作者 | Jialin Liu, Mengyuan Chao, Jian Li, Wei Peng, Sixiang Ma, Wei Xu, Run Yang, Xin Chen
RayRTC 是字节基础架构组与字节 AML 组共同合作,在内部 RTC(Realtime Text Classification)文本训练平台上基于 Ray 进行的下一代 Serverless ML 的探索。RTC 文本分类平台是一个一站式的 NLP 服务平台,包括了数据预处理,标注,模型训练,打分,评估,AutoML 以及模型推理等机器学习全流程。目前字节内各大产品,包括抖音,TikTok,头条,西瓜,番茄等都有使用该平台提供的相关自然语言能力。RayRTC 通过算法与系统的协同设计及 Serverless 等技术为 RTC 提供了性能和资源利用率的极致优化,并由此抽象出一套通用的 Serverless ML 框架,目前已在字节内部机器学习平台上部署上线。
RayRTC 的核心计算引擎是 Ray,最早是 UC Berkeley 的一个针对强化学习所设计的大规模分布式计算框架。Ray 的作者 Robert Nishihara 和 Philipp Moritz 在此基础上成立了 Anyscale 这家公司。开源项目千千万,能成功商业化并在硅谷乃至整个 IT 届产生颠覆性影响的凤毛麟角。Anyscale 的创始人中包括 Ion Stoica,这位罗马尼亚籍教授上一家公司是跟他的学生 Matei Zaharia 以 Spark 技术为基础成立的 Databricks 。Spark 和 Ray 分别诞生于大数据和机器学习时代,前者已经在工业界得到广泛应用,后者也逐渐引起越来越多的公司在不同业务场景进行探索。字节美研计算团队自 2020 年末开始接触 Ray,2021 年开始在不同场景小范围试验。RTC 文本分类平台是第一个大规模上线的 Ray 应用场景,在 RayRTC 的设计过程中,有不少第一手的经验值得分享。本文从 RayRTC 所遇到的实际问题出发,对 Ray 在字节的实践进行介绍。
第一次接触 Ray 的读者可能会问,除了明星创始人团队,深度贴近当前 ML 需求的产学研支持,Ray 这套框架到底有哪些吸引人的地方?
首先是以 Ray 为底座可以非常轻松构建完整机器学习完整生态,如下图所示:
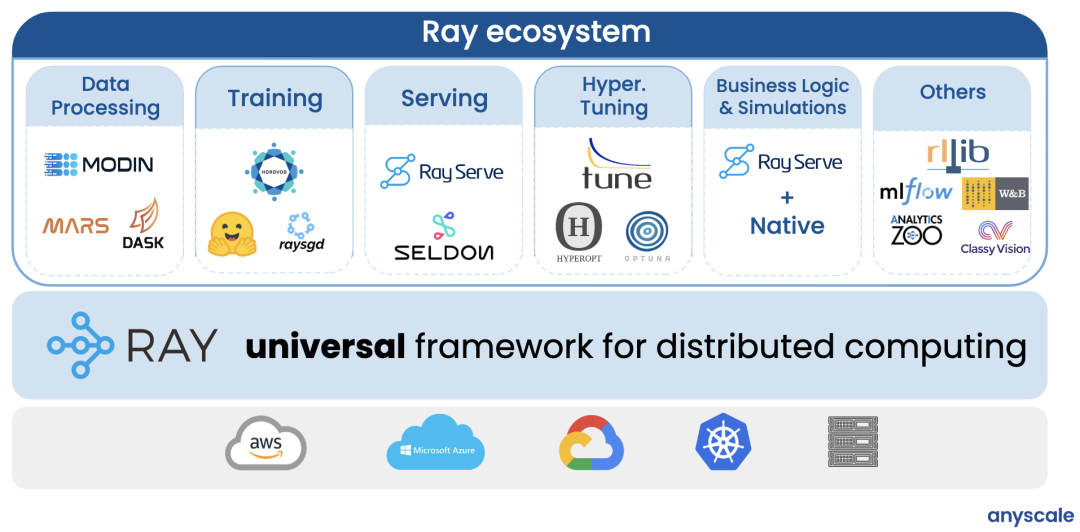
机器学习的研发人员往往不仅需要关注算法本身,在实际的生产环境中,各个环节所涉及的工程量和运维量也不容小觑。不少研究表明,工程师们有 80-90%的时间和精力投入在了算法之外的数据处理,全流程打通等。Ray 社区在近几年的演进中,不断吸收业界领先的理念,积极地与其他开源社区和各大厂商进行合作交流。以 Ray 为计算引擎的上层生态的丰富度是别的开源生态中不常见的。比如大数据处理方面,有 Intel 设计的 RayDP,将 Spark 无缝集成到 Ray 中,通过 Ray 的 Actor 拉起 Spark 的 executor,利用 Ray 的分布式调度实现资源细粒度的调控。这样做的好处在于以 Spark 为大数据引擎的机器学习应用中,通过 Ray 可以将 Spark 产生的 dataframe 以 ML Dataset 的形式直接从内存传给下游的机器学习框架,比如 PyTorch。而 Ray 的生态里的其他组件,比如超参训练(Ray Tune)和推理服务(Ray Serve),则进一步补足了训练阶段后续的一系列工程需求。研发人员可以抛开繁琐的上线部署流程,实现一键分布式以及一键部署。
Ray 的另一个显著优势是其简单通用的 API ,只需在一段函数上加入ray.remote 的装饰器,便可将一个单机程序变成分布式执行单元,如下所示:
#declare a Ray task
@ray.remote
def fun(a):
return a + 1
#submit and execute a Ray task
fun.remote()
#declare a Ray actor
