 的数据由 Spark 消费后写往 Hudi。
但是此架构存在以下三个问题:
- 全量与增量数据存在重复:因为采集过程中不会进行锁表,如果在全量采集过程中有数据变更,并且采集到了这些数据,那么这些数据会与 Binlog 中的数据存在重复;
- 需要下游进行 Upsert 或 Merge 写入才能剔除重复的数据,确保数据的最终一致性;
- 需要两套计算引擎,再加上消息队列 Kafka 才能将数据写入到数据湖 Hudi 中,过程涉及组件多、链路长,且消耗资源大。
基于以上问题,我们整理出了数据集成的核心需求:

- 全量增量自动切换,并保证数据的准确性。Flink + Canal 的架构能实现全量和增量自动切换,但无法保证数据的准确性;
- 最大限度地减少对源数据库的影响,比如同步过程中尽量不使用锁、能流控等;
- 能在已存在的任务中添加新表的数据采集,这是非常核心的需求,因为在复杂的生产环境中,等所有表都准备好之后再进行数据集成会导致效率低下。此外,如果不能做到任务的合并,需要起很多次任务,采集很多次 Binlog 的数据,可能会导致 DB 机器带宽被打满;
- 能同时进行全量和增量日志采集,新增表不能暂停日志采集来确保数据的准确性,这种方式会给其他表日志采集带来延迟;
- 能确保数据在同一主键 ID 下按历史顺序发生,不会出现后发生的事件先发送到下游。

Flink CDC 很好地解决了业务痛点,并且在可扩展性、稳定性、社区活跃度方面都非常优秀。
- 首先,它能无缝对接 Flink 生态,复用 Flink 众多 sink 能力,使用 Flink 数据清理转换的能力;
- 其次,它能进行全量与增量自动切换,并且保证数据的准确性;
- 第三,它能支持无锁读取、断点续传、水平扩展,特别是在水平扩展方面,理论上来说,给的资源足够多时,性能瓶颈一般不会出现在 CDC 侧,而是在于数据源/目标源是否能支持读/写这么多数据。
二、Flink CDC 实践问题与优化

上图为 Flink CDC 2.0 的架构原理。它基于 FLIP-27 实现,核心步骤如下:
- Enumerator 先将全量数据拆分成多个 SnapshotSplit,然后按照上图中第一步将 SnapshotSplit 发送给 SourceReader 执行。执行过程中会对数据进行修正来保证数据的一致性;
- SnapshotSplit 读取完成后向 Enumerator 汇报已读取完成的块信息;
- 重复执行 (1) (2) 两个步骤,直到将全量数据读取完毕;
- 全量数据读取完毕之后,Enumerator 会根据之前全量完成的 split 信息, 构造一个 BinlogSplit。发送给 SourceRead 执行,读取增量日志数据。
问题一:新增表会停止 Binlog 日志流
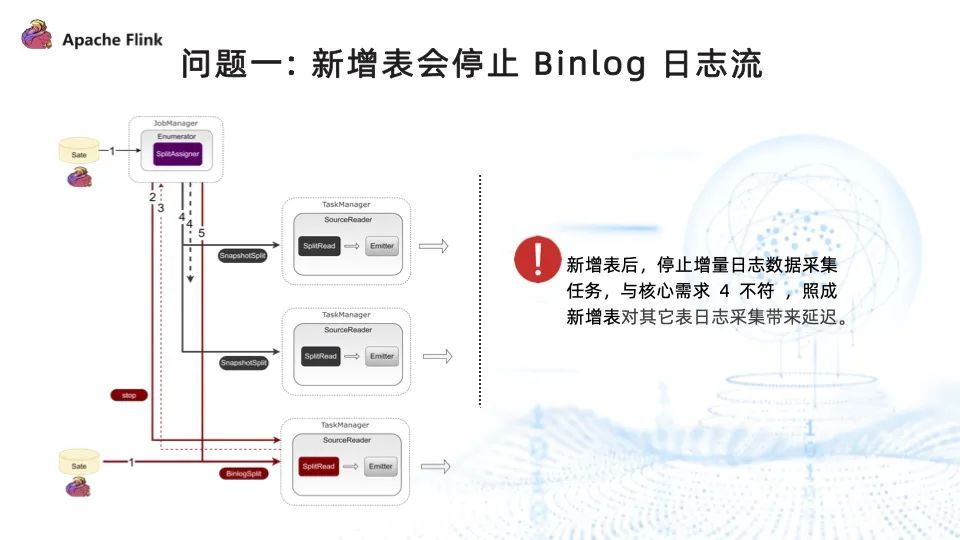
在已存在的任务中添加新表是非常重要的需求, Flink CDC 2.0 也支持了这一功能。但是为了确保数据的一致性,Flink CDC 2.0 在新增表的流程中,需要停止 Binlog 日志流的读取,再进行新增表的全量数据读取。等新增表的全量数据读取完毕之后,再将之前停止的 Binlog 任务重新启动。这也意味着新增表会影响其他表的日志采集进度。然而我们希望全量和增量两个任务能够同时进行,为了解决这一问题,我们对 Flink CDC 进行了拓展,支持了全量和增量日志流并行读取,步骤如下:

