












现阶段,视觉 transformer(ViT)模型已经在图像分类、目标检测与分割等各样各样的计算机视觉任务中得到了广泛应用,并可以在视觉表征与识别中实现 SOTA 结果。由于计算机视觉模型的性能往往与参数量和训练时长呈正相关,AI 社区已经实验了越来越大规模的 ViT 模型。
但应看到,随着模型开始超出万亿次浮点运算的规模,该领域已经遇到了一些主要的瓶颈。训练单个模型可能耗费数月,需要数以千块的 GPU,进而增加了加速器需求并导致大规模 ViT 模型将很多从业者「排除在外」。
为了扩展 ViT 模型的使用范围,Meta AI 的研究者已经开发出了更高效的训练方法。非常重要的一点是对训练进行优化以实现最佳的加速器利用。但是,这一过程耗时费力且需要大量的专业知识。为了设置有序的实验,研究者必须从无数可能的优化方案中进行选择:一次训练过程中执行的百万次运算中的任何一个都有可能受到低效率的影响和阻碍。
Meta AI 发现,通过将一系列优化应用到其图像分类代码库 PyCls 中的 ViT 实现,可以提升计算和存储效率。对于使用 PyCIs 训练的 ViT 模型,Meta AI 的方法可以提升训练速度和每加速器吞吐量(TFLOPS)。
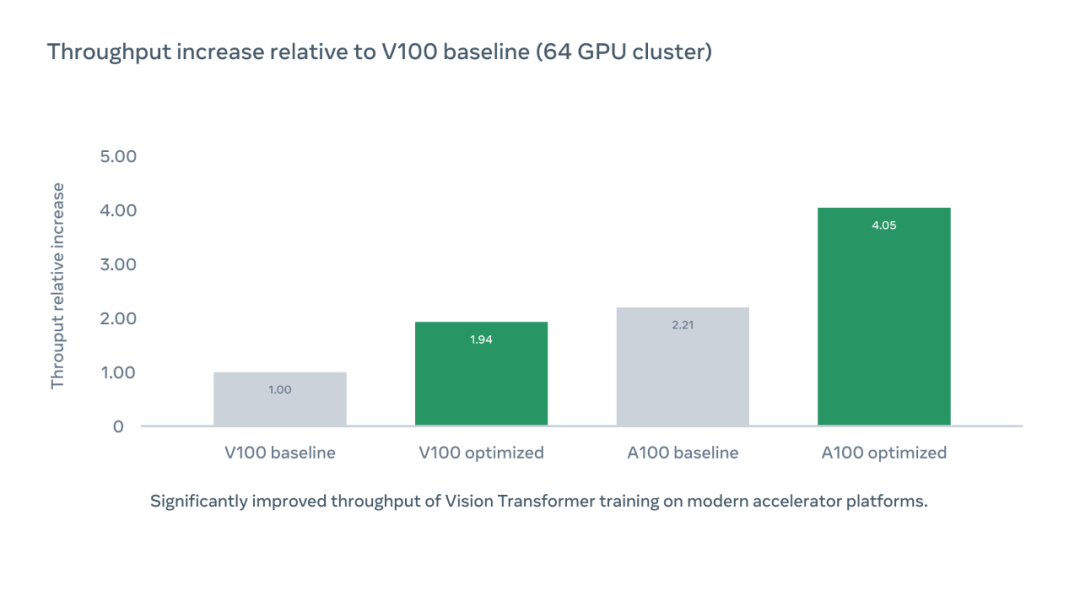
下图展示了使用优化代码库 PyCIs 后每芯片(per chip)加速器吞吐量相较于 V100 基准的相对增加,而 A100 优化的加速器吞吐量是 V100 基准的 4.05 倍。
运行原理
