1. 准备工作
1.1 理论基础
在并发场景下,实现数据的正确写入,主要需理解“锁”相关的原理和技术。
并发时写数据,需要考虑要不要上锁,根本原因是,数据存在共享且数据会发生变化,即多线程会同时读写同一数据。 若数据不存在共享,即不同的线程读写不同的数据,不需要上锁; 若数据共享,所有线程对数据只读不写,也不需要上锁 若数据共享,有的线程读数据,有的线程写数据,则需要上锁。
当多个线程同时访问同一数据,并且至少有一个线程会写这个数据,这种情况被称之为“数据竞争”。
并发场景下,锁的作用,是并发改为串行,以保证数据的一致性(更具体而言,通过上锁,解决了并发执行程序时的原子性、可见性和有序性问题,有兴趣的同学可以近一步深入相关理论,本文以实战为主,不在展开)。
故,在并发场景下读写数据,首先要分析是否存在“数据竞争”问题,若存在,需要“上锁”。数据竞争如果发生在本地应用中,则用本地锁;如果发生在分布式服务间中,则使用分布式锁;本地锁和分布式锁在原理上相同,不用分别讨论。
锁相关技术,有“悲观锁”和“乐观锁”两种。
(1)悲观锁
我们通常说的锁,如无特殊说明,就是指“悲观锁”。它是通过一些技术手段,实现线程或服务间的互斥和同步,其使用时,有显示(或隐式)的锁持有/释放操作。 由于上锁本身要损耗性能,上锁后并发处理变成串行,故上锁是比较影响系统性能的操作;且锁的应用不当,会潜在死锁/活锁风险;故悲观锁的使用要慎重。
(2)乐观锁
乐观锁通常又叫“无锁技术”,它不是通过“上锁”把并发改串行的方式保证数据一致性,而是通过CAS(Compare And Swap)方式来实现,由于CAS通常很快,该过程也不用“上锁”,性能损耗少。不过,通过CAS并发写数据时,通常伴有“自旋”,即当出现多个写并发时,只有一个能写入成功,其他要自旋后再次写入,直至写入成功或因超时/超过重试次数失败。 自旋会带来性能开销,频繁自旋的性能开销会超过上锁。故乐观锁通常用在并发不太激烈的场景中,且在该场景下性能比悲观锁要好,而在高并发场景下,建议使用悲观锁。
1.2 业务场景及分析
本文主题是介绍并发写数据的几种方案,为此,我们先确立几个常用的业务场景,并做简单分析。
写数据,我们讨论最常见的把数据写入数据库的场景,主要包括新建数据和修改数据两种具体场景,两个场景不完全一致,分别讨论。
(1) 往数据库写新数据
往数据库里写信数据时,如果数据直接相互独立,即不存在“数据竞争”,则按照1.1节的理论,此时不需要考虑锁的问题。
对于存在“数据竞争”的场景,我们考虑写入流水码的场景:假设创建数据有个编码字段,形如“CON_0001”,其后半段的“0001”是流水码,需要根据当前最大的流水码+1 来计算待创建数据的流水码。这里存在数据范围的竞争,并发创建数据时,如果不做并发控制,会创建多个编码相同的数据。
(2)更新数据库记录
并发更新数据库记录时,如果可以确保各并发请求要更新的数据各不相同,则不存在“数据竞争”,不需要上锁;而并发更新同一数据记录时,如果不做并发控制,可能出现一个写请求覆盖另一个写请求的情况,导致最终结果错误。
这里我们考虑“访问量+1”的场景,即设计一个访问量表,每次请求给访问量+1,如当前访问量为5,若5个并发请求同时为该记录+1,正确的结果为10,但如果不加并发控制,结果通常会<10。
2. 并发插入流水码的实现方案
2.1 业务逻辑分析
业务逻辑如下:
- 取出当前数据库中流水码最大的一条记录
- 从编码字段中解析出当前最大流水码
- 流水码+1,创建新纪录入库
代码实现即:
private Integer addEntity() {
ConcurrentEntity entity = dataMapper.getLatestConcurrentEntity();
int nextNumber = entity == null ? 1 : getNextNumberByCode(entity.getCode());
String code = String.format("CON_%04d", nextNumber);
return dataMapper.insertConcurrentEntity(new ConcurrentEntity(code));
}
private int getNextNumberByCode(String code) {
int index = code.lastIndexOf("_");
String number = code.substring(index + 1);
return Integer.parseInt(number) + 1;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
该业务在并发场景下,主要存在原子性隐患,即 addEntity() 中的代码,需要作为一个整体全部执行完,若多个线程交替执行执行逐行代码,某个线程读取到最新流水码后,该码被其他线程改了,本线程不可知,导致写入错误数据。
故本业务场景的并发中,主要避免原子性和可见性问题,最直接的方式,是通过上锁解决。
2.2 实现方案
2.2.1 方案1:在代码中上锁
private final Lock lock = new ReentrantLock(false);
public Integer addEntityByLock() {
synchronized (this) {
return addEntity();
}
}
public Integer addEntityByLock2() {
lock.lock();
try {
return addEntity();
} finally {
lock.unlock();
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
在分布式系统中,lock可以用redisson或curator提供的分布式锁进行实例化。
2.2.2 方案2: 在数据库中上锁
锁除了可以在代码中用,也可以直接用到数据库上, select ... for update 语句即可在数据库中上写锁,另由于业务执行的原子性问题,需要把 addEntity() 中的逻辑放到同一个事务中去。
@Transactional(isolation = Isolation.REPEATABLE_READ)
public Integer addEntityByTransactionWithLock() {
return addEntity();
}
- 1.
- 2.
- 3.
- 4.