- 程序启动后,在 Enumerator 中创建 BinlogSplit ,放在分配列表的第一位,分配给 SourceReader 执行增量数据采集;
- 与原有的全量数据采集一样,Enumerator 将全量采集切分成多个 split 块,然后将切分好的块分配给 SourceReader 去执行全量数据的采集;
- 全量数据采集完成之后,SourceReader 向 Enumerator 汇报已经完成的全量数据采集块的信息;
- 重复 (2) (3) 步,将全量的表采集完毕。
以上就是第一次启动任务,全量与增量日志并行读取的流程。新增表后,并行读取实现步骤如下:

- 恢复任务时,Flink CDC 会从 state 中获取用户新表的配置信息;
- 通过对比用户配置信息与状态信息,捕获到要新增的表。对于 BinlogSplit 任务,会增加新表 binlog 数据的采集;对于 Enumerator 任务,会对新表进行全量切分;
- Enumerator 将切分好的 SnapshotSplit 分配给 SourceReader 执行全量数据采集;
- 重复步骤 (3),直到所有全量数据读取完毕。
然而,实现全量和增量日志并行读取后,又出现了数据冲突问题。

如上图所示, Flink CDC 在读取全量数据之前,会先读取当前 Binlog 的位置信息,将其标记为 LW,接着通过 select 的方式读取全量数据,读取到上图中 s1、s2、 s3、s4 四条数据。再读取当前的 Binlog 位置,标记为 HW, 然后将 LW 和 HW 中变更的数据 merge 到之前全量采集上来的数据中。经过一系列操作后,最终全量采集到的数据是 s1、s2、s3、s4 和 s5。
而增量采集的进程也会读取 Binlog 中的日志信息,会将 LW 和 HW 中的 s2、s2、s4、s5 四条数据发往下游。
上述整个流程中存在两个问题:首先,数据多取,存在数据重复,上图中红色标识即存在重复的数据;其次,全量和增量在两个不同的线程中,也有可能是在两个不同的 JVM 中,因此先发往下游的数据可能是全量数据,也有可能是增量数据,意味着同一主键 ID 到达下游的先后顺序不是按历史顺序,与核心需求不符。
针对数据冲突问题,我们提供了基于 GTID 实现的处理方案。

首先,为全量数据打上 Snapshot 标签,增量数据打上 Binlog 标签;其次,为全量数据补充一个高水位 GTID 信息,而增量数据本身携带有 GTID 信息,因此不需要补充。将数据下发,下游会接上一个 KeyBy 算子,再接上数据冲突处理算子,数据冲突的核心是保证发往下游的数据不重复,并且按历史顺序产生。
如果下发的是全量采集到的数据,且此前没有 Binlog 数据下发,则将这条数据的 GTID 存储到 state 并把这条数据下发;如果 state 不为空且此条记录的 GTID 大于等于状态中的 GTID ,也将这条数据的 GTID 存储到 state 并把这条数据下发;
通过这种方式,很好地解决了数据冲突的问题,最终输出到下游的数据是不重复且按历史顺序发生的。

