如果你用来管理所有开发项目的平台,企业内部文件的共享知识库,还有业务、销售、和行政部门合作的项目平台,突然都宕机了,甚至厂商告诉你,要2周后才能修复,这段期间,所有数据无法存取,也没有备份版本可用,你会怎么办?这正是775家企业在Atlassian四月大宕机事件,所遭遇的处境。

Atlassian是20岁的澳洲老牌软件开发商,旗下拥有知名的企业项目管理平台Jira,企业文件协作平台Confluence,还有看板协作工具Trello。许多大型企业都采用Jira来管理公司的敏捷开发项目,甚至Atllassian还推出给非技术团队用的敏捷项目平台,不少企业用于业务、销售、商业分析团队的敏捷管理。
根据Atlassian今年3月财报数据,超过75%的财富五百强企业都是他们的企业用户,全球更有23万家企业采用,光是用Jira Service Management服务来进行企业内部大型系统开发项目生命周期管理的企业,就超过了4万家,不少是大型企业,更有178家企业每年授权订阅费用超过百万美元,相当于有数千人订阅授权数的规模,甚至订阅数最多的一家超大型企业,订阅了5万个授权。Atlassian一年光是订阅费用的营收就超过了13亿美元。
虽然Atlassian没有公开这次事故受影响的企业名单,只披露受影响企业家数是775家,但其中有400家是活跃使用的企业。根据国外媒体采访受影响企业的结果,小则有150个授权,大则有订阅多达4千个授权的企业。根据非官方估算,775家受影响企业下,累积受到冲击的个人使用者超过了5万人。这起事件也大大重挫了Atlassian市值,从宕机事件到完全复原这2周期间,Atlassian股价足足下滑了近2成,后续到5月下旬仍持续下滑中。
Atlassian拥有十多年SaaS服务的运维经验,6年SRE经验,以及云上业界标准常见的灾备和恢复计划,都无法事前发现,及时阻止4月大宕机,无法在99.9%服务水准承诺(SLA) 承诺的8.76小时内复原,甚至有不少企业迟迟等到14天后,才能打开自己的敏捷项目数据。
为何这家云服务厂商,SRE运维专家,无法避免这次大宕机的发生?
大宕机事件发生过程追追追,一只删除程序的误用而酿灾
回到事件发生当天,4月5日早上,这一天是Atlassian年度大会Team22的前一天,Atlassian要淘汰一些旧版App,在4月5日这一天删除这些旧版应用的程序。正是这支删除旧版AP的脚本程序造成了这起宕机事故。早在实际执行删除之前,Atlassian测试过这只脚本没有问题,甚至在正式环境中试删除了30个顾客所用的旧版Ap,也没有发生问题。
提出删除申请的业务团队,提供了一份目前还在使用这些旧版AP的企业顾客名单,作为脚本自动执行删除的目标清单。但是,关键的出错环节是,他们提供的ID清单,不是直接提供要删除AP的ID,而是给了这些待删除AP ID所在的网站ID清单,再告诉执行删除指令的工程团队,要删除这些网站ID中的老旧AP。但是,双方发生了沟通落差,工程团队误以为,这批网站ID就是要删除的清单,直接套用到删除脚本来执行。到了4月5日,这只脚本删除的不是旧版AP,而是删除了那些还在使用旧版AP的企业的全部网站数据。
酿灾起因:想删除老旧App,为何反而删除顾客全站数据?
