












有位小伙伴在我的粉丝群里面问我一个面试题,说面试被问对JVM的理解,不知道怎么回答,今天咱们来聊透,就算是八股文你也得会。另外,往期面试题解析中配套的文档我已经准备好,想获得的可以在文章底部加我\/领取!
先来看什么是JVM?
1.什么是JVM
JVM(Java Virtual Machine)其实是一套标准。通过定义虚拟机,像真实计算机一样,能够运行字节码指令。JVM的好处是可以屏蔽操作系统的细节, 使Java可以一次编写,到处运行。
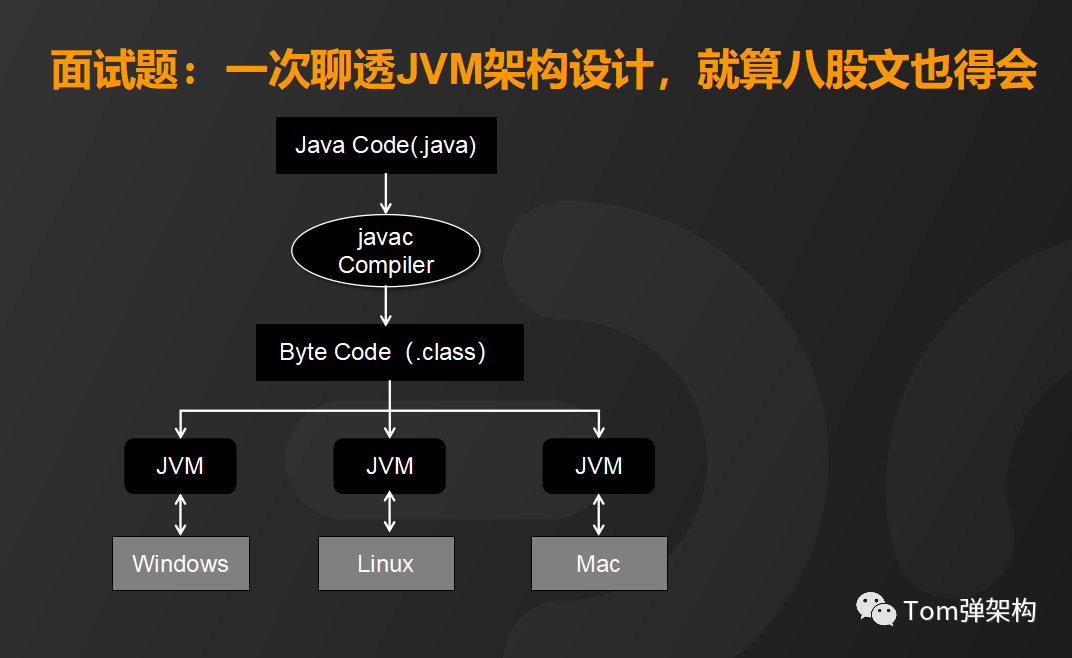