@ray.remote
class Actor():
def fun(slef, a):
return a+1
actor = Actor.remote()
#execute an actor method
actor.fun.remote()
Ray 中最基础的概念包括 Task 和 Actor,分别对应函数和类。函数一般是无状态的,在 Ray 里被封装成 Task,从而被 Ray 的分布式系统进行调度;类一般是有状态的,在 Ray 里被映射成一个 Actor。Actor 的表达性更强,能覆盖大多数的应用程序子模块。基于 Actor 和 Task,Ray 对用户暴露了资源的概念,即每个 actor 或 task 都可以指定运行所需要的资源,这对异构的支持从开发人员的角度变得非常便利。比如:
@ray.remote(num_cpus=1, num_gpus=0.2):
def infer(data):
return model(data)
当 task 在被提交执行的时候,Ray 的调度器会去找到一个满足指定资源需求的节点。在此同时 Ray 会考虑数据的 locality。比如上述例子中的“data”,实际运行中可能会分布在任意一个远端的节点的内存里,如果 task 不在数据所在的节点上执行,跨节点的数据传输就无法避免。而 Ray 可以让这一类的优化变得透明。框架开发人员也可以利用 Ray 的 API 集成更丰富调度策略,最终提供给用户的是非常简单的 API。Ray 对 Actor 和 Task 还有很多高级的细粒度控制特性,比如支持 gang-scheduling 的 placement group 等,在此不一一赘述。
Ray 另外的优势在于:
高效的数据传递和存储:Ray 通过共享内存实现了一个轻量级的 plasma 分布式 object store。数据通过 Apache Arrow 格式存储。
分布式调度:Ray 的调度是 decentralized,每个节点上的 raylet 都可以进行调度;raylet 通过向 gcs 发送 heart beat 获取全局信息,在本地优先调度不能满足的情况下,快速让位给周边 raylet 进行调度。
多语言的支持:目前已经支持的语言包括:Python, Java, C++。后续 go 的支持以及更通用的多语言架构设计也在进行中。
下图是 RayRTC 的一个早期设计规划图和阶段一核心部分(DP+Training)的 Actor 封装流程图。本文着重讲解阶段一,二的设计和实现。其中在阶段一中所用到的核心组件包括 Ray Actor Pool 和 RaySGD 等。
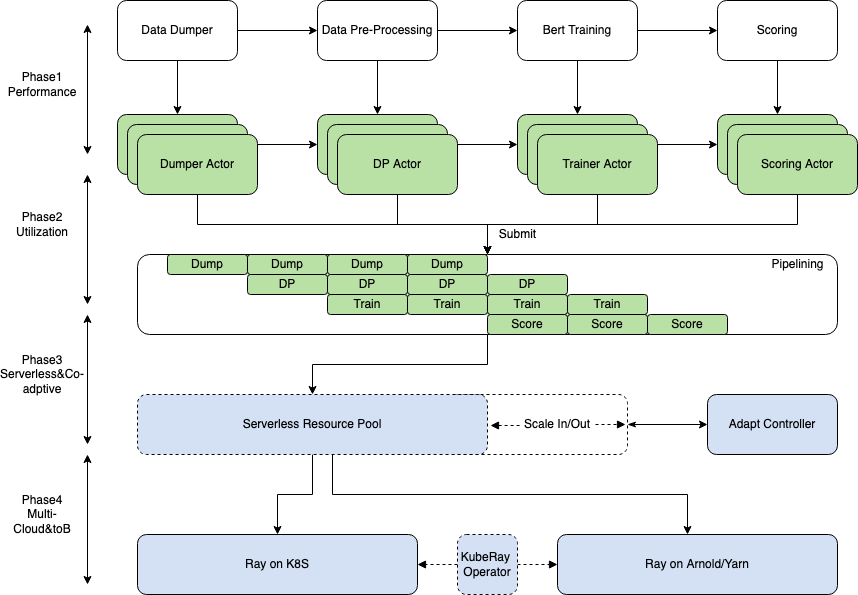
“DP+Training” Actor 化流程图:

其中主要包括 DataProcessing 和 Training 两个 Stage。每一部分的核心计算逻辑都用 Ray 的 API 封装成为 Actor 或 Task。Actor 提交运行后通过 Ray 的调度被放置到合适的节点上执行。Ray 的集群资源可以通过改造后的 Autoscaler 在字节内的 Yarn/K8S 集群上实现动态扩缩容。
DP 实现过程中,我们利用 Ray 的 ActorPool 解决了一个因为创建 Actor 数目过多而导致的 OOM 问题。Actorpool 本身相当于一个线程池,但 Ray 的 Actorpool 可以被开发者拓展为更高阶的弹性线程池。在 RayRTC 中,给定一组数据,我们需要解决的核心问题之一是使用多少 Ray 的 actor 是比较高效的。这里的高效指:资源使用高效,性能较优且稳定性较好(不能 oom)等。最简单的设计方式是 1 对 1,即对于每一个 HDFS 路径, 都指定一个单独的 DP Actor 来进行处理。但当数据量线性增长时,由于缺少内存管控而很容易出现 OOM。最极端的方式是 n 对 1,即用一个 actor,顺序处理所有数据,这样做显然无法发挥 Ray 的分布式能力。比较理想的方式是 n 对 m,即 m 个 actor 处理 n 组数据。作为对比,1 对 1 的情况如下:
