背景

在过去的一段时间内,京东Android APP通过图片压缩、图片转下载、资源混淆编译、插件化、插件后装、混合开发等一系列手段对安装包大小进行了优化,取得了不错的瘦身收益。在完成这些常规瘦身手段优化后,为了进一步优化安装包的大小,调研了谷歌官方新推出的 R8 编译器,了解到R8编译器在提升构建效率的同时,又能优化包体积大小,所以我们开始尝试升级AGP版本来启用R8编译,升级的过程不是很顺利,遇到了下面这些问题。
混淆工具介绍
对于Android应用,为了提高应用的安全性,常将代码混淆作为手段之一。代码混淆就是将源代码转换成功能上等价,但是难于阅读和理解的形式,降低代码的可读性,即使被反编译成功也很难得出代码的真正含义,通过代码混淆可以提升应用被反编译破解的难度。另一方面代码混淆后,由于类、方法或者字段的名称被映射成简短无意义的名称,也能减少应用的包体积。
01ProGuard
在AGP3.4.0之前,Android打包流程中默认使用ProGuard作为优化工具,ProGuard对源代码采用如下4个步骤进行优化,分别为压缩(shrink)、优化(optimize)、混淆(obfuscate)和预校验(preveirfy)。
- 压缩(shrink):移除未被使用的类、方法、字段等;
- 优化(optimize):字节码优化、方法内联等操作;
- 混淆(obfuscate):使用简短无意义的名称重命名类名、方法名、字段名等,增加反编译难度;
- 预校验(preverify):对class进行预校验。
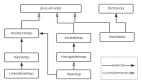
上面四个阶段是可以独立运行的,默认都是开启的,可以通过在混淆配置文件中设置-dontshrink、-dontoptimize、-dontobfuscate、-dontpreverify规则来关闭对应的阶段。ProGuard对.class文件进行代码压缩优化与混淆后会交给D8编译器进行脱糖,并将.class 文件转换成.dex文件,执行流程如下:
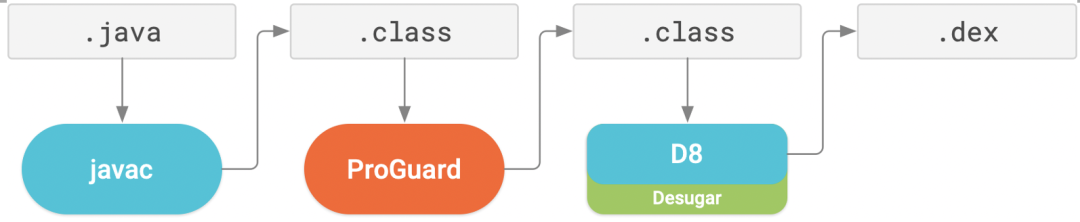
图1 ProGuard与D8的优化流程
02R8
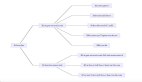
AGP 3.3.0之后谷歌官方开始引入R8,是ProGuard的替代品,但是兼容ProGuard的keep规则。R8将代码脱糖、压缩、混淆、优化和dex处理(D8)等优化流程整合在一个步骤中完成,启用R8编译后,在实际的开发过程中工程的构建效率要优于ProGuard,其编译流程如下。
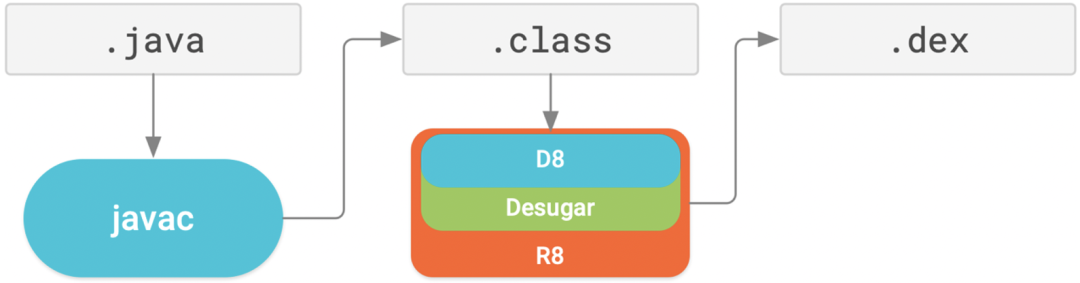
图2 R8 的优化流程
- 摇树优化:从应用及其库依赖项中检测并安全地移除未使用的类、字段、方法和属性;
- 资源压缩:从应用中移除未使用的资源,包括应用的库依赖项中未使用的资源;
- 混淆:缩短类和成员的名称;
- 优化:优化字节码、简化代码等操作,以进一步减小应用 DEX 文件的大小。例如,如果 R8检测到从未采用过给定 if/else 语句的 else {} 分支,R8 便会移除 else {} 分支的代码。
在Android正式发布Release包时,我们通常如下设置来开启优化功能:
release {
// 开启代码收敛
minifyEnabled true
// 开启资源压缩
shrinkResources true
// 定义ProGuard混淆规则
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}踩坑经验
01R8 混淆规则
1.1 问题现象
首先我们来看下在AGP 3.3.3构建工具打包混淆后生成的mapping.txt文件,观察数据类混淆后的映射关系,其中OtherBean数据类在混淆配置文件中添加了排除混淆规则-keep class com.jd.obfuscate.bean.OtherBean{ *; },而WatermelonBean数据类没有添加keep规则,而且这两个数据类拥有3个相同名称的字段name、color、shape:
com.jd.obfuscate.bean.OtherBean -> com.jd.obfuscate.bean.OtherBean:
java.lang.String name -> name
java.lang.String color -> color
java.lang.String shape -> shape
java.lang.String otherPrice -> otherPrice
java.lang.String otherComment -> otherComment
java.lang.String otherProducer -> otherProducer