然而,新的问题又产生了。在处理算法中可以看出,为了确保数据的不重复并且按历史顺序下发,会将所有记录对应的 GTID 信息存储在状态中,导致状态一直递增。
清理状态一般首选 TTL,但 TTL 难以控制时间,且无法将数据完全清理掉。第二种方式是手动清理,全量表完成之后,可以下发一条记录告诉下游清理 state 中的数据。
解决了以上所有问题,并行读取的最终方案如下图所示。
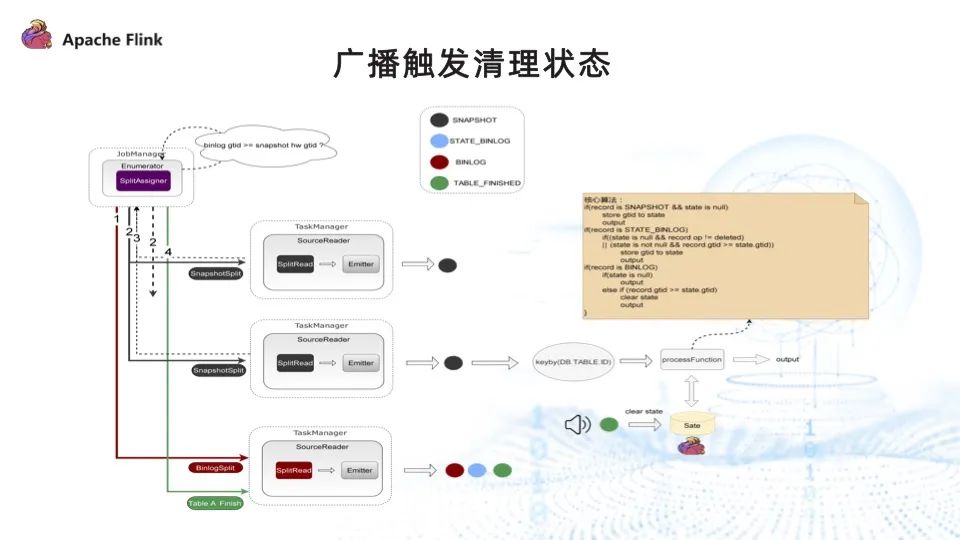
首先,给数据打上四种标签,分别代表不同的状态:
- SNAPSHOT:全量采集到的数据信息。
- STATE_BINLOG:还未完成全量采集, Binlog 已采集到这张表的变更数据。
- BINLOG:全量数据采集完毕之后,Binlog 再采集到这张表的变更数据。
- TABLE_FINISHED:全量数据采集完成之后通知下游,可以清理 state。
具体实现步骤如下:
- 分配 Binlog ,此时 Binlog 采集到的数据都为 STATE_BINLOG 标签;
- 分配 SnapshotSplit 任务,此时全量采集到的数据都为 SNAPSHOT 标签;
- Enumerator 实时监控表的状态,某一张表执行完成并完成 checkpoint 后,通知 Binlog 任务。Binlog 任务收到通知后,将此表后续采集到的 Binlog 信息都打上 BINLOG 标签;此外,它还会构造一条 TABLE_FINISHED 记录发往下游做处理;
- 数据采集完成后,除了接上数据冲突处理算子,此处还新增了一个步骤:从主流中筛选出来的 TABLE_FINISHED 事件记录,通过广播的方式将其发往下游,下游根据具体信息清理对应表的状态信息。
问题二:写 Hudi 时存在数据倾斜