ray_preprocessor_ret_refs = []
for hdfs_file_path in hdfs_file_path_list:
my_dp = ray.remote(DP).remote(hdfs_file_path)
ray_preprocessor_ret_refs.append(my_dp.__call__.remote())
n 对 m 的情况:
num_cpus = 10
actors = [ray.remote(DP).remote() for _ in range(num_cpus)]
actor_pool = ray.util.ActorPool(actors)
for hdfs_file_path in hdfs_file_path_list:
actor_pool.submit(lambda actor, info: actor.__call__.remote(**info),
hdfs_file_path)
在生产实践中,通过对 m 取一个定值,比如 m=10,可以有效控制内存使用并实现 I/O 并行。如前所述,给定一个动态的 workload,我们也可以对 m 的进行弹性支持,类似于 K8S 的 HPA 或 Spark 的 dynamic allocation。不同的是,在 Ray 里,开发者通过可编程的方式实现定制化的 dynamic allocation,比较简单的实现任意粒度的自动扩缩。这一部分的代码可以参考最新版本的 Ray dataset 中的类似实现(https://github.com/ray-project/ray/blob/master/python/ray/data/impl/compute.py)。
Training 部分的逻辑由于历史原因,在字节的内部场景有比较复杂的深度定制。对此,我们采用了 Ray 社区第一版的 Ray SGD(最新的版本中,这一模块为 Ray Train)对已有训练模块进行封装。RaySGD 是一个轻量级的分布式训练框架,支持 PyTorch 和 TensorFlow。底层直接集成了 PyTorch 的 DDP 和 Tensorflow 的 MirroredStrategy 来进行数据并行。RaySGD 通过把训练 worker 用 actor 进行封装,不仅实现了更灵活的分布式统一调度,而且与整个 Ray 生态打通。比如可以与 Ray Tune(超参)和 Ray Serve(推理)直接在 actor 这一粒度上进行通信和数据传输。
数据并行的分布式训练相比模型并行和混合并行的模式都要相对简单。但把一个复杂的单机版 NLP 训练框架通过 Ray 封装为分布式框架,并做到对原代码侵入性最小,需要处理好以下几个问题:
- 单节点的训练逻辑,如何设置模型,如何在 CPU 和 GPU 之间传递数据
- 如何设置 dataloader 以及 sampler,实现分布式数据读取
- 如何控制一个 epoch 里的 batch 循环
- 分布式训练逻辑,如何设置 worker 数量
- 如何使用 Ray 拉起 worker,并能在 worker 间通信
对于前 3 个问题,RayRTC 实现了 RayRTCTrainoperator,继承自 ray.util.sgd.torch 中的 TrainingOperator,把单节点上的训练逻辑全部抽象到一个类。
class RayRTCTrainOperator(TrainingOperator):
def setup(self, config):
# Setup data
self.train_loader = DataLoader(self.train_data,...)
self.valid_loader = DataLoader(self.valid_data,...)
# Register data loader
self.register_data(
train_loader=self.train_loader,