Meta AI 首先对 PyCIs 代码库进行分析以确认低训练效率的潜在来源,最终将注意力放在了对数字格式的选择上。在默认情况下,大多数应用使用 32-bit 单精度浮点格式来表征神经网络值。转换至 16-bit 半精度格式(FP16)可以减少模型的内存占用和执行时间,但往往也会降低准确率。
研究者采取了折中方案,即混合精度。利用它,系统通过单精度格式执行计算以加速训练并减少内存使用,同时通过单精度存储结果以保持准确率。他们没有手动地将部分网络转换至半精度,而是实验了不同模式的自动混合精度训练,这样可以在数字格式之间自动切换。更高级模式的自动混合精度主要依赖半精度运算和模型权重。研究者采用的平衡设置既能大幅度加速训练,同时也不牺牲准确率。
为了使流程更加高效,研究者充分利用了 FairScale 库中的完全分片数据并行(Fully Sharder Data Parallel, FSDP)训练算法,它在 GPU 上对参数、梯度和优化器状态进行分片。通过 FSDP 算法,研究者可以使用更少的 GPU 构建更大量级的模型。此外,研究者还使用了 MTA 优化器、一个池化的 ViT 分类器和一个 batch-second 输入张量布局来跳过冗余转置运算。
下图 X 轴为可能的优化,Y 轴为采用 ViT-H/16 训练时加速器吞吐量相较于分布式数据并行(DDP)基准的相对增加。
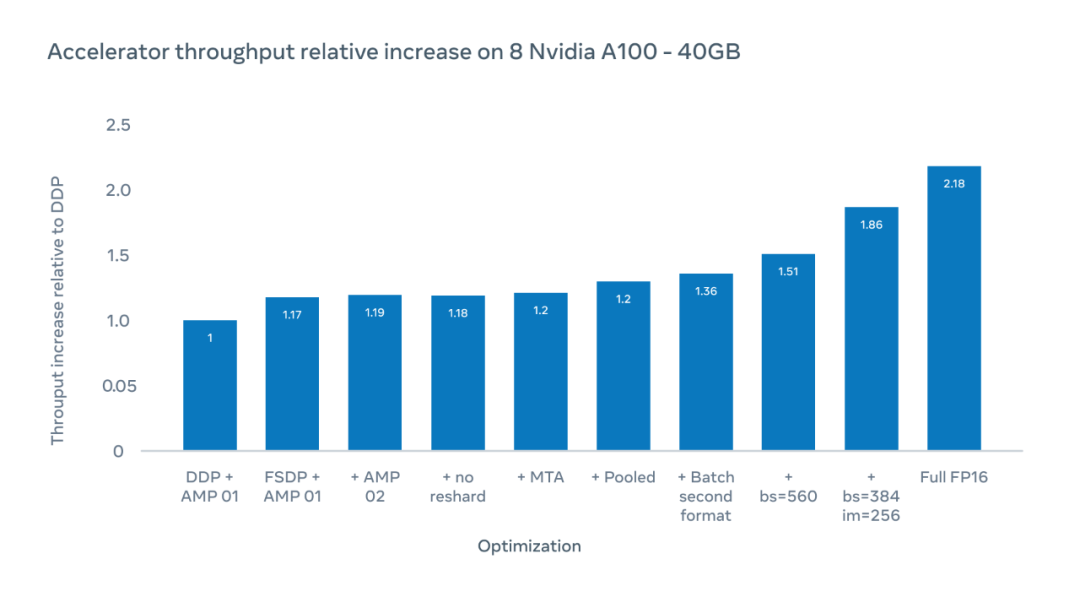