实现JVM的厂商有很多,比如Hotspot、JRockit、IBM J9等等。今天我们重点来聊一聊主流的Hotspot,因为Oracle JDK与OpenJDK都是采用HotSpot VM。从源码层面说,它们俩基本上没什么区别。
2.JVM架构设计
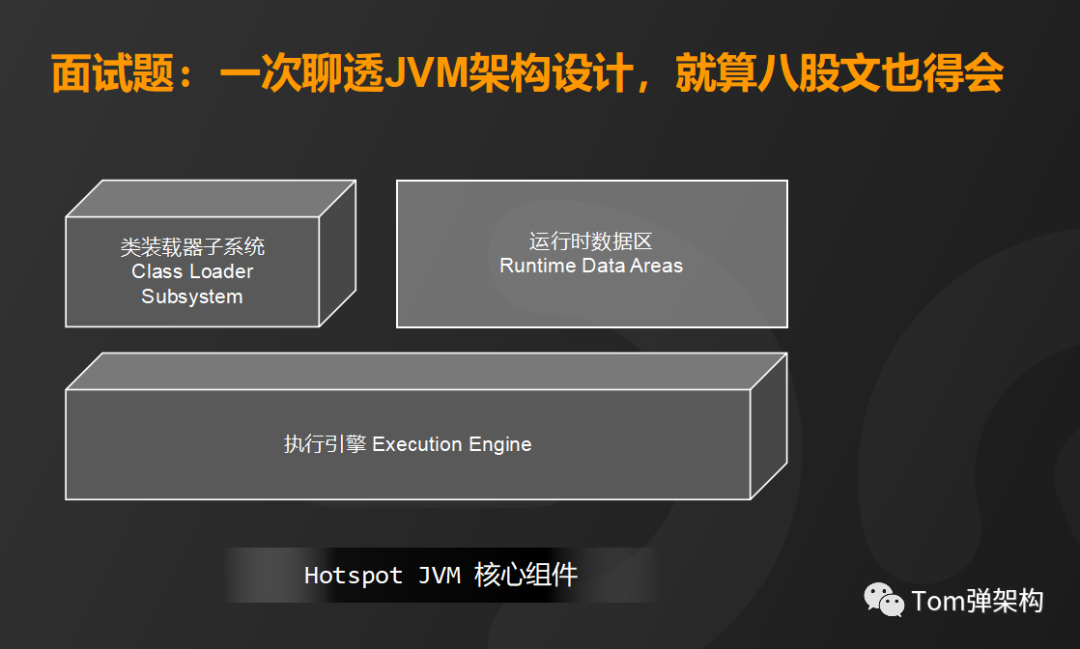
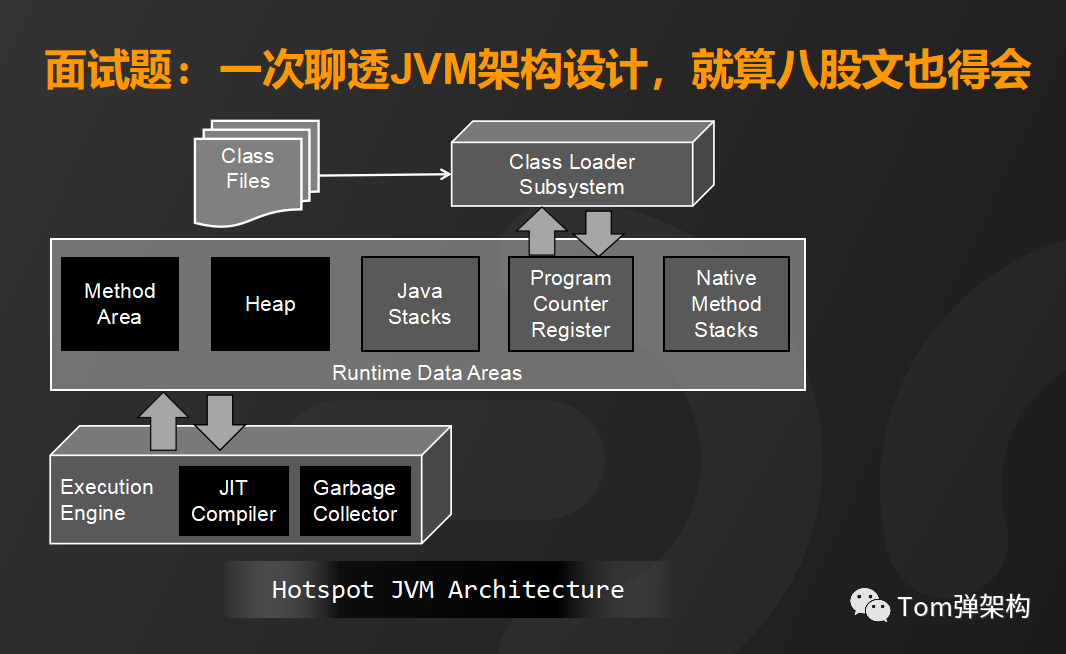
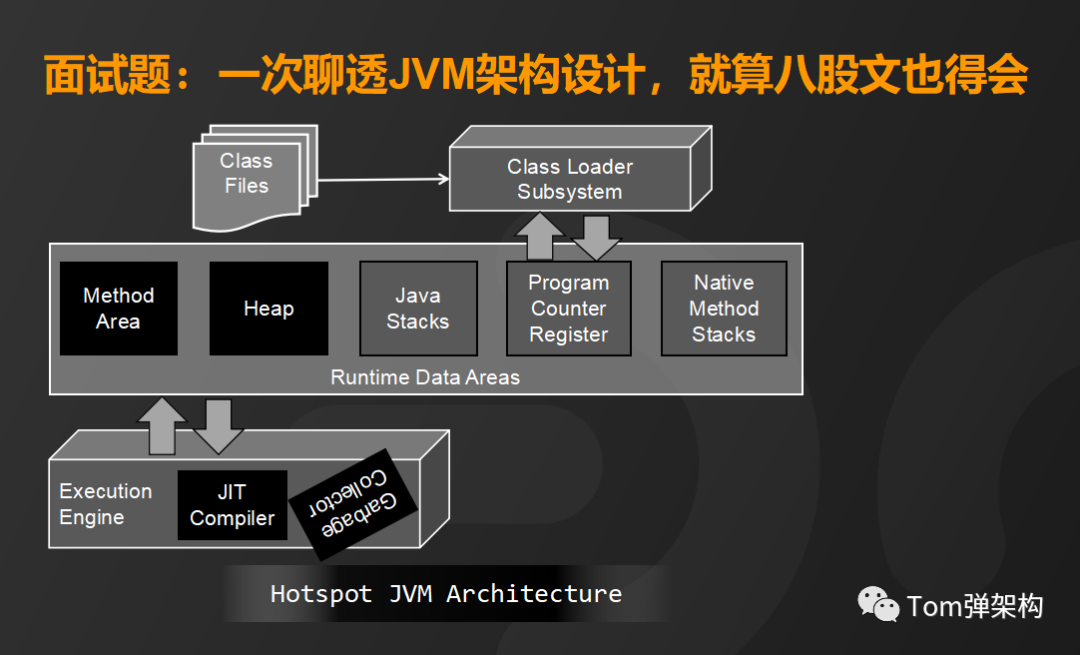