java.lang.String otherCategory -> otherCategory
int otherWeight -> otherWeight
int otherQuality -> otherQuality
int otherScore -> otherScore
com.jd.obfuscate.bean.WatermelonBean -> com.jd.obfuscate.bean.a:
java.lang.String name -> name
java.lang.String color -> color
java.lang.String shape -> shape
java.lang.String price -> aMR
java.lang.String comment -> aMS
java.lang.String producer -> aMT
java.lang.String cate -> aMU
int weightAttr -> aMV
int qualityAttr -> aMW
int scoreAttr -> aMX
仔细观察这两个数据类混淆后的类名和字段名,由于WatermelonBean数据类没有添加keep规则,发现WatermelonBean数据类的类名和其余字段名都被混淆成无意义的名称,而字段name、color、shape却没有被混淆。
接下来我们再来看下升级AGP 3.6.4后启用R8编译后,WatermelonBean数据类会被混淆成什么样:
com.jd.obfuscate.bean.WatermelonBean -> b.b.a.a.a:
java.lang.String name -> a
java.lang.String color -> b
java.lang.String shape -> c
java.lang.String price -> d
java.lang.String comment -> e
java.lang.String producer -> f
java.lang.String cate -> g
int scoreAttr -> j
int weightAttr -> h
int qualityAttr -> i
在启用R8编译后,发现未添加keep规则的WatermelonBean数据类里的name、color、shape3个字段也都被混淆了。
在开发过程中与服务端交互时,使用Gson、FastJson等框架解析服务端数据时,会涉及到反序列化或反射相关,对应的对象数据类不能被混淆,应该添加相应的keep规则,否则无法将json数据解析成正确的对象。所以如果你的项目工程在升级AGP后,在应用上线前没有检查到所有的网络解析数据类都添加了相应的keep规则,那么业务功能就会出现问题。
1.2 原因分析
是什么原因导致了上面的现象?
①当你升级AGP启用R8编译时,如果仔细查看打包日志,你会发现关于"-useuniqueclassmembernames"混淆规则的警告提醒:
AGPBI: {"kind":"warning","text":"Ignoring option: -useuniqueclassmembernames",
"sources":[{"file":"xxx/proguard-project.txt","tool":"R8"}②熟悉ProGuard混淆规则的同学,针对上面的混淆现象应该一眼就能看出是"-useuniqueclassmembernames"的混淆规则引起的,对该规则解释是:为不同类中相同名称的成员变量在混淆后生成全局唯一的混淆名。在没有设置该规则时,不同类的方法或者字段都有可能被映射为a、b、c等无意义的名称。
③将"-useuniqueclassmembernames"混淆规则移除后进行验证,我们看下WatermelonBean数据类混淆后mapping文件:
com.jd.obfuscate.bean.WatermelonBean -> com.jd.obfuscate.bean.a:
java.lang.String name -> a
java.lang.String color -> b
java.lang.String shape -> c
java.lang.String price -> d
java.lang.String comment -> e
java.lang.String producer -> f
java.lang.String cate -> g
int weightAttr -> h
int qualityAttr -> i
int scoreAttr -> j
发现WatermelonBean数据类中的字段name、color、shape都被混淆成了字母,证实是该混淆规则会导致类名被混淆而它的部分字段名未被混淆的现象。
Proguard 对字段名是如何进行混淆的?