validation_loader=self.valid_loader)
...
# Register model, optimizer
self.model, self.optimizer = \
self.register(models=model, optimizers=optimizer,...)
在 RayRTCTrainOperator 这个类中,首先设置好训练所需要的模型和数据,并将 optimizer,scheduler 等参数传入。这些数据会随着 RayRTCTrainOperator 这个类被 Ray 封装为 actor,从而分布到不同的节点上,从而使得每个节点上都有一份完全一样的模型的拷贝和参数的初始状态。
数据格式的不同:
除了模型和数据的 setup,具体的训练逻辑需要根据 RTC 的场景进行定制。比如,每一个 epoch 的训练,以及一个 epoch 中每一个 batch 的训练。由于 RaySGD 对于 input 有一定的格式假设,导致在 RayRTCTrainOperator 中,需要重定义 train_epoch 和 train_batch 这两个函数以便正确处理数据和 metrics。举例而言,在 RaySGD 中,batch input 需要符合以下格式:
*features, target = batch
(https://github.com/ray-project/ray/blob/ray-1.3.0/python/ray/util/sgd/torch/training_operator.py#L536)
而实际的场景中,用户往往对数据格式有自己的定义。比如 RTC 中,batch 被定义为 Dict:
TensorDict = Dict[str, Union[torch.Tensor, Dict[str, torch.Tensor]]]
使用 RaySGD 中默认的 train_batch 函数,会在数据 unpack 时候发生错误。在 RayRTC 中,重写的 train_batch 把处理后 batch 以正确的格式传给 forward 函数。
训练指标的自定义问题:
在 train_epoch 中,同样有需要特殊处理的地方。RaySGD 默认支持的 metrics 只包括 loss 等。RTC 中,用户主要关心的指标包括 accuracy, precision, recall 以及 f1 measure 等。这些指标如何在 RaySGD 中加入是 RayRTC 实现过程中遇到的一个不小的挑战。一方面由于 RTC 本身已经实现了丰富的 metrics 计算模块,一方面 RaySGD 对训练过程中 metrics 的处理有固定的假设和且封装在比较底层。RayRTC 最终采取的方法是把 RTC 中的 metrics 计算模块复用到 RaySGD 的 train_epoch 中。另外遇到的一个问题是 RTC 的 metrics 计算需要把 model 作为参数传入,而 RaySGD 中的 model 已经被 DDP 封装,直接传入会导致出错。最后,train_epoch 需要加入如下改动:
if hasattr(model, 'module'):
metrics = rtc.get_metrics(model.module, ... reset=True)
else:
metrics = rtc.get_metrics(model, ... reset=True)
改动之后同时兼容了分布式和单机(没有被 DDP 封装)的情况。
RayRTCTrainOperator 可以理解为单机的训练模块,到了分布式环境下,可以通过 TorchTrainer 这个类。如下所示:
trainer = TorchTrainer(
training_operator_cls=RayRTCTrainOperator,
num_workers=self.num_workers,
use_fp16=self.use_fp16,
use_gpu=self.use_gpu,
...
