今天这篇文章,其实也是我曾经面试中遇到过的真题。
分库分表大家可能听得多了,但 读扩散 问题大家了解吗?
这里涉及到几个问题。
分库分表是什么?
读扩散问题是什么?
分库分表为什么会引发读扩散问题?
怎么解决读扩散问题?
这些问题还是比较有意思的。
相信兄弟们也一定有机会遇到哈哈哈。
我们先从分库分表的话题聊起吧。
分库分表
我们平时做项目开发。一开始,通常都先用一张数据表,而一般来说数据表写到2kw条数据之后,底层B+树的层级结构就可能会变高,不同层级的数据页一般都放在磁盘里不同的地方,换言之,磁盘IO就会增多,带来的便是查询性能变差。 如果对上面这句话有疑惑的话,可以去看下我之前写的文章。
于是,当我们单表需要管理的数据变得越来越多,就不得不考虑数据库 分表 。而这里的分表,分为 水平分表和垂直分表 。
垂直分表的原理比较简单,一般就是把某几列拆成一个新表,这样单行数据就会变小,B+树里的单个数据页(固定16kb)内能放入的行数就会变多,从而使单表能放入更多的数据。
垂直分表没有太多可以说的点。下面,我们重点说说最常见的 水平分表 。
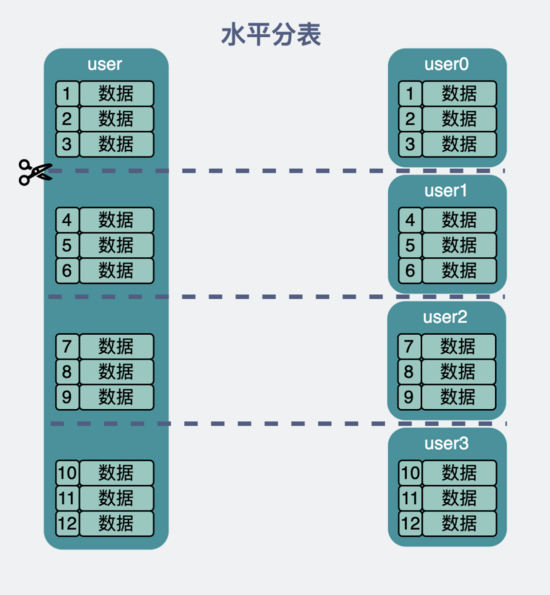
水平分表有好几种做法,但不管是哪种,本质上都是将原来的 user 表,变成 user_0, user1, user2 .... uerN 这样的N多张小表。
从读写一张user 大表 ,变成读写 user_1 … userN 这样的N张 小表 。
 分表
分表
每一张小表里,只保存一部分数据,但具体保存多少,这个自己定,一般就订个 500w~2kw 。
那分表具体怎么做?