开发过自定义 Android Gradle 插件的开发者应该对 Gradle Transform 抽象类比较熟悉,Gradle Transform是Android 官方提供给开发者在项目构建阶段class文件转换为dex文件期间用来修改.class文件的一套标准API,通过这些API可以操作字节码,实现通用的功能。
AGP源码查看方式,在项目工程中添加依赖:
implementation 'com.android.tools.build:gradle:3.3.3'
定位源码到com.android.build.gradle.internal.transforms.ProGuardTransform:
public void transform(final TransformInvocation invocation) {
final SettableFuture<TransformOutputProvider> resultFuture = SettableFuture.create();
Job job = new Job(this.getName(), new Task<Void>() {
public void run(Job<Void> job, JobContext<Void> context) throws IOException {
ProGuardTransform.this.doMinification(invocation.getInputs(),
invocation.getReferencedInputs(), invocation.getOutputProvider());
}
}, resultFuture);
SimpleWorkQueue.push(job);
job.awaitRethrowExceptions();
}创建ProGuard处理的异步任务添加到WorkQueue队列中,执行doMinification() -> runProguard() -> (new ProGuard(this.configuration)).execute();
// 核心方法,根据混淆规则配置执行相应的操作
public void execute() throws IOException {
System.out.println(VERSION);
// 检查GPL许可协议
GPL.check();
if (configuration.printConfiguration != null) {
// 打印配置文件
printConfiguration();
}
// 检查混淆规则配置是否正确
new ConfigurationChecker(configuration).check();
if (configuration.programJars != null &&
configuration.programJars.hasOutput() &&
new UpToDateChecker(configuration).check()) {
return;
}
if (configuration.targetClassVersion != 0) {
configuration.backport = true;
}
// 读取所有class文件到类池中,programClassPool和libraryClassPool
readInput();
if (configuration.shrink || configuration.optimize ||
configuration.obfuscate || configuration.preverify) {
// 清除类中所有的JSE预验证信息
clearPreverification();
}
if (configuration.printSeeds != null || configuration.shrink ||
configuration.optimize || configuration.obfuscate ||
configuration.preverify || configuration.backport) {
// 检索类的依赖关系
initialize();
}
if (configuration.printSeeds != null)
// 将keep住的类输出到seeds.txt文件中
printSeeds();
}
if (configuration.shrink) {
// 执行压缩优化
shrink();
}
// 根据设置的优化级别进行代码指令优化:-optimizationpasses 5
if (configuration.optimize) {
for (int optimizationPass = 0;
optimizationPass < configuration.optimizationPasses;
optimizationPass++) {
if (!optimize(optimizationPass+1, configuration.optimizationPasses)) {
break;
}
// Shrink again, if we may.
if (configuration.shrink) {
// Don't print any usage this time around.
configuration.printUsage = null;
configuration.whyAreYouKeeping = null;
// 再次压缩优化
shrink();
}
}
// 在方法内联和类合并等优化之后,消除所有程序类的行号
linearizeLineNumbers();
}
if (configuration.obfuscate) {
// 执行混淆处理步骤
obfuscate();
}
if (configuration.preverify) {
// 预校验
preverify();
}
......
}
上面就是ProGuard执行的基本流程,我们着重看下obfuscate()混淆方法:
execute()方法执行真正的混淆操作:
new Obfuscator(configuration).execute(programClassPool, libraryClassPool);
Obfuscator类是真正做混淆处理的类,包含类混淆ClassObfuscator,成员混淆MemberObfuscator。
在执行的方法中,发现2处关于"-useuniqueclassmembernames"规则的处理逻辑:
// If the class member names have to correspond globally,
// link all class members in all classes, otherwise
// link all non-private methods in all class hierarchies.
