假设你想教孩子区分苹果和橙子。有多种方法可以做到这一点。你可以让孩子触摸这两种水果,让他们熟悉形状和柔软度。你还可以向她展示苹果和橙子的多个例子,以便他们可以直观地发现差异。这个过程的技术等价物被称为机器学习。
机器学习教计算机解决特定问题,并通过经验变得更好。这里讨论的示例是一个分类问题,其中机器被赋予各种标记示例,并期望使用它从标记样本中获得的知识来对未标记样本进行标记。机器学习问题也可以采用回归的形式,其中期望根据已知样本及其解决方案来预测给定问题的实值real-valued解决方案。分类Classification和回归Regression被广泛称为监督学习supervised learning。机器学习也可以是无监督unsupervised的,机器识别未标记数据中的模式,并形成具有相似模式的样本集群。机器学习的另一种形式是强化学习reinforcement learning,机器通过犯错从环境中学习。
分类
分类是根据从已知点获得的信息来预测一组给定点的标签的过程。与一个数据集相关的类别或标签可以是二元的,也可以是多元的。举例来说,如果我们必须给与一个句子相关的情绪打上标签,我们可以把它标记为正面、负面或中性。另一方面,我们必须预测一个水果是苹果还是橘子的问题将有二元标签。表
1 给出了一个分类问题的样本数据集。
在该表中,最后一列的值,即贷款批准,预计将基于其他变量进行预测。在接下来的部分中,我们将学习如何使用 Python 训练和评估分类器。
年龄 | 信用等级 | 工作 | 拥有房产 | 贷款批准 |
35 | 好 | 是 | 是 | 是 |
32 | 差 | 是 | 不 | 不 |
22 | 一般 | 不 | 不 | 不 |
42 | 好 | 是 | 不 | 是 |
表 1
训练和评估分类器
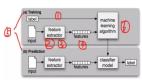
为了训练分类器classifier,我们需要一个包含标记示例的数据集。尽管本节不涉及清理数据的过程,但建议你在将数据集输入分类器之前阅读各种数据预处理和清理技术。为了在 Python 中处理数据集,我们将导入 pandas 包和数据帧DataFrame结构。然后,你可以从多种分类算法中进行选择,例如决策树decision tree、支持向量分类器support vector classifier、随机森林random forest、XG boost、ADA boost 等。我们将看看随机森林分类器,它是使用多个决策树形成的集成分类器。
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
classifier = RandomForestClassifier()
#creating a train-test split with a proportion of 70:30
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
classifier.fit(X_train, y_train) # 在训练集上训练分类器
y_pred = classifier.predict(X_test) # 用未知数据评估分类器
print("Accuracy: ", metrics.accuracy_score(y_test, y_pred)) # 用测试计划中的实际值比较准确率- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
虽然这个程序使用准确性作为性能指标,但应该使用多种指标的组合,因为当测试集不平衡时,准确性往往会产生非代表性的结果。例如,如果模型对每条记录都给出了相同的预测,而用于测试模型的数据集是不平衡的,即数据集中的大多数记录与模型预测的类别相同,我们就会得到很高的准确率。
调整分类器
调优是指修改模型的超参数hyperparameter值以提高其性能的过程。超参数是可以改变其值以改进算法的学习过程的参数。
以下代码描述了随机搜索超参数调整。在此,我们定义了一个搜索空间,算法将从该搜索空间中选择不同的值,并选择产生最佳结果的那个:
from sklearn.model_selection import RandomizedSearchCV
#define the search space
min_samples_split = [2, 5, 10]
min_samples_leaf = [1, 2, 4]
grid = {‘min_samples_split’ : min_samples_split, ‘min_samples_leaf’ : min_samples_leaf}
classifier = RandomizedSearchCV(classifier, grid, n_iter = 100)
# n_iter 代表从搜索空间提取的样本数
# result.best_score 和 result.best_params_ 可以用来获得模型的最佳性能,以及参数的最佳值
classifier.fit(X_train, y_train)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
投票分类器
你也可以使用多个分类器和它们的预测来创建一个模型,根据各个预测给出一个预测。这个过程(只考虑为每个预测投票的分类器的数量)被称为硬投票。软投票是一个过程,其中每个分类器产生一个给定记录属于特定类别的概率,而投票分类器产生的预测是获得最大概率的类别。
下面给出了一个创建软投票分类器的代码片段:
soft_voting_clf = VotingClassifier(
estimators=[(‘rf’, rf_clf), (‘ada’, ada_clf), (‘xgb’, xgb_clf), (‘et’, et_clf), (‘gb’, gb_clf)],
voting=’soft’)
soft_voting_clf.fit(X_train, y_train)- 1.
- 2.
- 3.
- 4.
这篇文章总结了分类器的使用,调整分类器和结合多个分类器的结果的过程。请将此作为一个参考点,详细探讨每个领域。