根据id范围分表
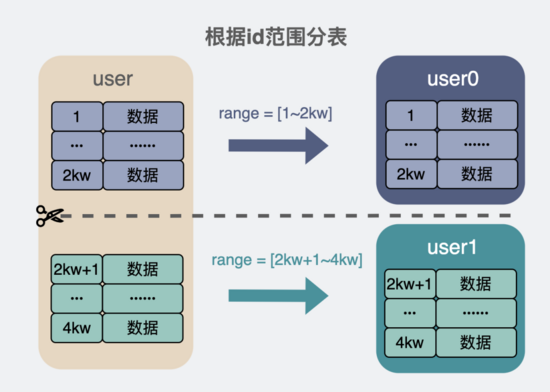
我认为最好用的,是根据id范围进行分表。
我们假设每张分表能放 2kw 行数据。那user0就放主键id为 1~2kw 的数据。user1就放id为 2kw+1 ~ 4kw ,user2就放id为 4kw+1 ~ 6kw , userN就放 2N kw+1 ~ 2(N+1)kw 。
根据id范围分表
假设现在有条数据,id=3kw,将这个 3kw除2kw = 1.5 ,向下取整得到 1 ,那就可以得到这条数据属于 user1表 。于是去读写user1表就行了。这就完成了数据的路由逻辑,我们把这部分逻辑封装起来,放在数据库和业务代码之间。
这样。 对于业务代码来说 ,它只知道自己在读写一张 user 表,根本不知道底下还分了那么多张小表。
对于数据库来说,它并不知道自己被分表了,它只知道有那么几张表,正好名字长得比较像而已。
这还只是在 一个数据库 里做分表,如果范围再搞大点,还能在 多个数据库 里做分表,这就是所谓的 分库分表 。
不管是单库分表还是分库分表,都可以通过这样一个中间层逻辑做路由。
还真的就应了那句话,没有什么是加中间层不能解决的。
如果有,就多加一层。
至于这个中间层的实现方式就更灵活了,它既可以像 第三方orm库 那样加在业务代码中。
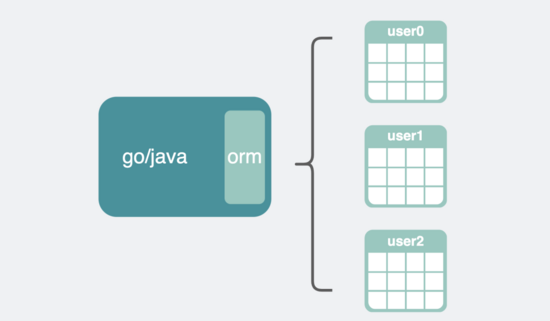
通过orm读写分表
也可以在mysql和业务代码之间加个 proxy服务 。
如果是通过第三方orm库的方式来做的话,那需要根据不同语言实现不同的代码库,所以不少厂都选择后者加个proxy的方式,这样就不需要关心上游服务用的是什么语言。
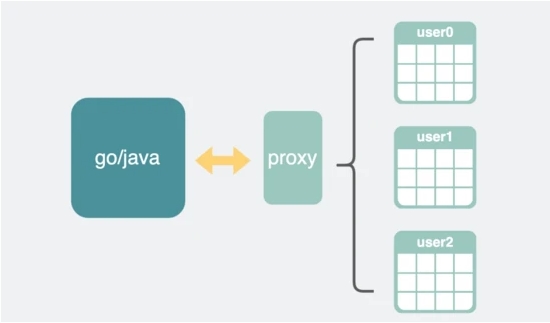
通过proxy管理分表
根据id取模分表
这时候就有兄弟要提出问题了,"我看很多方案都 对id取模 ,你这个方案是不是不完整?"。
取模的方案也是很常见的。
比如一个id=31进来,我们一共分了5张表,分别是user0到user4。对 31%5=1 ,取模得 1 ,于是就能知道应该读写 user1 表。
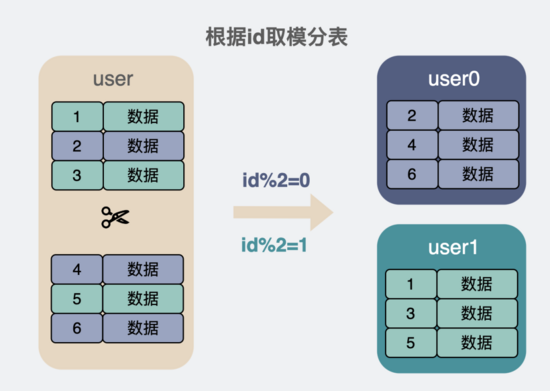
根据id取模分表
优点当然是比较简单。而且读写数据都可以很均匀的分摊到每个分表上。
但 缺点 也比较明显,如果想要扩展表的个数,比如从5张表变成8张表。那同样还是id=31的数据, 31%8 = 7 ,就需要读写user7这张表。跟原来就对不上了。
这就需要考虑 数据迁移 的问题。很头秃。
为了避免后续扩展的问题,我见过一些业务一开始就将数据预估得很大,然后心一横,分成100张表,一张表如果存个2kw条,那也能存20亿数据了。
也不是说这样不行吧,就是这个业务直到最后放弃的时候,也就存了百万条数据,每次打开数据库表能看到茫茫多的user_xx,就是不太舒服,专业点,叫增加了程序员的 心智负担 。
而上面一种方式,根据id范围去分表,就能很好的解决这些问题,数据少的时候,表也少,随着数据增多,表会慢慢变多。而且这样表还可以无限扩展。
那是不是说取模的做法就用不上了呢?