num_cpus_per_worker=self.cpu_worker
)
Trainer 的主要功能是设置 training worker 的数量,混合精度,以及 worker 的 cpu 和 gpu。应用程序通过 trainer 可以非常简单地控制整个分布式训练的逻辑:
for epoch in epochs:
metrics['train'] = trainer.train()
metrics['validate'] = trainer.validate()
return metrics
Trainer 的底层逻辑中包括了拉起 worker group(https://github.com/ray-project/ray/blob/8ce01ea2cc7eddd40c2415904fa94198c0fe1e44/python/ray/util/sgd/torch/worker_group.py#L195),每一个worker用actor表达,从而形成一个actor group。RaySGD 也会处理 communication group 的 setup,以及 actor 的失败重启。经过这些封装,用户只需要关注跟训练最直接相关的逻辑,而不需要花过多时间在底层通讯,调度等分布式逻辑,极大提高了编程效率。
Checkpoint 的问题:
在改造基本完成后,我们用抖音的数据进行测试,发现模型在多卡时,没有任何调参的情况下,性能已经可以与单机持平,符合上线要求。但第一次上线测试后,发现 RayRTC 训练出来的模型连基线模型都打不过,准确率甚至低到 30%。在把所有控制变量固定仍然没有没有找到原因后,第一反应是 RayRTC 训练出来的模型可能并没有真正保存下来,以致线上打分用到的实际是 pre-trained 的 bert 模型。事实证明确实如此,而导致这个原因是因为 RaySGD 中的 training worker 是在远端运行,driver 端所初始的数据结构随着训练进行会与之逐渐不同步。checkpointing 之前需要取得更新后的模型参数,代码如下所示:
for epoch in epochs:
metrics['train'] = trainer.train()
metrics['validate'] = trainer.validate()
self.model = trainer.get_model()
self.save_checkpoint()
return metrics
与之前比较,增加了第 4 行,通过 trainer 获得更新后的 model,并通过 checkpoint 将模型持久化。
改造侵入性问题:
Anyscale 在一篇博客[https://www.anyscale.com/blog/ray-distributed-library-patterns]中总结了使用 Ray 的几种 pattern。其中大致可以分为三类,RayRTC 属于第三类。
- 用 Ray 做调度,比如 RayDP
- 用 Ray 做调度和通信,比如蚂蚁的在线资源分配
- 用 Ray 做调度,通信,数据内存存储
从第一类到第三类,用 Ray 的层次加深,但并不意味着改造成本线性增加。具体的应用需要具体分析。单纯从代码改动量上分析,RayRTC 第一阶段改了大概 2000 行代码,占原应用总代码量的 1%不到。
同时,RayRTC 把训练模块单独抽象出来,与原有代码保持松耦合关系。用户使用的时候,只需要载入相关 RayRTC 的模块,即可启动 Ray 进行分布式训练。
实验效果:
RayRTC 第一阶段在 1 到 8 卡(NVIDIA V100)上进行 scaling 测试,如下图所示:
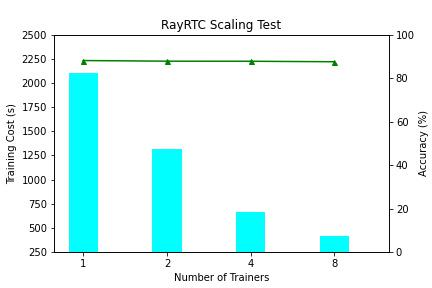
训练速度上,RayRTC 的性能随卡数呈现线性增加。训练准确度上,RayRTC 没有因为 global batch size 的增加而显著降低。8 卡训练中,单个 epoch 时间降到了 6 分钟以内。以往研发人员往往需要等待几个小时才能拿到训练结果,导致大家都习惯在下班前大量提交作业,第二天再来查看效果。整体集群 quota 资源利用率在白天不高,在晚上排队高峰。经过 RayRTC 提速后,研发人员会越来越多的进行接近交互式的开发迭代。
RayRTC pipeline