研究者在总 patch 大小为 560 时实现了 1.51 倍的加速器吞吐量提升,以每个加速器芯片上每秒执行的浮点运算数量衡量。通过将图像大小从 224 像素增加至 256 像素,他们可以将吞吐量提升至 1.86 倍。但是,改变图像大小意味着超参数的变化,这会对模型的准确率造成影响。在完全 FP16 模式下训练时,相对吞吐量增加至 2.18 倍。尽管有时会降低准确率,但在实验中准确率降低少于 10%。
下图 Y 轴为 epoch 时间,在整个 ImageNet-1K 数据集上一次训练的持续时间。这里专注于现有配置的实际训练时间,这些配置通常使用 224 像素的图像大小。
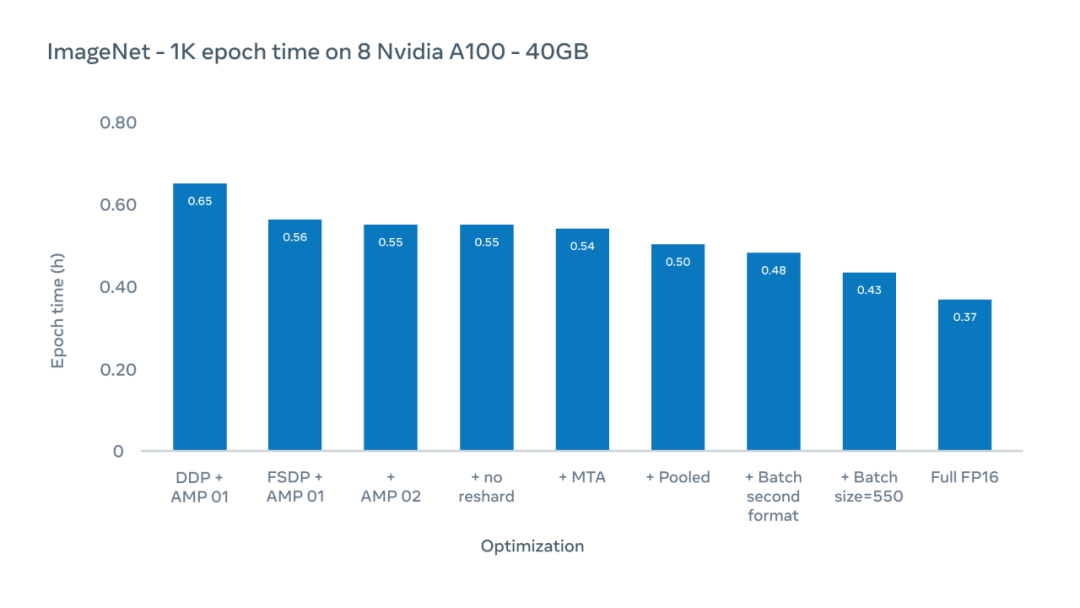
Meta AI 的研究者使用优化方案,将 epoch 时间(在整个 ImageNet-1K 数据集上一次训练的持续时间)从 0.65 小时减少到 0.43 小时。
下图 X 轴表示特定配置中 A100 GPU 加速器芯片的数量,Y 轴表示每芯片 TFLOPS 的绝对吞吐量。
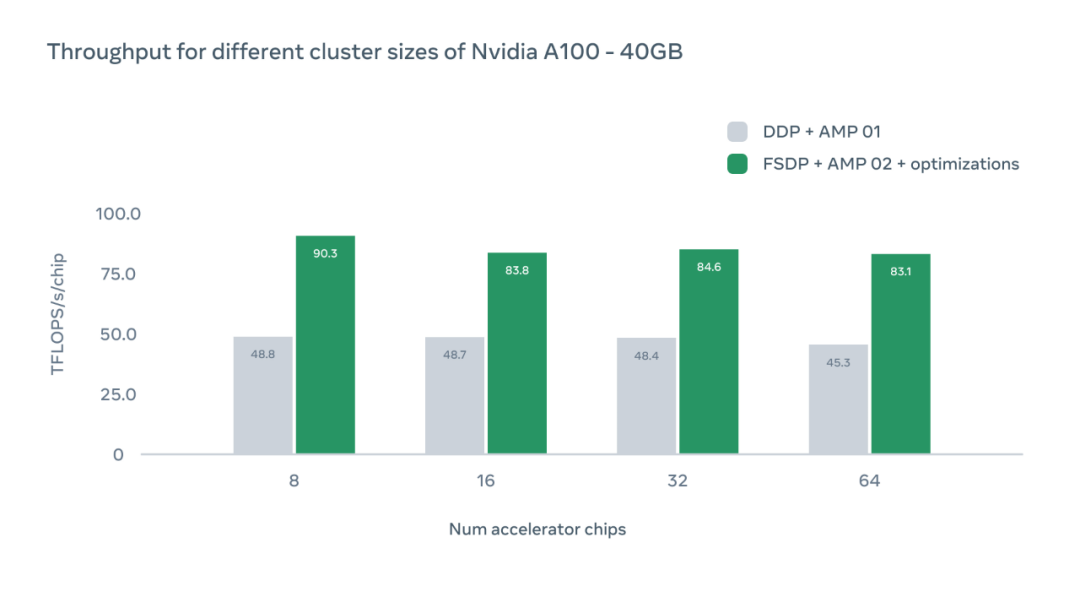
该研究还讨论了不同 GPU 配置的影响。在每种情况下,系统都实现了比分布式数据并行(DDP)基线水平更高的吞吐量。随着芯片数量的增加,由于设备间通信的开销,我们可以观察到吞吐量略有下降。然而,即使用 64 块 GPU,Meta 的系统也比 DDP 基准快 1.83 倍。
新研究的意义
将 ViT 训练中可实现的吞吐量翻倍可以有效让训练集群规模翻倍,提高加速器利用率直接减少了 AI 模型的碳排放。由于最近大模型的发展带来了更大模型和更长训练时间的趋势,这种优化有望帮助研究领域进一步推动最先进的技术,缩短周转时间并提高生产力。


