下面我给大家详细介绍一下JVM的架构设计,总体来看HotSpot VM 主要由3个核心部分组成:
- 类装载子系统(Class Loader Subsystem)
- 运行时数据区(Runtime Data Areas)
- 执行引擎(Execution Engine)
那么Hotspot JVM架构细节和运行机制又是怎样的呢?首先,将编译好的.class文件装载到类加载子系统,它的主要功能是查找并验证类文件、完成相关内存空间的分配和对象赋值。
类文件加载到内存之后由运行时数据区来完成数据存储和数据交换。运行时数据区又分为线程共享内存区和线程隔离内存区。线程共享内存区包括方法区和堆区,它们是程序员能够通过编写代码直接操作的内存区,而线程隔离内存区包括栈区、程序计数器和本地方法栈,它们是完全由JVM来调度的内存区域。
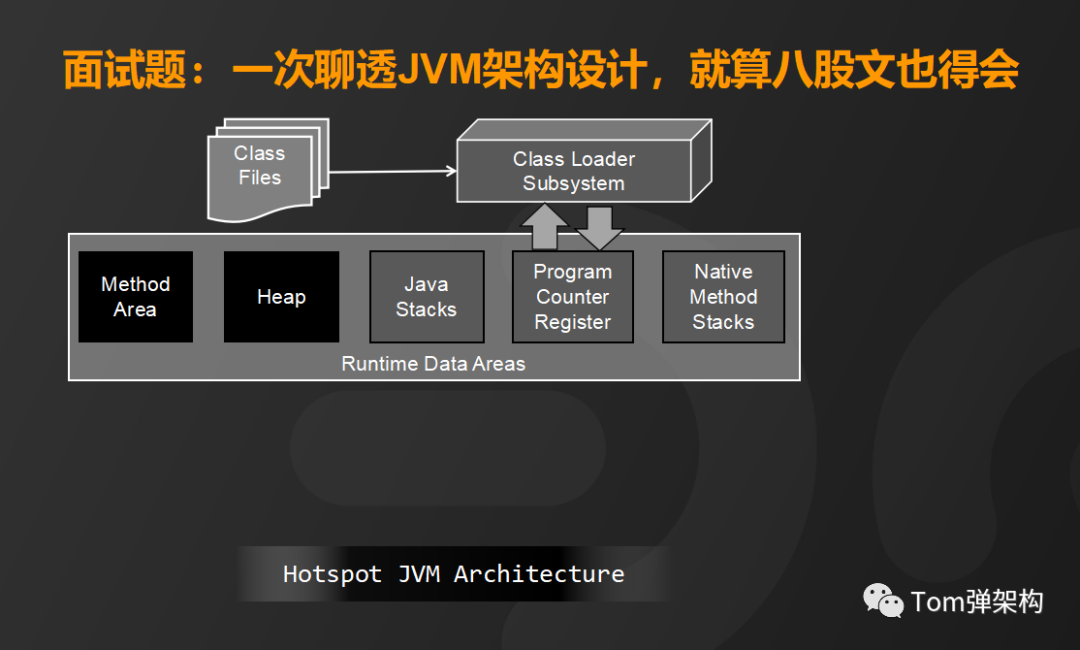
首先来看方法区,它的主要功能是存储运行时常量池、字段和方法的元数据和类的的元数据。
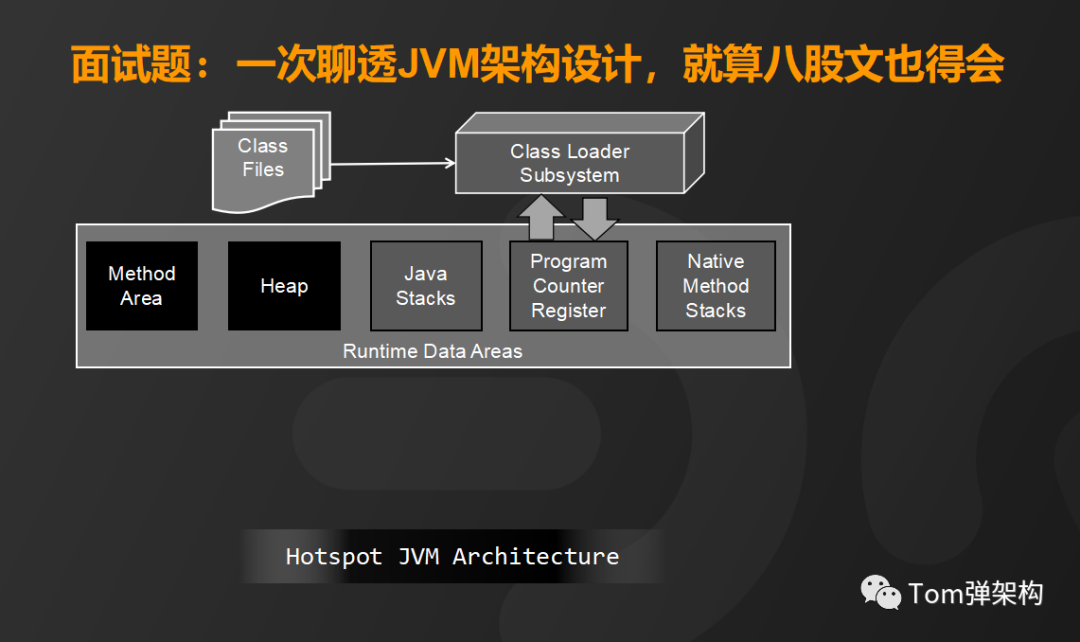
而堆区呢,主要是用来存储Java对象的实例,也就是我们new的类都存在堆区。