RayRTC 在字节内部运行在 Arnold 机器学习平台。用户在提交一个 RayRTC 任务时,对应在 Arnold 平台上拉起一个 Trial。一个 Trial 里,用户配置一个或多个 container 以及每个 container 所需的 CPU/GPU/Mem 资源。在一个 RayRTC 任务的整个生命周期中,对应 Trial 的资源是一直占用的。下图展示了某 RTC 任务运行期间的 GPU 资源使用情况。

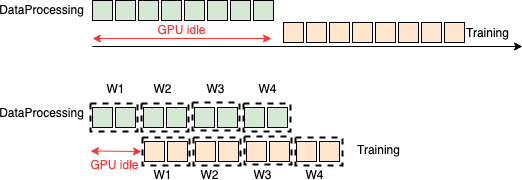
如图所示,在 Data Processing(DP)阶段,GPU 资源完全处于 idle 状态。造成这个现象的主要原因是当前的 RayRTC 阶段一方案虽然在 DP 和 Training 阶段都充分利用 Ray 的并行能力进行加速,但是这两个 stage 之间本质还是串行执行:Training 阶段必须等到 DP 结束了才开始。对于 DP 时间长的 RayRTC 任务,这将带来很大的 GPU 资源浪费。为了提高 GPU 资源使用率,我们结合 Ray Datasets 提供的 pipeline 功能, 提出并实现了 RayRTC 的流水并行方案 RayRTC pipeline。
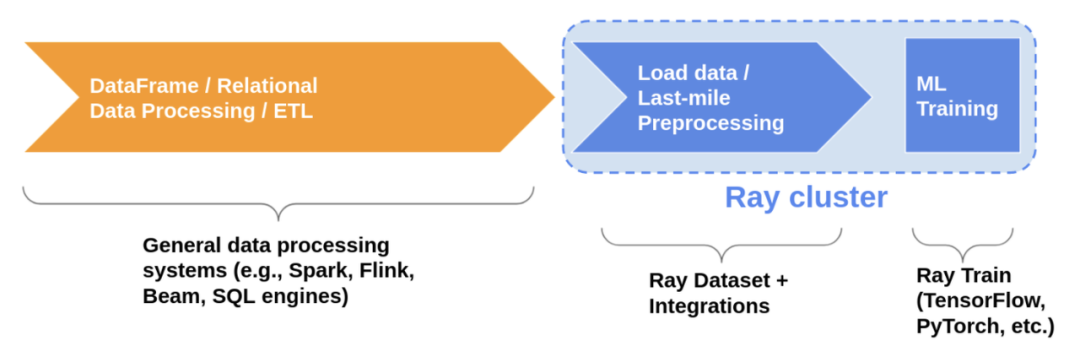
Ray Datasets 是在 Ray1.6+版本引入的在 Ray 的 libraries 和应用之间加载和交换数据标准化方法,其本身提供了一定的基本分布式数据处理能力,如 map, filter, repartition 等。如下图所示,数据经过 ETL 后,进入 ML Training 系统前,可以先通过 Ray Datasets 的 API 进行 last mile 的预处理。换言之,RayRTC 中的 DP 部分,完全可以用 Ray Datasets APIs 这种 Ray 标准化的方式重构,并与后面的 RaySGD(现 Ray Train)打通。
除了提供 last mile 预处理标准化 APIs, Ray Dataset s 还提供了一组非常重要的 pipeline 接口,使得 DP 部分和 Training 部分的流水并行执行成为可能。所谓流水并行执行,如下图所示,Training 执行并不会等到 DP 全部结束后才开始,而是一旦 DP 完成了一小部分就会把处理后的数据直接传入 Training 部分。流水处理有效减少 GPU idle 时间并缩短整个端到端 RTC 训练时间。
基于 Ray Datasets 的 RayRTC pipeline 实现
RayRTC pipeline 版本一:把 DP 部分当做黑盒
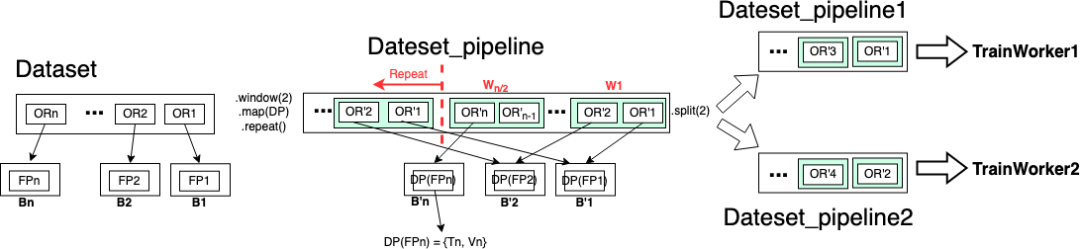
考虑到 RTC 中 DP 的复杂逻辑,在 RayRTC pipeline 版本一中,我们把 DP 当作黑盒处理。改造需求如下:
- DP(含 IO, trasforms, 数据集 split 等逻辑)与 Training 需要以 window 粒度流水并行,其中 DP 的 input 是文件路径 fp_i,output 是训练和验证数据集{'T':Ti, 'V':Vi}。
- DP 中的 split 逻辑要保证多 epoch 训练中每个 epoch 拿到的训练/验证数据集都相同,否则会导致数据泄露。多 epoch 训练中,只有第一个 epoch 拿到的训练/验证数据集真正经历 DP,其余 epoch 都复用之前已经处理分割好的数据集。
为满足以上需求,我们利用 Ray Datasets 的 API 实现如下:
dsp= ray.data.from_items([fp1, fp2, …., fpn],parallelism=n)
.window(blocks_per_window=2).map(dp).repeat().split(2)
但是,以上改造无法满足“每个训练 worker 拿到相同数目的 training instances”这个需求,因为该改造中的 split 的粒度其实还是“文件”而非“training instances”,而每个文件中包含的 training instances 数很可能不一样。为了满足这个需求,我们更新实现如下:
dsp_train= ray.data.from_items([fp1, fp2, …., fpn],parallelism=n)
.window(blocks_per_window=2).map(dp).flat_map(takeT).repeat()
.split(2, equal=True)