ClassVisitor memberInfoLinker =
configuration.useUniqueClassMemberNames ?
(ClassVisitor)new AllMemberVisitor(new MethodLinker()) :
(ClassVisitor)new BottomClassFilter(new MethodLinker());
programClassPool.classesAccept(memberInfoLinker);
// Create a visitor for marking the seeds.
NameMarker nameMarker = new NameMarker();
ClassPoolVisitor classPoolvisitor =
new KeepClassSpecificationVisitorFactory(false, false, true)
.createClassPoolVisitor(configuration.keep,
nameMarker,
nameMarker,
nameMarker,
null);
// Mark the seeds.
programClassPool.accept(classPoolvisitor);
// Come up with new names for all class members.
NameFactory nameFactory = new SimpleNameFactory();
// Maintain a map of names to avoid [descriptor - new name - old name].
Map descriptorMap = new HashMap();
// Do the class member names have to be globally unique?
if (configuration.useUniqueClassMemberNames) {
// Collect all member names in all classes.
programClassPool.classesAccept(
new AllMemberVisitor(
new MemberNameCollector(configuration.overloadAggressively, descriptorMap)));
// Assign new names to all members in all classes.
programClassPool.classesAccept(new AllMemberVisitor(
new MemberObfuscator(configuration.overloadAggressively, nameFactory, descriptorMap)));
} else { ...... }
混淆分为六个步骤:
第一步:如果设置了"-useuniqueclassmembernames"混淆规则,首选通过ClassVisitor)new AllMemberVisitor(new MethodLinker())创建MethodLinker访问者对象,将所有类中的字段信息转为链表连接起来,以字段名称和字段类型作为key,查询memberMap中是否已经存在该字段的visitorInfo信息,如果没有查询到就调用lastMember()方法尝试获取该字段在链表中的visitorInfo,并存入memberMap中;如果能查询到,则将该字段信息作为visitorInfo加入到字段信息的链表中:
public void visitAnyMember(Clazz clazz, Member member) {
// 取得字段的名称和描述符
String name = member.getName(clazz);
String descriptor = member.getDescriptor(clazz);
String key = name + ' ' + descriptor;
Member otherMember = (Member)memberMap.get(key);
if (otherMember == null) {
// Get the last method in the chain.
Member thisLastMember = lastMember(member);
// Store the new class method in the map.
memberMap.put(key, thisLastMember);
} else {
// Link both members.
link(member, otherMember);
}
}
public static Member lastMember(Member member) {
Member lastMember = member;
while (lastMember.getVisitorInfo() != null &&
lastMember.getVisitorInfo() instanceof Member) {
lastMember = (Member)lastMember.getVisitorInfo();
}
return lastMember;
}
private static void link(Member member1, Member member2) {
// Get the last methods in the both chains.
Member lastMember1 = lastMember(member1);
Member lastMember2 = lastMember(member2);
// Check if both link chains aren't already ending in the same element.
if (!lastMember1.equals(lastMember2)) {
// Merge the two chains, with the library members last.
if (lastMember2 instanceof LibraryMember) {
lastMember1.setVisitorInfo(lastMember2);
} else {
lastMember2.setVisitorInfo(lastMember1);
}
}
}第二步:将添加keep规则的类名、方法或字段名进行标记(NameMarker)而不被混淆。ProGuard源码大量使用了访问者模式,通过创建ClassVisitor的实现类nameMarker对象来访问对象池,最终会执行NameMarker类中的方法:
public void visitProgramClass(ProgramClass programClass) {
// 标记keep规则中的类名
keepClassName(programClass);
// Make sure any outer class names are kept as well.
