从去年年底到现在,随着疫情的反复,很多城市的一码通系统出现了故障,这证明一码通系统在技术上还存在一些不足,所以本次分享将介绍如何利用 PAST 问题解决框架,从架构和设计方面研究和解决这些问题。
01 PAST 问题解决框架
PAST 的第一个单词 P 是 Problem,代表的是问题。当遇到问题的时候,不要急于进入方案阶段,应该先进行调研和分析,确认问题到底是什么。这也是 Eric Evans 的《领域驱动设计》中提到的,理解目标领域并将所学到的知识融入到软件中是领域驱动设计(DDD)的首要任务,这强调了问题的重要性。
第二个单词 A 是 Analysis,代表的是分析矛盾。导致问题产生的原因可能有多种,在这个过程中要先找出主要矛盾和次要矛盾,然后针对这些原因或者矛盾 找到对应的 Solution,也就是 S 。此时,可以先列举方案,然后 在 Tradeoff 阶段进行权衡和取舍 。在进行软件或者架构设计的实践中,大多数时候都在做权衡,而不是决策,所以需要对设计进行取舍,最终制定出方案。根据不同的方案,可能要顺势而为,在最后阶段进行成效的 review。
02 Problem 问题
下图为某一城市的一码通系统。假设产生地为西虹市,图 1(左)是正常情况下的一码通系统,包含姓名、证件号和二维码,其中二维码分为绿码、红码或者黄码。另外,图 1(左)的下方还包含疫苗接种信息以及 15 天内的核酸检测结果。由图可知,一码通的主入口集成了众多的功能。图 1(右) 为周一早晨一码通系统的故障显示页面,显示一码通系统空白,此外,还出现了核酸检测结果不显示任何信息等问题。
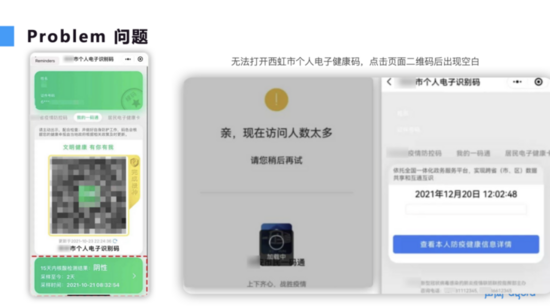
■图 1
03 Analysis分析
3.1 主要矛盾
在分析阶段需要针对这些问题尝试进行调查和分析,找到问题的原因和矛盾。此时主要是大量市民需要在周一早上从不同场合打开一码通系统的核酸证明页面,与一码通系统不能同时满足大并发量之间的矛盾。一码通系统无法打开,导致用户反复刷新,系统用户请求飙增。此时,请求可能直接到达后台甚至服务层,进而进入分布式 cache 或者数据库,这造成 后台服务器的流量突增,对应的网络带宽增加。
3.2 架构分析
接下来进一步分析架构和设计,从数据层面来说,可能没有形成很好的缓存机制,很多查询请求都直接进入服务器甚⾄数据库,造成了缓存的击穿,很多流量被“怼”到了数据库。从变化频率弹性来说,一码通系统的问题在于, 个⼈码页⾯聚合了太多的内容,没有基于容器的集群搭建和熔断机制 。从 CFR 跨功能需求来说,问题在于, 开发人员在进行服务设计时没有考虑服务器的峰值限制,在系统测试设计阶段没有做好性能和压⼒测试,导致系统最终超过了负荷 。从⽹络瓶颈来说,理论上来说 1000M ⽹卡的传输速度是 125MB/s,100M ⽹卡的传输速度是 12.5MB/s,在当天出现故障的愿意可能是网络带宽不够支撑,导致网络上的瓶颈。
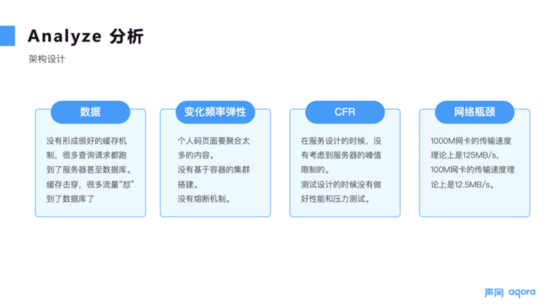
图 2
04 Solution 方案枚举