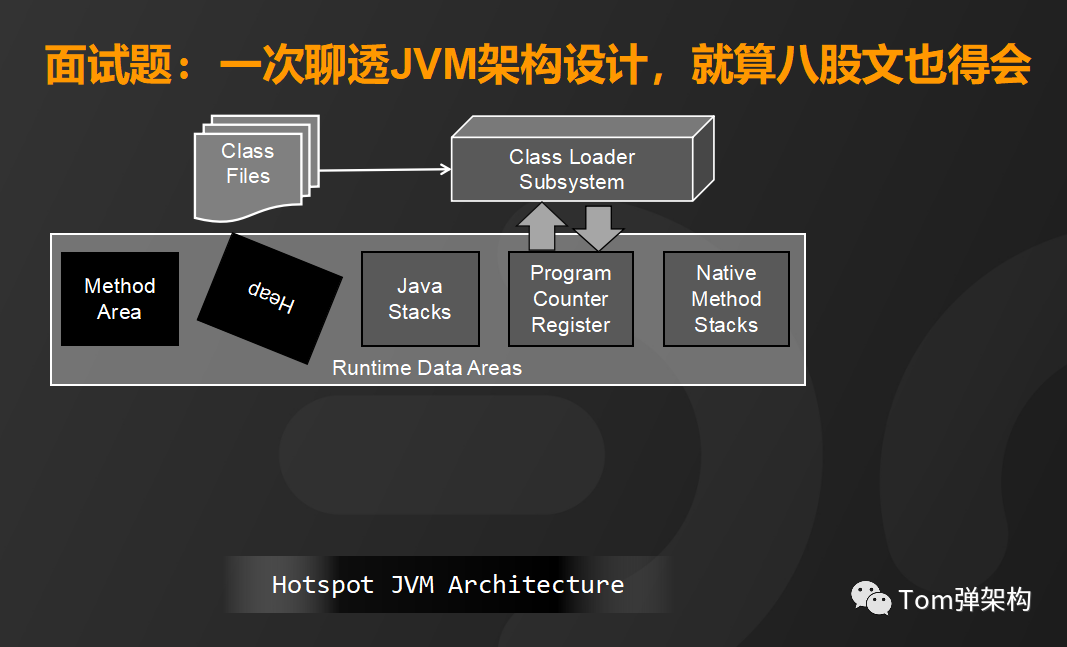
栈区是通过线程的方式运行来加载各种方法。
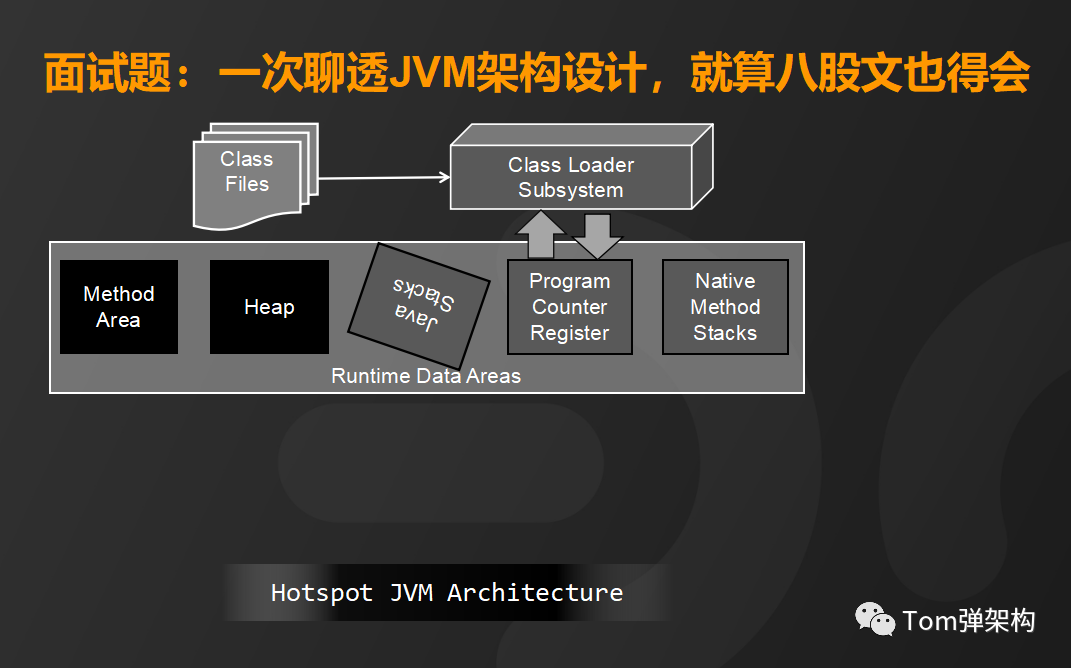
程序计数器呢,是负责保存每个线程执行的方法的地址。
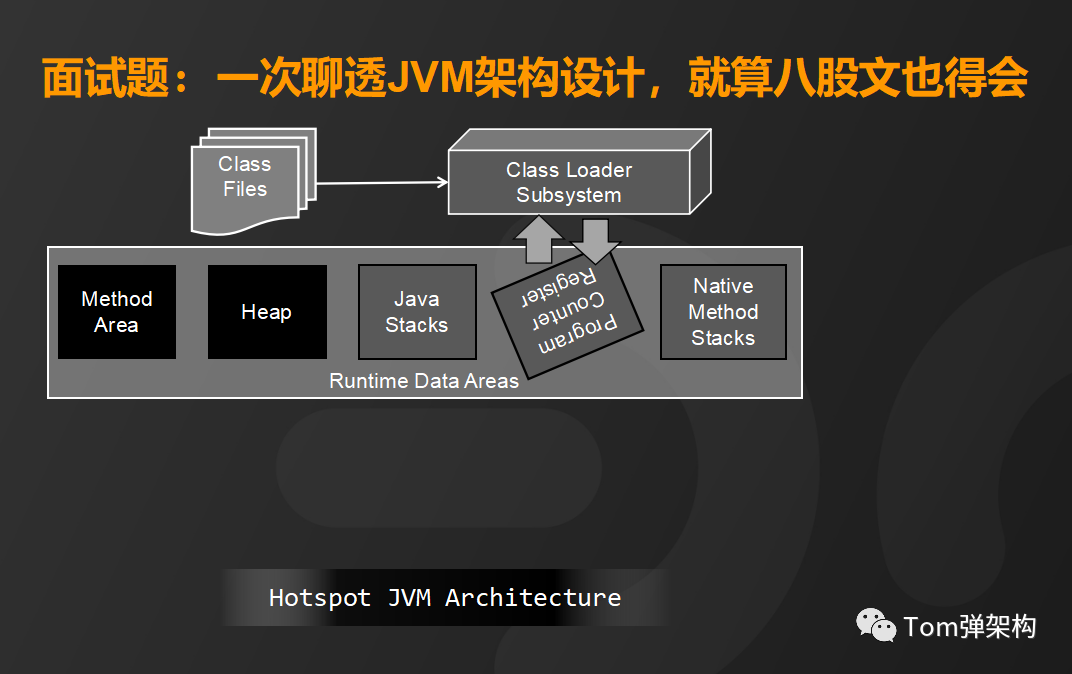
本地方法区是负责加载并运行native类型的方法,
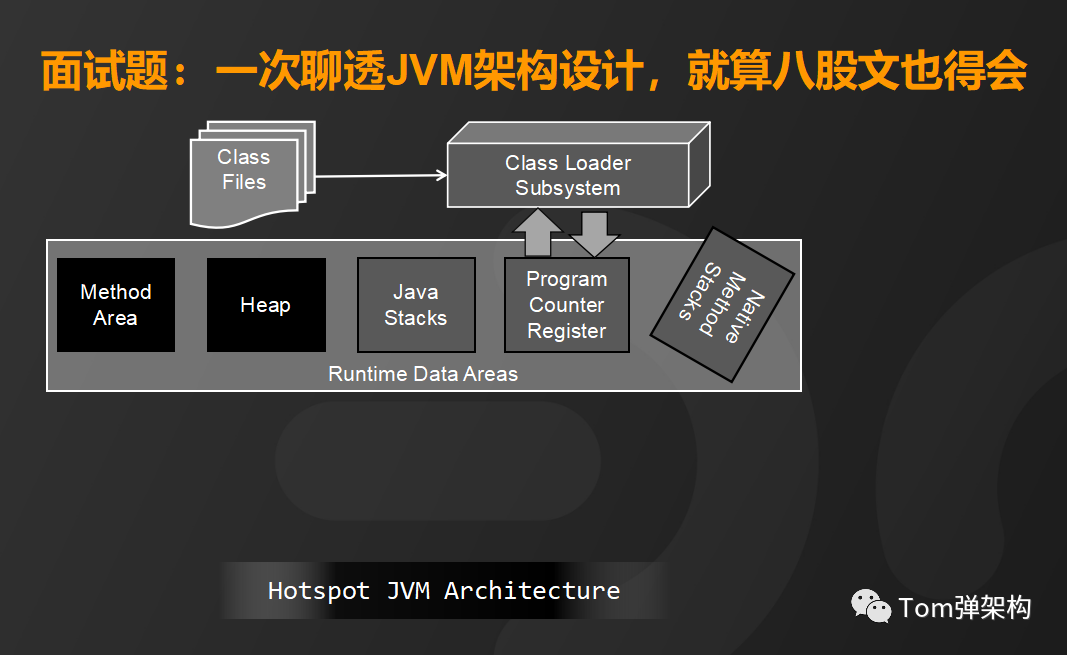