要了解误删的影响,得先知道用APP ID来删除,和使用网站ID来删除,有何差别?这得从Atlassiant技术架构说起。
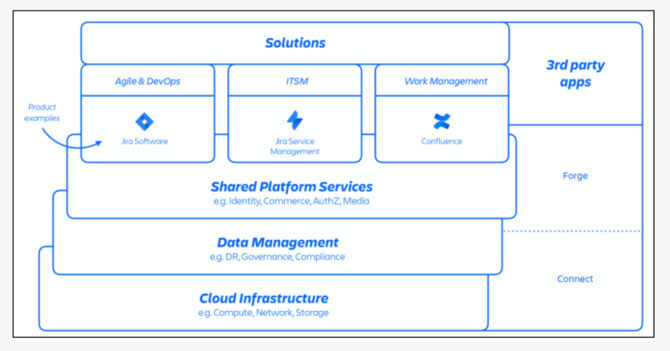
Atlassiant所有服务都部署在AWS上,在数据储存上和服务架构上,都采取了高度分布式架构,以及容易组合再利用的微服务架构,并在云上基础架构上来设计了书架管理层和共用的平台服务层,也通过API串连到许多第三方厂商的应用。所有微服务都布建在AWS的容器化服务上,更搭配了一套PaaS服务,称为Micros,来提供内部微服务的自动化构建。从公共服务部署、基础架构资源调度、数据储存管理、合规性管制都靠这个平台自动完成。
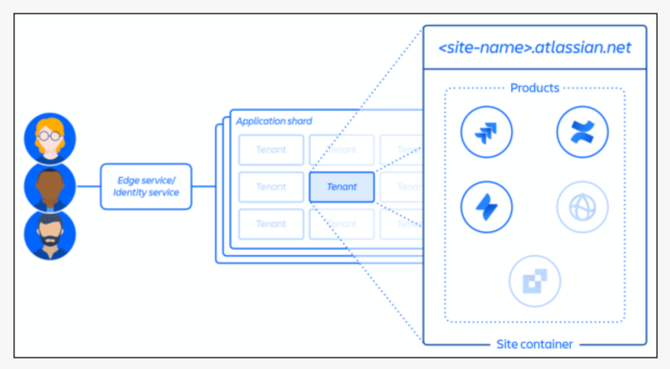
另外在管理架构上,Atlassian采取了多租户架构,并以网域作为单一用户的最基本管理单位,这就是网站ID。企业要指定一个网址作为登入Atlassian服务的主要入口网站,也把他们所订阅的所有Atlassian服务,都登记到这个网址下。Atlassian也称这个网址是一个网站容器,用来容纳属于这个企业顾客的所有数据、配置和所用的APP。网站ID就是用来识别一家企业的网站容器的代号。
Atlassian的技术架构采取了分布式架构,不只在云端基础架构采取分布式架构来提高可用性,在应用系统层次,也采取了多租户微服架构设计来兼顾弹性和可用性。
图片来源/Atlassian
Atlassian的网站ID(企业顾客网站URL网址)也是一个网站容器,将一家企业的所有数据、配置和所用的APP,都登记到这个网站ID来管理。
图片来源/Atlassian
Atlassian也用这个网站ID来作为识别一个企业用户帐号的代号,所有与这家企业有关的数据、表单、帐单,也都用这个网站ID来作为识别客户的索引,例如企业顾客提出支持工单时,这张工单就会用网站ID作为所属客户的代号。
当Atlassian业务单位提出了一份要删除老旧APP的网站ID,希望删除他们所用的老旧AP。但是负责执行的团队,误以为要删除这一批AP ID所在的网站ID。这就不只是删除了AP,而是删除了采用这些AP的企业所拥有的全部AP和数据。
4月5日7:38,开始执行旧版AP删除脚本,工程团队也没有接到任何通知,警告有企业顾客的网站遭删除,因为这是一只获得合法授权的删除。但是,不到10分钟,就有企业发现自己所用的Jira网站失联,提出第一张宕机支持工单。删除脚本在8点多执行完毕,事后调查,一口气删除了775家企业所拥有的883个网站。受影响的产品包括了Jira 产品系列、Confluence文件协作平台、Atlassian Access登入机制、Opsgenie 事件应变服务,甚至是网站状态查询页Statuspage。这些受影响企业,不只无法连线登入,甚至连要检视所用服务的运作状态页都打不开。
接连有不少顾客提出宕机工单,Atlassian决定在8:17启动重大事件管理流程,也组织了跨部门事件管理团队,找来工程部门、客户支持团队、项目管理团队和对外沟通部门,联手展开事故调查,每3小时开会一次,并在8:24将事件状态提升到「危急」状态。不到20分钟,工程团队就发现了事故的根本原因,是脚本误删数据而非黑客攻击,9:03时首度在服务状态网页中揭露发生宕机事故。