如上图,Flink CDC 采集三张表数据的时候,会先读取完 tableA 的全量数据,再读取tableB 的全量数据。读取 tableA 的过程中,下游只有 tableA 的 sink 有数据流入。
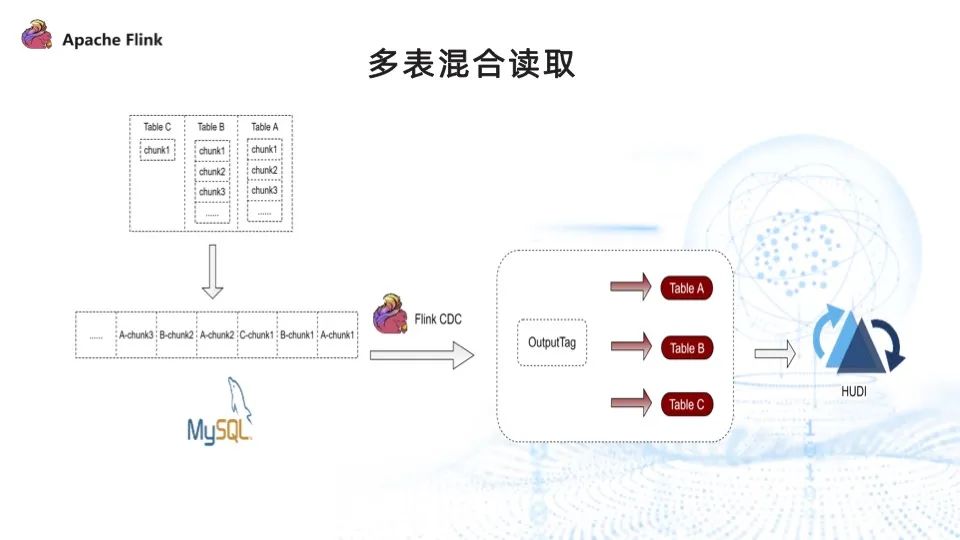
我们通过多表混合读取的方式来解决数据倾斜的问题。
引入多表混合之前,Flink CDC 读取完 tableA 的所有 chunk,再读取 tableB 的所有 chunk。实现了多表混合读取后,读取的顺序变为读取 tableA 的 chunk1、tableB 的 chunk1、tableC 的 chunk1,再读取 tableA 的 chunk2,以此类推,最终很好地解决了下游 sink 数据倾斜的问题,保证每个 sink 都有数据流入。
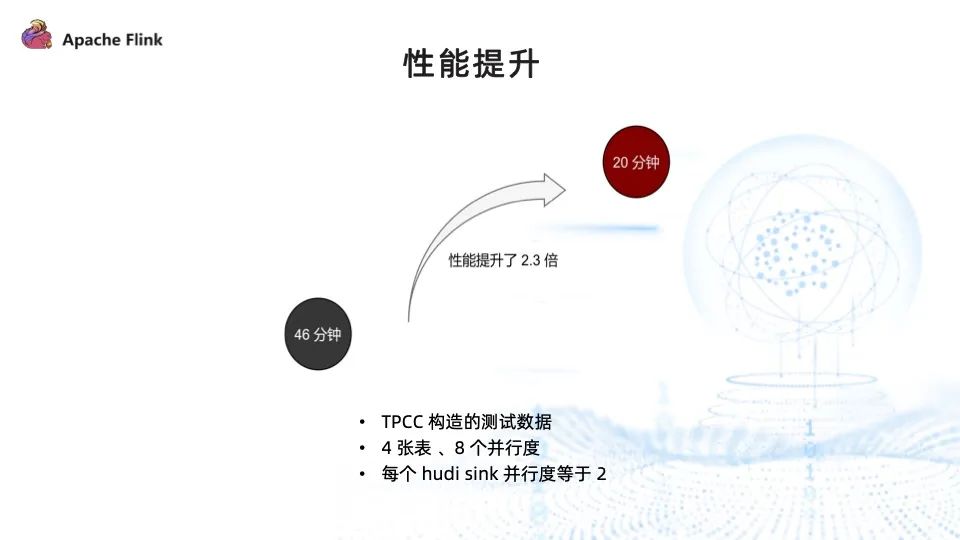
我们对多表混合读取的性能进行了测试,由 TPCC 工具构造的测试数据,读取了 4。张表,总并行度为 8,每个 sink 的并行度为 2,写入时间由原来的 46 分钟降至 20 分钟,性能提升 2.3 倍。
需要注意的是,如果 sink 的并行度和总并行度相等,则性能不会有明显提升,多表混合读取主要的作用是更快地获取到每张表下发的数据。
问题三:需要用户手动指定 schema 信息