programClass.attributesAccept(this);
}
public void keepClassName(Clazz clazz) {
ClassObfuscator.setNewClassName(clazz, clazz.getName());
}
public void visitProgramField(ProgramClass programClass,
ProgramField programField) {
// 标记keep规则中的字段名
keepFieldName(programClass, programField);
}
private void keepFieldName(Clazz clazz, Field field) {
MemberObfuscator.setFixedNewMemberName(field, field.getName(clazz));
}
// 给字段标记固定的名称
static void setFixedNewMemberName(Member member, String name) {
VisitorAccepter lastVisitorAccepter = MethodLinker.lastVisitorAccepter(member);
if (!(lastVisitorAccepter instanceof LibraryMember) &&
!(lastVisitorAccepter instanceof MyFixedName)) {
lastVisitorAccepter.setVisitorInfo(new MyFixedName(name));
} else {
lastVisitorAccepter.setVisitorInfo(name);
}
}
public void visitProgramMethod(ProgramClass programClass,
ProgramMethod programMethod) {
// 标记keep规则中的方法名
keepMethodName(programClass, programMethod);
}
private void keepMethodName(Clazz clazz, Method method) {
String name = method.getName(clazz);
if (!ClassUtil.isInitializer(name)) {
MemberObfuscator.setFixedNewMemberName(method, name);
}标记字段keep名称做法比较简单,只要通lastVisitorAccepter.setVisitorInfo(name)来设置。
第三步:收集所有类中的所有成员的映射关系(MemberNameCollector),先从字段链表中获取上一步中标记的keep名称(visitorInfo),并将相同类型的方法或字段放入同一个Map<混淆后名称,原始名称>中:
public void visitAnyMember(Clazz clazz, Member member) {
String name = member.getName(clazz);
// Get the member's new name.
// 在链表中获取该成员的visitorInfo
String newName = MemberObfuscator.newMemberName(member);
// keep的名称
if (newName != null) {
// Get the member's descriptor.
String descriptor = member.getDescriptor(clazz);
if (!allowAggressiveOverloading) {
descriptor = descriptor.substring(0, descriptor.indexOf(')')+1);
}
// Put the [descriptor - new name] in the map,
// creating a new [new name - old name] map if necessary.
Map nameMap = MemberObfuscator.retrieveNameMap(descriptorMap, descriptor);
String otherName = (String)nameMap.get(newName);
if (otherName == null ||
MemberObfuscator.hasFixedNewMemberName(member) ||
name.compareTo(otherName) < 0) {
// 把相同描述符的方法或字段放入同一个
// Map<混淆后名称,原始名称>中
nameMap.put(newName, name);
}
}第四步:创建混淆名称混淆,如果在keep名称链表中找不到映射关系,就创建新的混淆名称(MemberObfuscator):
public void visitAnyMember(Clazz clazz, Member member) {
String name = member.getName(clazz);
// Get the member's descriptor.
String descriptor = member.getDescriptor(clazz);
// Get the name map, creating a new one if necessary.
Map nameMap = retrieveNameMap(descriptorMap, descriptor);
// Get the member's new name.
// 1.如果前面已经有keep的名称,就不进行混淆,
// 如果没有就分配新的混淆名称
String newName = newMemberName(member);
// Assign a new one, if necessary.
if (newName == null) {
// Find an acceptable new name.
nameFactory.reset();
do {
// 2.生成新的名称
newName = nameFactory.nextName();
}
while (nameMap.containsKey(newName));
// Remember not to use the new name again
// in this name space.
nameMap.put(newName, name);
// Assign the new name.
// 3. 为这个成员设置新的名称
setNewMemberName(member, newName);
}
}
static void setNewMemberName(Member member, String name) {
MethodLinker.lastVisitorAccepter(member).setVisitorInfo(name);
}NameFactory接口类主要负责生成新的混淆名称,如果没有设置自定义 obfuscationDictionary 字典的话,NameFactory接口的实现类SimpleNameFactory类,主要通过newName方法生成新的混淆名称:
private static final int CHARACTER_COUNT = 26;
private String newName(int index) {
// If we're allowed to generate mixed-case names,
// we can use twice as
// many characters.
int totalCharacterCount = generateMixedCaseNames ?
2 * CHARACTER_COUNT : CHARACTER_COUNT;
int baseIndex = index / totalCharacterCount;
int offset = index % totalCharacterCount;
char newChar = charAt(offset);
String newName = baseIndex == 0 ?
new String(new char[] { newChar }) :
(name(baseIndex-1) + newChar);
return newName;
}
private char charAt(int index) {
return (char)((index < CHARACTER_COUNT ? 'a' -0 :
'A' - CHARACTER_COUNT) + index);
CHARACTER_COUNT被定义为26,正好是26个字母的意思,nextName()方法里通过index计数器,每次产生新名称都往上自加,所以ProGuard的混淆名字是从a开始到z。
第五步:应用混淆名称,创建ClassRenamer访问者对象,通过ConstantPoolEditor对象向常量池添加新的混淆名称,并更新字段名称的索引u2nameIndex指向新的混淆名称。
// Actually apply the new names.
programClassPool.classesAccept(new ClassRenamer());
public void visitProgramMember(ProgramClass programClass,
ProgramMember programMember) {
// Has the class member name changed?