找出事故原因之后,下一步就是要尽快解决问题,恢复顾客所订阅的服务。Atlassian开始尝试建立一套标准化的复原方法,但却发现,要复原一个遭到删除的网站,得建立新网站、复原每个下游产品、服务及还原数据所需的资料,还须与各网站所用第三方生态系厂商重建连结,相关复原步骤高达70个。他们才发现,要复原这些网站的复杂性远超过他们的想像,所以在12:38时将这起事件的严重等级提升到「最高等级」,这时距离事故发生,已经超过了5小时。
Atlassian宕机后不久,越来越多顾客在Twitter上抱怨,因为Jira是许多企业用来管理敏捷开发项目的主要平台,无法使用,就等于无法进行敏捷项目的开发,连要打开项目工单来知道该处理哪些工作都没有办法。这股抱怨声浪越来越大,越来越多人发现,这起宕机事件持续时间越来越久,超过了8、9个小时,Atlassian所承诺的99.9%可用性承诺已经失守。
不少受影响的企业用户在Twitter上抱怨,他们连要向Atlassian通报宕机问题,或是申请支持工单都做不到,也有人是发出申请后,迟迟没有得到官方回应,仿佛Atlassian的服务窗口失联一样,无法通过原本的线上管道来接触。
直到事故发生后17个小时,Atlassian才发电子邮件通知受影响顾客,并开始打电话联系,对他们说明,而这时已经引起不少媒体的关注,开始大举报导这起大宕机事件。
直到事件发生后快2天,Atlassian才发布第一份宕机事件的官方公开声明。而Atlassian的合作伙伴,则还等到事故后第2天快结束时,才开始接到通知。因为宕机事故迟迟无法解决,Atlassian共同创办人也以个人名义发信,亲自向顾客说明复原进度缓慢的原因。
4月8日,也就是事件发生后的第四天,Atlassian终于成功复原了第一家受影响顾客的网站。可是,复原团队这才发现,采用第一版复原方法,需要48小时才能恢复一批网站,因为需要大量人工操作,只能分批复原,若要全面复原剩下的网站,还需要3周时间,所以,也开始改良复原程序。同一天,Atlassian也对所有工程部门实施代码冻结,禁止任何异动,来降低顾客数据不一致的变更风险
过了一天,4月9日开始启用第二套复原方法,将原本70道程序,大幅减少到只剩下30道程序。第二套做法重建顾客网站时,不是建立新的网站ID,而是直接沿用了顾客的旧网站ID,因此,大幅减少新旧ID比对的步骤,也不用再逐一与第三方程式供应商沟通,节省大量时间。这时有771个误删网站,可以改用第二套方法来复原。
不过,第二套方法还是需要大量手动操作,直到4月11日,Atlassian工程团队打造出自动化复原工具,来加速第二套方法的时间,才将复原时间缩短到12小时,这时候,Atlassian才在工单中向顾客承诺,可以在事故后2周内复原。
到了4月14日,采用第一版复原方法复原的网站达到112个网站,不再继续使用。Atlassian也打造出复原网站的完整验证脚本,不再需要人工验证,更加快了其他网站的复原速度,到了4月16日10:05 ,就完成所有网站的复原和自动验证,但还没经过顾客确认。隔天21:48,最后一位受影响顾客完成复原确认。Atlassian就在4月18日1:00宣布,受影响网站100%复原。这时,距离事故发生已经近14天,不过,宣布当时,仍有57个网站,因为复原资料的时间点过早,比原订「当机前5分钟」的复原时间点,还要更早,还需要追补后来异动的资料。
到了4月底,Atlassian发布了四月大宕机事件的完整事后分析报告。