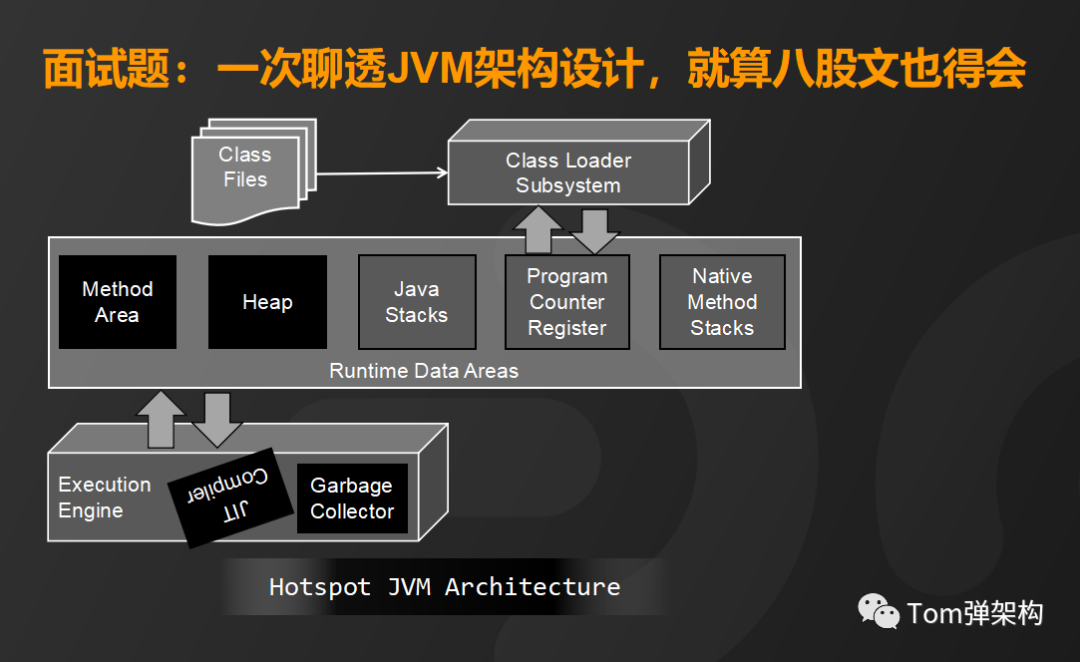
这样,通过运行时数据区的五个内存区就能完成Java程序程序逻辑的执行和数据交换。接下来看执行引擎,它主要包含即时编辑器和垃圾回收器。
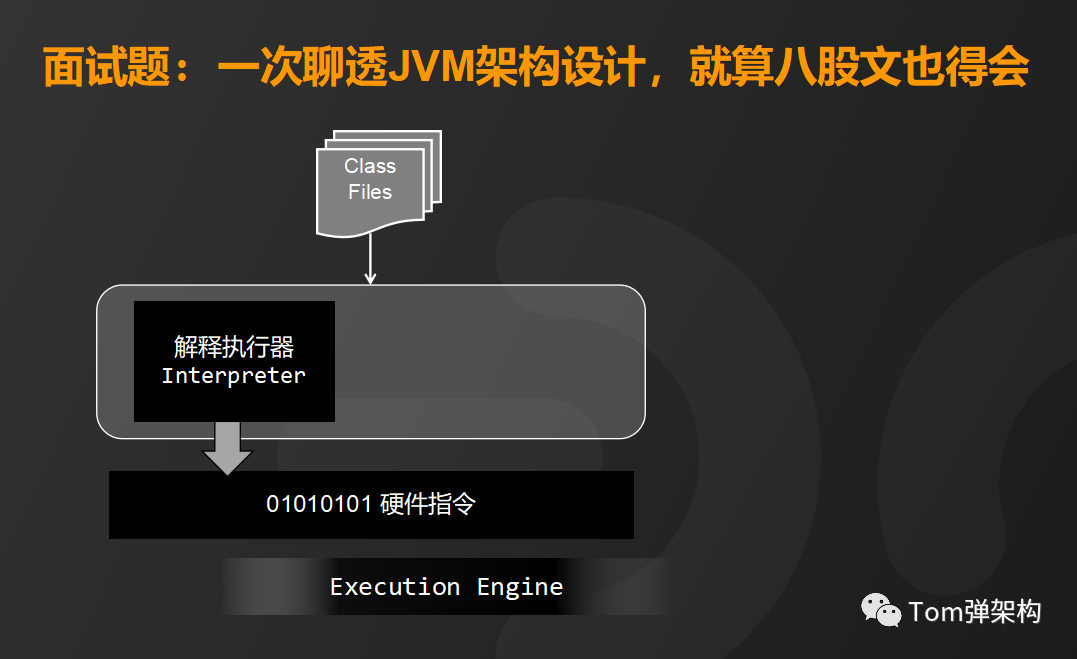
即时编译器,通俗地理解就是用来将字节码翻译成操作系统能够执行的CPU指令,可以通过JVM参数来设置选择解释执行或者是编译执行。
所谓解释执行就是直接将字节码作为源程序输入解释执行,不必等待编译器全部编译完成再执行,这样可以省去许多不必要的编译时间。