String name = programMember.getName(programClass);
String newName = MemberObfuscator.newMemberName(programMember);
if (newName != null && !newName.equals(name)) {
programMember.u2nameIndex = new ConstantPoolEditor(programClass).addUtf8Constant(newName);
}
第六步:常量池压缩,新的混淆名称是通过在常量池中新增数据,原先的数据并没有被删除,需要进行修复,由于篇幅优先不做详细分析。
R8 编译器为什么不支持该混淆规则?
从上面的现象上看,R8编译器是忽略了"-useuniqueclassmembernames"的混淆规则,但是在谷歌Android开发文档“缩减应用大小”用户指南里也没有提到该规则的相关信息,接下来尝试通过源码层面查找该规则被忽略的原因。通过查找资料,在R8源码仓库中搜索关键词"useuniqueclassmembernames",找到了关于R8不支持该规则的代码提交记录。"-useuniqueclassmembernames"混淆的规则在ProGuard中主要用于增量混淆,但是引入R8编译器的主要目标是进一步缩减应用的大小,如果在R8中支持该规则只会增加代码混淆的复杂性,并没有带来真正的好处。
R8 还有哪些混淆规则不支持?
查看ProguardConfigurationParser.java源码(https://r8.googlesource.com/r8/+/3a100449ba5b490cd13d466b8c7e17dcd500722a/src/main/java/com/android/tools/r8/shaking/ProguardConfigurationParser.java),以下混淆规则会被R8编译器忽略:
-forceprocessing
-dontusemixedcaseclassnames
-dontpreverify
-experimentalshrinkunusedprotofields
-filterlibraryjarswithorginalprogramjars
-dontskipnonpubliclibraryclasses
-dontskipnonpubliclibraryclassmembers
-invokebasemethod
-mergeinterfacesaggressively
-android
-shrinkunusedprotofields
-allowruntypeandignoreoptimizationpasse
-addconfigurationdebugging
-assumenoescapingparameters
-assumenoexternalreturnvalues
-dump
-keepparameternames
-outjars
-target
-useuniqueclassmembernames
1.3 混淆小结
如果你的项目工程中同时满足以下情况,就有可能在升级AGP的过程中,出现字段解析获取不到对应值的问题,导致业务功能异常:
- 添加了"-useuniqueclassmembernames"混淆规则;
- 有多个业务线不同的数据类又包含一些相同的字段;
- 不能保证所有的数据类在进行网络json数据解析时添加了keep规则;
- 打算升级AGP启用R8编译。
针对Android开发的混淆建议:
- 开发检查数据类是否添加了keep规则的Gradle自定义插件,在工程打包调式阶段通过错误日志提前提醒开发者是否有混淆风险;
- 针对混淆形成最佳实践来指导开发者正确使用混淆规则,例如将所有的数据类放在统一的包中,添加该包名的keep规则,或者涉及到反序列化或反射相关的,也可以添加@Keep注解。
02v1签名逻辑
2.1 v1签名丢失问题
京东APP调试包会读取v1签名的信息,在升级AGP 3.6.4 后运行调试包崩溃,排除原因发现是通过Android Studio run按钮生成的调试包中的v1签名丢失导致的。
我们通常会在工程app目录的build.gradle文件进行签名相关设置:
signingConfigs {
release {
storeFile file('xxx')
storePassword 'xxx'
keyAlias 'xxx'
keyPassword 'xxx'
v1SigningEnabled true
v2SigningEnabled true
}
}
buildTypes {
debug {
minifyEnabled false
shrinkResources false
zipAlignEnabled true
signingConfig signingConfigs.release
}
release {
minifyEnabled true
shrinkResources true
zipAlignEnabled true
signingConfig signingConfigs.release
}
}2.2 原因分析
通过查阅AGP 3.6.4源码发现在PackageAndroidArtifact类执行doTask()静态方法中会创建IncrementalPackagerBuilder会涉及到签名相关,代码如下:
public IncrementalPackagerBuilder withSigning(
@Nullable SigningConfigData signingConfig, int minSdk,
@Nullable Integer targetApi) {
boolean enableV1Signing =
enableV1Signing(
signingConfig.getV1SigningEnabled(),
signingConfig.getV2SigningEnabled(),
minSdk,
targetApi);
boolean enableV2Signing = (targetApi == null || targetApi >= NO_V1_SDK)