也不是。
将上面两种方式结合起来
id取模的做法,最大的好处是,新写入的数据都是实实在在的分散到了 多张表 上。
而根据id范围去做分表,因为id是递增的,那新写入的数据一般都会落到 某一张表 上,如果你的业务场景写数据特别频繁,那这张表就会出现 写热点 的问题。
这时候就可以将id取模和id范围分表的方式结合起来。
我们可以在某个id范围里,引入取模的功能。比如 以前 2kw~4kw 是user1表,现在可以在这个范围 再分成5个表 ,也就是引入user1-0, user1-2到user1-4,在这5个表里取模。
举个例子,id=3kw,根据范围,会分到user1表,然后再进行取模 3kw % 5 = 0,也就是读写user1-0表。
这样就可以将写单表分摊为写多表。
这在分库的场景下优势会更明显,不同的库,可以把服务部署到不同的机器上,这样各个机器的性能都能被用起来。
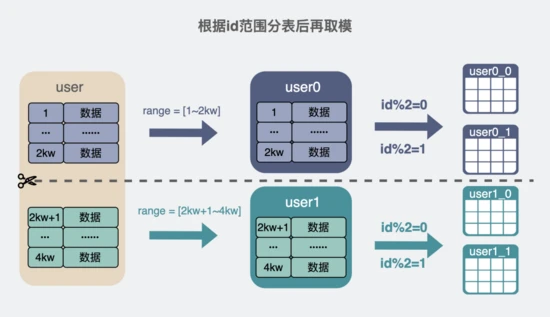
根据id范围分表后再取模
读扩散问题
我们上面提到的好几种分表方式,都用了id这一列作为 分表的依据 ,这其实就是所谓的 分片键 。
实际上我们一般也是用的 数据库主键 作为 分片键 。
这样,理想情况下我们已知一个id,不管是根据哪种规则,我们都能很快定位到该读哪个分表。
但很多情况下,我们的查询又不是只查主键,如果我的数据库表有一列name,并且加了个普通索引。
这样我执行下面的sql
select * from user where name = "小白";
由于name并不是分片键,我们没法定位到具体要到哪个分表上去执行sql。
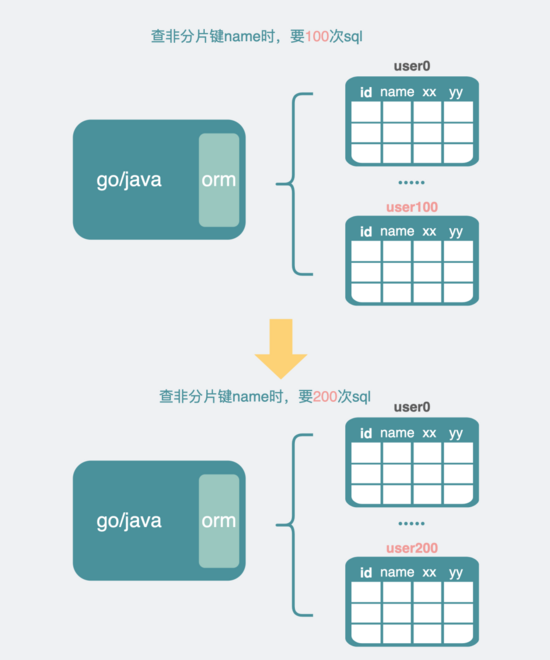
于是就会对 所有分表 都执行上面的sql,当然不会是串行执行sql,一般都是 并发 执行sql的。
如果我有100张表,就执行100次sql。
如果我有200张表,就执行200次sql。
随着我的表越来越多,次数会越来越多,这就是所谓的 读扩散问题 。
读扩散问题