而编译执行就是就是由编译程序将目标代码一次性编译成目标程序,再由机器运行,执行效率更高,占用内存资源也更小
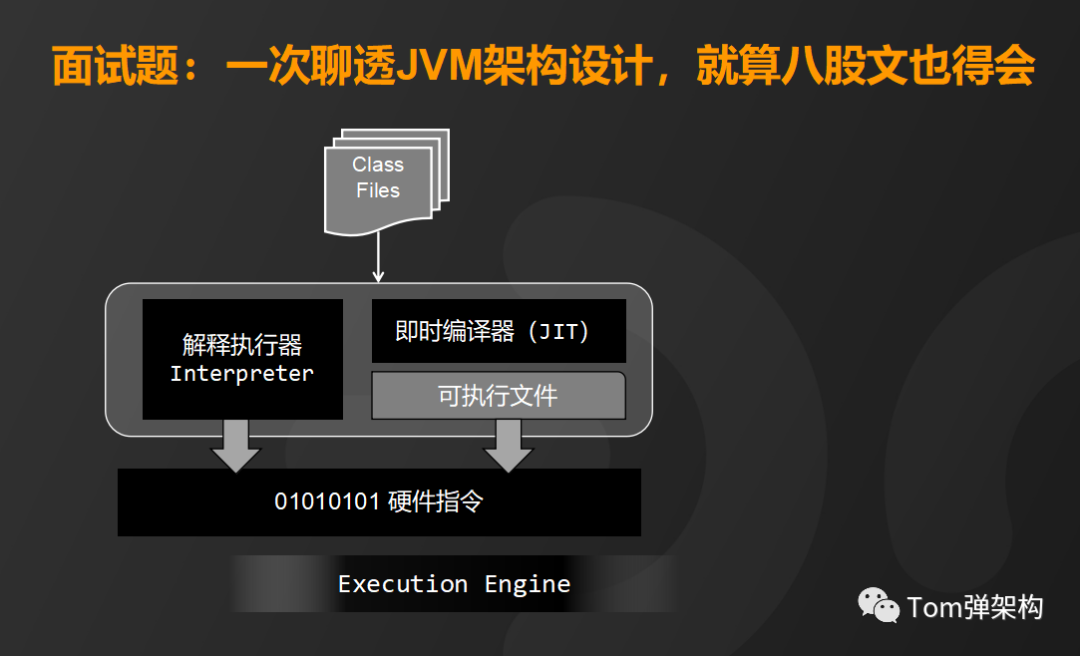
在Hotspot的实现中默认是两种方式的组合。
垃圾回收器主要负责对运行时数据区的数据进行管理和回收,其实就是对各种垃圾回收算法的实现,总体来说有三种核心算法,分别是复制算法、标记清除算法和标记整理算法,这些算法的选择呢,我们可以通过JVM参数来设置。