dsp_valid= ray.data.from_items([fp1, fp2, …., fpn],parallelism=n)
.window(blocks_per_window=2).map(dp).flat_map(takeV).repeat()
.split(2, equal=True)
其中:
def takeT(row):
train_data = row['T'].iter_rows()
for data in train_data:
yield data.as_pydict()
def takeV(row):
train_data = row['V'].iter_rows()
for data in train_data:
yield data.as_pydict()
但是更新后的实现带来了新问题:dsp_train 和 dsp_valid 实际对应两次不同的 DP split 逻辑,从而导致了数据泄露。我们需要类似如下实现来解决:
dsp_train,dsp_valid = ray.data.from_items([fp1, fp2, …., fpn],parallelism=n)
.window(blocks_per_window=2).map(dp).unzip_and_flat_map('T', 'V')
.repeat().split(2, equal=True)
其中, unzip_and_flat_map 既有类似 unzip 功能,把原数据集分割成两个数据集,原来数据集的 Row={'T':Ti, 'V':Vi} 变成两个新数据集的 Row1=Ti,Row2=Vi;又有 flat_map 功能,把数据集的 Row1=Ti 真正展开成 Row=Training Instance。考虑到这个 API 实现复杂且不具通用性,我们放弃了该版本改造,转向了 RayRTC pipeline 的版本二实现,把 DP 中的数据集分割逻辑抽取出来并提前,从开始就构造独立的训练/验证 pipeline,其余剩下的 DP 逻辑保留。
RayRTC pipeline 版本二:把 DP 中的数据集 Split 逻辑抽取出来并提前

在 RayRTC pipeline 版本二实现中,我们将数据集 scaling 和 split 逻辑抽取出来往前移,先构造训练和验证数据集。然后,分别从这两个数据集构造相应的训练/验证 pipelines。具体实现如下:
train_dataset, valid_dataset = self.get_datasets()
train_dataset_pipeline = train_dataset.window(blocks_per_window=2)
.flat_map(dp).repeat()
.random_shuffle_each_window().split(2, equal=True) # 2 is #trainWorkers
valid_dataset_pipeline = valid_dataset.window(blocks_per_window=2)
.flat_map(dp).repeat().split(2, equal=True) # 2 is #trainWorkers
其中:
def get_datasets(self):
# read dataset from hdfs
new_dataset = ray.data.read_api.read_json(partition_info_list)
# scale dataset up
scaled_dataset = new_dataset.flat_map(scale)
# shuffle dataset
shuffled_dataset = scaled_dataset.random_shuffle()
# split dataset into training and validation datasets
train_valid_ratio = 0.9
return shuffled_dataset.split_at_indices([int(shuffled_dataset.count() * train_valid_ratio)])
接着,train_dataset_pipeline 和 valid_dataset_pipeline 被传入 trainer:在每个 training worker 的 setup() 中,根据自己的 rank 得到相应的子 pipeline。