这是个比较有趣的问题,它确实是个问题,但大部分的业务不会去处理它,读100次怎么了,数据增长之后读的次数会不断增加又怎么了?但架不住我的 业务不赚钱 啊,也根本 长不了那么多数据 啊。
话是这么说没错,但面试官问你的时候,你得知道怎么处理啊。
引入新表来做分表
问题的核心在于,主键是分片键,而普通索引列并不分片。
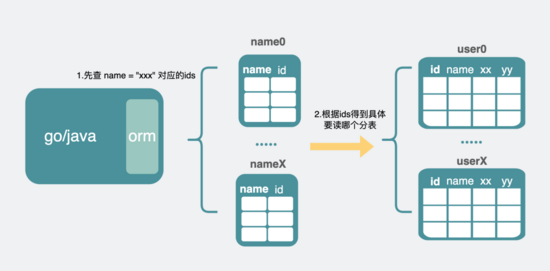
那好办,我们单独建个 新的分片表 ,这个新表里的列就只有旧表的主键id和普通索引列,而这次换普通索引列来做分片键。
通过新索引表解决读扩散问题
这样当我们要查询普通索引列时,先到这个新的分片表里做一次查询,就能迅速定位到对应的主键id,然后再拿主键id去旧的分片表里查一次数据。这样就从原来漫无目的的全表扩散查询,缩减为只查固定几个表了。
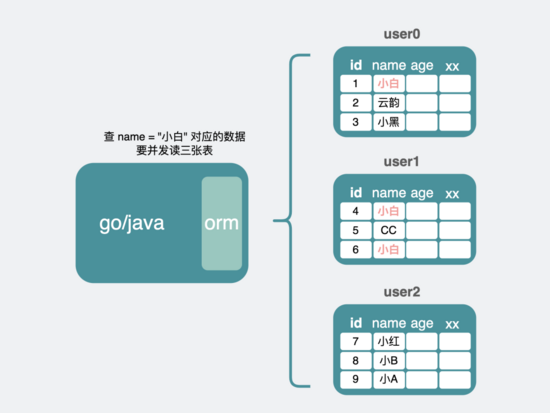
举个例子。比如我的表原本长下面这样,其中id列是主键,同时也是分片键,name列是非主键索引。为了简化,假设三条数据一张表。
此时分表里 id=1,4,6 的都有 name="小白" 的数据。
当我们执行 select * from user where name = "小白"; 则需要并发查3张表,随着表变多,查询次数会变得更多。
举例说明读扩散问题
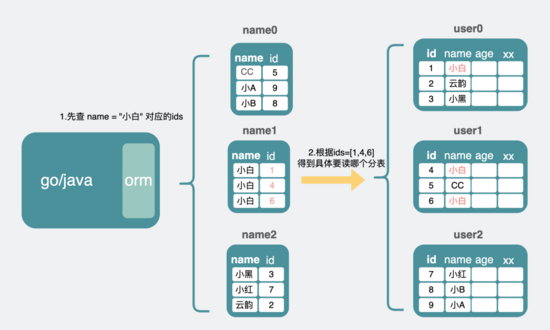
但如果我们为name列 建个新表(nameX),以name为新的分片键 。
这样我们可以先执行 select id from nameX where name = "小白";
再拿着结果里的ids去查询 select * from user where id in (ids); 这样就算表变多了,也可以迅速定位到某几张具体的表,减少了查询次数。
举例说明通过新索引表解决读扩散问题
但这个做法的缺点也比较明显,你需要维护两套表,并且普通索引列更新时,要两张表同时进行更改。
有一定的开发量
有没有更简单的方案?