最后,来看本地方法接口,也就是JNI技术。我们可以通过JNI来查找并调用C或C++实现的代码,还可以调用操作系统的动态链接库(DLL)等等。
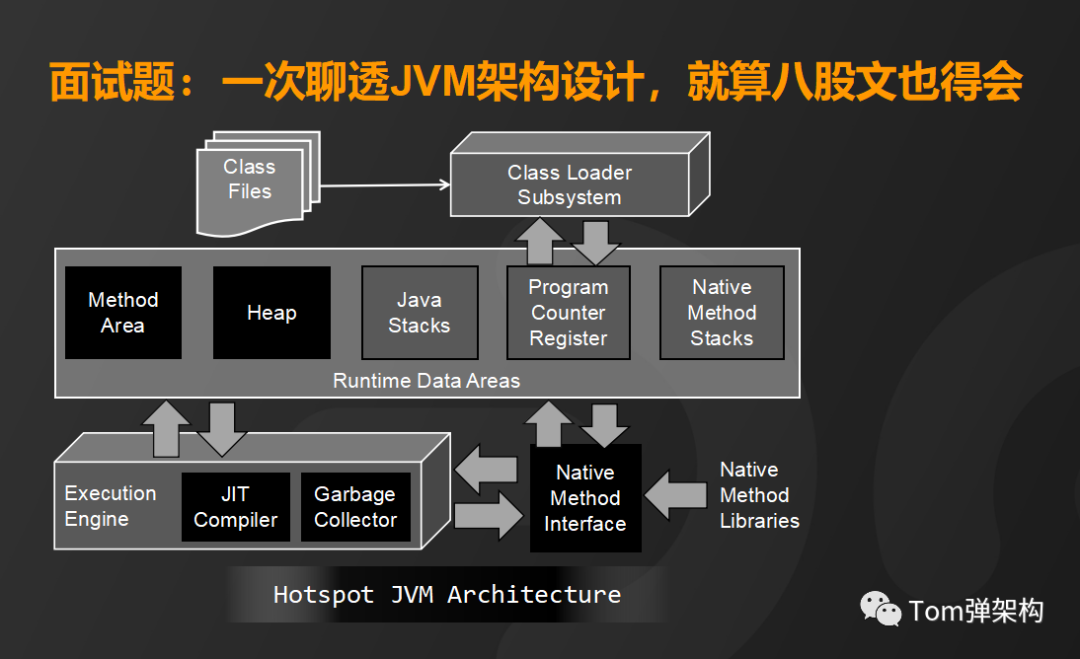
3、总结
好了,通过对Hotspot架构的分析,相信各位小伙伴已经非常清晰地知道了JVM的运行原理。当然,在实际的开发过程中,我们可以通过配置JVM参数来对JVM进行调优,比如这些参数。

还可以通过一些常见的JDK命令来分析JVM的状态,查找问题的原因从而完成对JVM的调优,比如这些命令。




