&& signingConfig.getV2SigningEnabled();
creationDataBuilder.setSigningOptions(
SigningOptions.builder()
.setKey(certificateInfo.getKey())
.setCertificates(certificateInfo.getCertificate())
.setV1SigningEnabled(enableV1Signing)
.setV2SigningEnabled(enableV2Signing)
.build());
} catch (KeytoolException|FileNotFoundException e) {
throw new RuntimeException(e);
}
return this;
}
private static int NO_V1_SDK = 24;
static boolean enableV1Signing(boolean v1Enabled, boolean v2Enabled,
int minSdk, @Nullable Integer targetApi) {
if (!v1Enabled) {
return false;
}
// If there is no v2 signature specified we have to sign with v1 even if the versions are
// high enough otherwise we would not have signed at all
if (!v2Enabled) {
return true;
}
// Case where both v1Enabled==true and v2Enabled==true
return (targetApi == null || targetApi < NO_V1_SDK) && minSdk < NO_V1_SDK;
从上面enableV1Signing()方法中可以看到,targetApi是指连接电脑的手机的系统版本,会根据当前连接的测试机的系统版本是否小于Android7.0来判断是否启用v1签名,如果手机系统大于Android7.0的话,v1签名将会失效。
解决方案,将targetApi通过反射置为null,在build.gralde文件添加如下设置:
project.afterEvaluate {
project.android.getApplicationVariants().all { appVariant ->
String variantName = appVariant.name.capitalize()
Task packageTask = project.tasks.findByName("package${variantName}")
try {
if (packageTask.getTargetApi() != null) {
Field field = packageTask.getClass().getSuperclass().getSuperclass().getDeclaredField("targetApi")
field.setAccessible(true)
field.set(packageTask, null)
}
} catch (Exception e) {
e.printStackTrace()
}
}
}从源码IncrementalPackagerBuilder.java提交的变更记录来看,启用v1/v2签名的逻辑变化了多次。
03打包流程
3.1 现象
京东APP在打包过程中通过APT技术识别代码中的注解,然后将注解信息生成json文件存放到工程assets目录,随后该json文件会被一起打包进apk中,但是在升级 AGP 后,在进行打包时该json文件丢失导致功能异常。排查原因发现是打包过程中的某些任务执行顺序发生了变化:
升级 AGP 前:
> Task :AndroidPhone:compileXXXJavaWithJavac
> Task :AndroidPhone:mergeXXXAssets
升级 AGP 后:
> Task :AndroidPhone:mergeXXXAssets
> Task :AndroidPhone:compileXXXJavaWithJavac
由于注解处理逻辑在 compileXXXJavaWithJavac 任务中,上述两个任务在执行顺序发生变化后,会导致合并assets资源文件任务优先于拷贝json文件到项目工程assets目录,最终导致json文件在apk包中丢失。
3.2 解决方案
将两任务设置先后依赖的关系,build.gradle中添加如下脚本:
project.afterEvaluate {
project.android.applicationVariants.all {
def variantName = it.name.capitalize()
Task compileJavaWithJavacTask = project.tasks.findByName("compile${variantName}JavaWithJavac")
Task mergeAssetsTask = project.tasks.findByName("merge${variantName}Assets")
mergeAssetsTask.dependsOn(compileJavaWithJavacTask)
}
}AGP升级建议
- 首先将升级AGP前后的apk产物进行对比,检查资源文件等是否有缺失;
- 制作脚本工具来对比升级前后生成的mapping.txt文件,检查本该添加keep规则的类或字段是否有遗漏;
- 针对R8编译器不支持的,影响全局的ProGuard混淆规则做好潜在风险评估:例如混淆规则"-useuniqueclassmembernames";
- 全面评估升级AGP的风险,做好降级预案。
总结
本文主要介绍的是京东APP在升级Android构建工具AGP 3.6.4过程中的踩坑记录,升级完成后包体积减少了约1.5MB,希望上面的踩坑经验能够帮助到打算升级AGP的读者。