用户手动执行 DB schema 与 sink 之间 schema 映射关系,开发效率低,耗时长且容易出错。
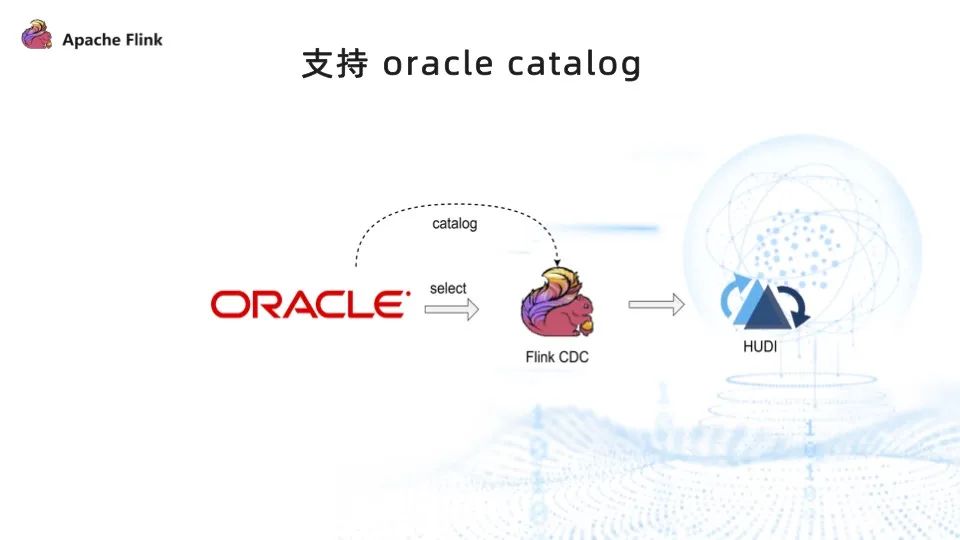
为了降低用户的使用门槛,提升开发效率,我们实现了 Oracle catalog ,让用户能以低代码的方式、无需指定 DB schema 信息与 sink schema 信息的映射关系,即可通过 Flink CDC 将数据写入到 Hudi。
三、未来规划

- 第一, 支持 schema 信息变更同步。比如数据源发生了 schema 信息变更,能够将其同步到 Kafka 和 Hudi 中;支持平台接入更多数据源类型,增强稳定性,实现更多应用场景的落地。
- 第二, 支持 SQL 化的方式,使用 Flink CDC 将数据同步到 Hudi 中,降低用户的使用门槛。
- 第三, 希望技术更开放,与社区共同成长,为社区贡献出自己的一份力量。
提问&解答
Q1断点续传采集如何处理?
断点续传有两种,分为全量和 Binlog。但它们都是基于 Flink state 的能力,同步的过程中会将进度存储到 state 中。如果失败了,下一次再从 state 中恢复即可。
Q2MySQL 在监控多表使用 SQL 写入 Hudi 表中的时候,存在多个 job,维护很麻烦,如何通过单 job 同步整库?
我们基于 GTID 的方式对 Flink CDC 进行了拓展,支持任务中新增表,且不影响其他表的采集进度。不考虑新增表影响到其他表进度的情况下,也可以基于 Flink CDC 2.2 做新增表的能力。
Q3顺丰这些特性会在 CDC 开源版本中实现吗?
目前我们的方案还存在一些局限性,比如必须用 MySQL 的 GTID,需要下游有数据冲突处理的算子,因此较难实现在社区中开源。
Q4Flink CDC 2.0 新增表支持全量 + 增量吗?
是的。
Q5GTID 去重算子会不会成为性能瓶颈?
经过实践,不存在性能瓶颈,它只是做了一些数据的判断和过滤。