self.train_dataset_pipeline = self.train_pipeline[self.world_rank]
self.train_dataset_pipeline_epoch = self.train_dataset_pipeline.iter_epochs()
self.valid_dataset_pipeline = self.valid_pipeline[self.world_rank]
self.valid_dataset_pipeline_epoch = self.valid_dataset_pipeline.iter_epochs()
在 training worker 的 train_epoch() 中,从子 training pipeline 中获取 training instances 训练。
def train_epoch():
dataset_for_this_epoch = next(self.train_dataset_pipeline_epoch)
train_dataset = self.data_parser.parse(dataset_for_this_epoch)
train_loader = DataLoader(train_dataset)
for batch_idx, batch in enumerate(train_loader):
metrics = self.train_batch(batch, batch_info)
在 training worker 的 validate() 中, 从子 validation pipeline 中获取 validation instances 验证。
def validate():
dataset_for_this_epoch = next(self.valid_dataset_pipeline_epoch)
valid_dataset = self.data_parser.parse(dataset_for_this_epoch)
valid_loader = DataLoader(valid_dataset)
for batch_idx, batch in enumerate(valid_loader):
metrics = self.validate_batch(batch, batch_info)
实验效果:
为验证 RayRTC-pipeline 效果,我们随机选择中等规模 RTC training job (约 168 万条 instance),使用同等计算资源(2CPUs, 2GPUs)简单做了如下对比实验。结果显示,使用 pipeline 后,GPU idle 时间从原来的 245s 减少到了 102s,约 2.5 倍降低。端到端时间也比原来减少了 158s。除此之外,相比于阶段一实现,我们不但在初始阶段对整个数据集进行 random_shuffle,在每个 window 的训练数据从 pipeline 出来时,也通过 random shuffle 对 window 中的训练数据再次进行 shuffle。结果显示,充分的全局和局部 shuffle 有效提高模型精度。
Version | Accuracy | Precision | Recall | f1-measure | GPU idle time | E2E time |
RayRTC-phase1 | 0.804 | 0.637 | 0.571 | 0.602 | 245s | 2296s |
RayRTC-pipeline | 0.821 | 0.715 | 0.556 | 0.625 | 102s | 2138s |
Improve | +0.017 | +0.078 | -0.015 | +0.023 | -143s | -158s |
总结
RayRTC 以 Ray 为分布式计算学习引擎,对字节 RTC NLP 框架的全面改造升级不仅实现了性能的极致优化(5 小时到 30 分钟),同时通过流水并行极大降低了 GPU 资源的 idle 时间(60% reduction)。RayRTC 以松耦合的形式对现有业务的侵入极小(<1% loc),同时为后续可插拔 low-level 优化和 serverless autoscaling 提供了 API 支持。可以预见,后续 RayRTC 在更大规模上进行超参以及与推理打通,将会形成更高效的端到端 Serverless NLP Pipeline。