完成分析之后需要制定问题解决方案,在方案枚举过程中,不要着急表达自己的倾向,应该先确定备选方案,并对其进行排列和组合。
4.1 基于数据分层架构
针对数据来说,可以分为 UI 层个性数据、缓存数据和 DB 全量数据。缓存设计遵循就近原则,数据离用户越近越好,这样性能可能就越好。按照这种原则,基于数据的分层架构实际上是一种漏斗型架构,它是以对象和集合为单位的一种缓存策略,能够减少对下层系统的访问。针对每一层数据,可以采用不同的方法进行处理。
对于 UI 层个性数据,就一码通系统出现的问题而言,当用户点击查询核酸结果时,可以令按钮不可用,从功能上禁止重复提交,比如设置 15 秒以后才能打开,这样就会阻断流量。对于缓存数据,可以在浏览器进行缓存,比如把常见的图片、静态文件、脚本缓存起来,这可能只需要有限的资源就可以让请求进入对应的后续阶段。此外,还可以利用 CDN 缓存分发网络。数据从 UI 层到达应用层或者服务端,可以采用 NGINX 或者中间服务器进行代理,比如在服务器端为频繁查询,但修改较少的数据建立缓存。
对于 DB 全量数据,主要应专注于存储,而不是进行复杂的运算。数据库厂商可以支持数据库限流,当达到一定的流量时。返回对应的异常码会告诉用户不可用,对应的服务端根据情况可以进行熔断处理,而不至于让数据库一直处理信息而不能响应,进而导致整个应用崩溃。另外,在当天一码通系统出现问题的时候,建立不同的微服务对核酸报告进行动态的弹性扩容是一个不错的选择,划分手段就是 DDD。
 ■图 3
■图 3
4.2 业务变化频率和弹性
在创业过程中或在一些比较复杂的系统中,可以做一些体验设计,对系统业务能力进行划分。要基于上下文,根据系统业务能力判断是否从单体转为微服务。另外,还要考虑业务变化频率和弹性,比如核酸检测是近期使用非常频繁的功能,将其放至主页,进入系统后可以直接查询。事实也证明,当时西虹市在疫情出现几天后就把核酸检测这个功能直接放到页面上,这间接说明了业务变化频率对系统的设计是很重要的。
图 4
4.3 CFR – 测试设计与性能
针对 CFR 来说,图 5 展示了有指导意义的测试四象限。Q1 象限从技术出发支撑团队的整个测试,包括单元测试和组件测试,可以帮助团队尽快发现问题。Q2 象限从业务角度支撑团队测试,更侧重于发现功能和业务上的问题。Q3 象限从业务角度来评价产品,主要包括一些探索性测试。Q4 象限从技术角度来评价产品,包括性能测试、压力测试以及安全测试。可以将 4 个象限分为质量交付(Q1、Q2、Q3)和运维(Q1、Q2、Q3、Q4)两条指引。随着 DevOps 的盛行,往往把这四个象限是结合起来,制定有效的测试策略,使测试和开发在项目中能够落地。
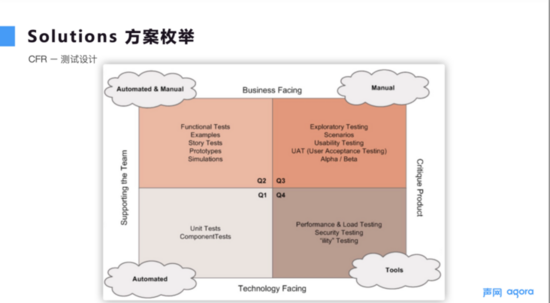
图 5