使用其他更合适的存储
我们常规的查询是通过id主键去查询对应的name列。而像上面的方案,则通过引入一个新表, 倒过来 ,先用name查到对应的id,再拿id去获取具体的数据。这其实就像是建立了一个新的索引一样,像这种,通过name列反查原数据的思想,其实就很类似于 倒排索引 。
相当于我们是利用了倒排索引的思路去解决分表下的数据查询问题。
回想下,其实我们的 原始需求 无非就是在大量数据的场景下依然能提供普通索引列或其他更多维度的查询。
这种场合,更适合使用es,es天然分片,而且内部利用 倒排索引 的形式来加速数据查询。
哦?兄弟萌,又是它, 倒排索引 ,又是个极小的细节,做好笔记。
举个例子,我同样是一行数据 id,name,age。在mysql里,你得根据id分片,如果要支持name和age的查询,为了防止读扩散,你得分别再建一个name的分片表和一个age的分片表。
而如果你用es,它会在它内部以id分片键进行分片,同时还能建一个name到id,和一个age到id的倒排索引。这是不是就跟上面做的事情没啥区别。
而且将mysql接入es也非常简单,我们可以通过开源工具 canal 监听mysql的 binlog 日志变更,再将数据解析后写入es,这样es就能提供 近实时 的查询能力。
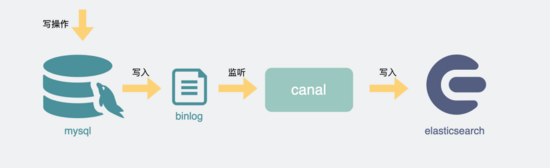
mysql同步es
觉得es+mysql还是繁琐?有没有其他更简洁的方案?
有。
别用mysql了,改用 tidb 吧,相信大家多少也听说过这个名称,这是个 分布式数据库 。
它通过引入 Range 的概念进行数据表分片,比如第一个分片表的id在0~2kw,第二个分片表的id在2kw~4kw。
哦?有没有很熟悉,这不就是文章开头提到的根据id范围进行数据库分表吗?
它支持普通索引,并且普通索引也是分片的,这是不是又跟上面提到的倒排索引方案很类似。
又是个极小的细节。
并且tidb跟mysql的语法几乎一致,现在也有非常多现成的工具可以帮你把数据从mysql迁移到tidb。所以开发成本并不高。
用tidb替换mysql
总结
mysql在单表数据过大时,查询性能会变差,因此当数据量变得巨大时,需要考虑水平分表。
水平分表需要选定一个分片键,一般选择主键,然后根据id进行取模,或者根据id的范围进行分表。
mysql水平分表后,对于非分片键字段的查询会有读扩散的问题,可以用普通索引列作分片键建一个新表,先查新表拿到id后再回到原表再查一次原表。这本质上是借鉴了倒排索引的思路。
如果想要支持更多维度的查询,可以监听mysql的binlog,将数据写入到es,提供近实时的查询能力。
当然,用tidb替换mysql也是个思路。tidb属实是个好东西,不少厂都拿它换个皮贴个标,做成自己的 自研数据库 ,非常推荐大家学习一波。
不要做过早的优化,没事别上来就分100个表,很多时候真用不上。
参考资料
《图解分库分表》
https://mp.weixin.qq.com/s/OI5y4HMTuEZR1hoz9aOMxg
最后
当年我还在某个游戏项目组里做开发的时候,从企鹅那边挖来的策划信誓旦旦的说,我们要做的这款游戏老少皆宜,肯定是爆款。要做成全球同服。上线至少 过亿注册 , 十万人同时在线 。要好好规划和设计。
我们算了下,信他能有个1亿注册。用了id范围的方式进行分片,分了 4张表 。
搞得我热血沸腾。
那天晚上下班,夏蝉鸣泣,从赤道吹来的热风阵阵拂过我的手臂,我听着泽野弘之的歌,就算是开电瓶车,我都感觉自己像是在开高达。
一年后。
游戏上线前一天通知运维加机器,怕顶不住,要整夜关注。
后来上线了,全球最高在线人数 58 人。其中有 7 个是项目组成员。
还是夏天,还是同样的下班路,想哭,但我不能哭,因为骑电瓶车的时候擦眼泪不安全。