这里的事务隔离级别,选择RC或RR均可。
注,这个实现中,addEntity()中对 ConcurrentEntity 的查询,改成了加锁读的方式:
@Select("SELECT * FROM concurrent_entity\n" +
"ORDER BY code DESC\n" +
"LIMIT 1\n" +
"FOR UPDATE;")
ConcurrentEntity getLatestConcurrentEntityWithWriteLock();
- 1.
- 2.
- 3.
- 4.
- 5.
2.2.3 性能对比
对于1000个并发请求,三种方法性能对比如下:
executeConcurrentAddByLock1: 1000 并发,花费时间 1179 ms
executeConcurrentAddByLock2: 1000 并发,花费时间 863 ms
executeConcurrentAddByTransactionWithLock: 1000 并发,花费时间 1284 ms
- 1.
- 2.
- 3.
2.3 其他方案
本业务场景中,由于流水码的计算,存在数据竞争问题,所以并发时需要上锁,如果能避免数据竞争,就可以避免并发问题。针对本案例,可以把流水码获取的逻辑放到redis中去,redis本身是单线程的,避免了流水码的数据竞争,进而避免了上锁的开销,而redis本身又是高性能的,故这个方案理论上比上述方案的性能只高不低。
3. 并发更新访问量的实现方案
3.1 业务分析
并发更新数据库中的访问量时,存在的“数据竞争”问题,也是“原子性”隐患。如果更新本身是一个原子操作,则不存在并发问题;如果更新操作分两步,先读取当前数据,然后+1后重新写入,则该操作不是原子的,需要上锁。
3.2 实现方案
3.2.1 方案1: 原子更新
public Integer increaseVisitCountAtomically(int id) {
return dataMapper.increaseConcurrentVisitAtomic(id);
}
@Update("UPDATE concurrent_visit\n" +
"SET visit = visit + 1, update_time = NOW()\n" +
"WHERE id = #{id};")
Integer increaseConcurrentVisitAtomic(int id);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
3.2.2 方案2: 代码中上锁
public Integer increaseVisitCountByLock(int id) {
synchronized (this) {
return increaseVisitCount(id);
}
}
private Integer increaseVisitCount(int id) {
ConcurrentVisit concurrentVisit = dataMapper.getConcurrentVisitObject(id);
concurrentVisit.increaseVisit().updateUpdateTime();
return dataMapper.updateConcurrentVisit(concurrentVisit);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
3.2.3 方案3: 数据库中上锁
@Transactional()
public Integer increaseVisitCountByTransaction(int id) {
return increaseVisitCount(id, true);
}
private Integer increaseVisitCount(int id, boolean withLock) {
ConcurrentVisit concurrentVisit = withLock ? dataMapper.getConcurrentVisitObjectWithLock(id)
: dataMapper.getConcurrentVisitObject(id);
return dataMapper.increaseConcurrentVisit(concurrentVisit.increaseVisit().updateUpdateTime());
}
@Select("SELECT * FROM concurrent_visit\n" +
"WHERE id = #{id}\n" +
"FOR UPDATE;")
ConcurrentVisit getConcurrentVisitObjectWithLock(int id);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
3.2.4 方案4: 使用乐观锁
使用乐观锁时,需要一个递增的版本字段( version ),每次update 成功时,version都要 +1,version要作为更新前的compare字段,若当前读到的version与数据库中的version不一致,则更新失败。
public Integer increaseVisitCountOptimistically(int id) {
ConcurrentVisit concurrentVisit = dataMapper.getConcurrentVisitObject(id);
return dataMapper.increaseConcurrentVisitOptimistically(concurrentVisit.increaseVisit().updateUpdateTime());
}
@Update("UPDATE concurrent_visit\n" +
"SET visit = #{visit}, update_time = #{updateTime}, version = #{version} + 1\n" +
"WHERE id = #{id} and version = #{version};")
Integer increaseConcurrentVisitOptimistically(ConcurrentVisit concurrentVisit);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
使用乐观锁时,compare不一致,会更新失败,这时需要自旋重试,故上述代码可以优化为:
public Integer increaseVisitCountOptimisticallyWithRetry(int id) {
int result = 0;
int maxRetry = 5;
long interval = 20L;
for (int i = 0; i < maxRetry; i++) {
result = increaseVisitCountOptimistically(id);
if (result > 0) {
break;
}
interval = interval + i * 50;
helper.sleep(interval);
}
return result;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
3.2.5 性能比较
发起10000个并发更新操作,结果如下:
executeConcurrentAddAtomically: 10000 并发,花费时间 2112 ms
executeConcurrentAddByLock: 10000 并发,花费时间 5796 ms
executeConcurrentAddByTransaction: 10000 并发,花费时间 3902 ms
executeConcurrentAddOptimisticallyWithRetry: 10000 并发,花费时间 5998 ms
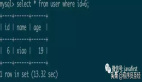
mysql> select * from concurrent_visit;
+----+-------------+-------+---------+---------------------+---------------------+
| id | resourceKey | visit | version | create_time | update_time |
+----+-------------+-------+---------+---------------------+---------------------+
| 1 | resource1 | 39925 | 9925 | 2022-03-31 11:42:54 | 2022-04-01 12:06:36 |
+----+-------------+-------+---------+---------------------+---------------------+
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
可以看到:
- 并发比较激烈时,乐观锁性能最差,而且有些请求,即使超过了最大重试次数,也没更新成功
- 把锁上在数据库中,性能比所在代码上还要好,原因是,数据库上的锁是经过充分的性能优化的,而且锁的颗粒度更小,而我们这个业务场景下,代码中锁的颗粒度已经很难再缩小了。锁的颗粒度,决定了并发程度,并发场景下,锁的颗粒度越小越好