从性能设计方案来说,在并发量很高的情况下,比如一秒钟有 100 个请求,那么是否要把 100 个请求直接放到服务端和数据库,进行 100 次查询?显然不是,解决方案应该是把这些请求合并到一起。可以通过限时器或者定时器的形式把请求合到一起,在查询之后找到对应的 API 对应进行返回。这实际上是批量查询的变种。但如果请求较少,就没有必要进行请求合并了,应根据情况配置。还有一种方法叫限流,这时可以采用 令牌桶算法 ,令牌桶的容量是⼀定的,令牌是以⼀定的速率加进去的,如果桶已经满了,就不再继续添加。也可以采用 漏桶算法 ,不管当前有多少并发数,通过出⽔速率保证后台程序接到的请求数是⼀定的,可以达到限流的⽬的。这种方法不适用于一码通系统事件的情况。 中间件限流方法 是 Tomcat 使⽤ maxThreads 来实现限流,也可以通过 NGINX 的 limit_req_zone 和 burst 来实现速率限流,NGINX 的 limit_conn_zone 和 limit_conn 两个指令可以控制并发连接的总数。
4.4 网络瓶颈
从网络瓶颈来说,为了防止网络堵塞情况发生,可以尝试把访问方式由 HTTP 变成 TCP,例如访问 Redis 缓存,这种情况采⽤ RESP ⽅式。还可以使⽤更⾼档次的⽹卡,例如采⽤ DNS 负载均衡,使多个 IP 对应同⼀个域名。
05 Tradeoff 权衡和取舍
做软件就是做权衡。具体来说,前端落地后,客户端缓存、浏览器缓存、CDN 缓存等都可以开始运行,首先访问服务器,这里的服务器包含对应的 NGINX 或者负载均衡器,流量接下来到达应用层和服务层,如果此阶段流量较大,可以多线进行性能优化或者高性能的 RPC,也可以添加缓存。然后可以进入微服务框架。
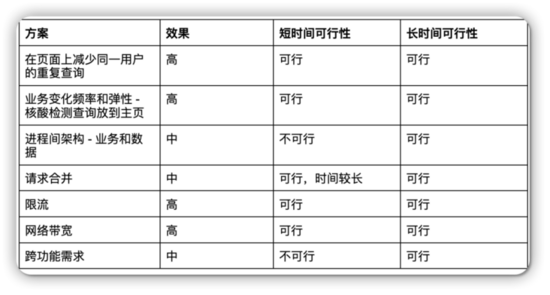
回到缓存部分,数据访问层可能包含 Redis 等,一些频繁访问但不经常变的数据就可以缓存到这里,通过请求合并或者查询减少 I/O。在存储层,数据库比较注重全量数据,如果数据库压力比较大,可以考虑分库和分表。根据不同的数据情况,甚至不同的人、不同的区,都可以建立自己的数据库来进行访问。从基础设施来说,系统要能够支持快速的扩容,如果把业务变化频率弹性考虑进去,那么云原生是不可缺少的。最后列出一个方案仅供参考。
答疑环节
1、如何带领和管理初创企业的技术团队?
要想带领团队,首先应该确定团队的方向,也就是项目愿景。确定愿景之后才有了目标,然后根据实际情况,确认支撑这些目标完成所需要的人员技能要求。其次,团队要进行能力提升,因为要完成业务目标,需要对应的能力输出。另外,如果团队人员比较多,还要有团队规范,使公司或者项目的战略流程化,流程工具化。对于组织来说,我认为还要进行不停的学习尝试,应该从客户的角度来解决其痛点。
2、一码通系统的 CDN 设计有什么原则?
一般情况下,在配置的时候,要明确有哪些是能够缓存起来的。比如,可以把不经常访问也不经常变化的数据放到 CDN 缓存中,具体要根据业务数据的情况来决定。
3、请求如何合并?
在 Java 中有 feature 功能可以引入请求。比如,1 秒钟有 100 个请求,引入请求之后可以将其分为 10 份,通过线程池一秒内遍历 10 次。具体可以把请求分别添加至线程池中,然后线程池定时触发调用请求。feature 功能使请求从数据库返回之后,能够找到对应的 request。对于这些问题,JavaSpring 中已经有比较成熟的方案。