一觉醒来,机器学习社区炸了锅。
因为最新研究发现,只要对GPT-3说一句“让我们一步一步地思考”,就能让它正确回答出以前不会的问题。
比如下面这个例子:
16个球中有一半是高尔夫球,这些高尔夫球中有一半是蓝色的,一共有几个蓝色的高尔夫球?

(问题不难,但要注意这是零样本学习,也就是说AI训练阶段从没见过同类问题。)
如果要求GPT-3直接写出“答案是几”,它会给出错误答案:8。
但加上让我们一步一步地思考这句“咒语”后,GPT-3就会先输出思考的步骤,最后给出正确答案:4!
而且这并不是巧合,研究团队在论文中做了充分的验证。
上面的问题出自经典的MutiArith数据集,专门考验语言模型做数学题的能力,GPT-3本来在零样本场景下准确率仅有17%。
这篇论文中总结了9个最有效的提示词,其中换着花样让GPT-3逐步思考的前6个都让准确率暴涨到70%以上。

甚至一句最简单的“Let’s think”(让我们想一想)都能涨到57.5%。
这感觉,就像是幼儿园阿姨在哄小朋友……
这个技巧似乎也不需要对GPT-3做魔改,已经有人在OpenAI官方Demo上成功复现,甚至换成中文也行。
英文题干中文提示,GPT-3给出正确中文答案。
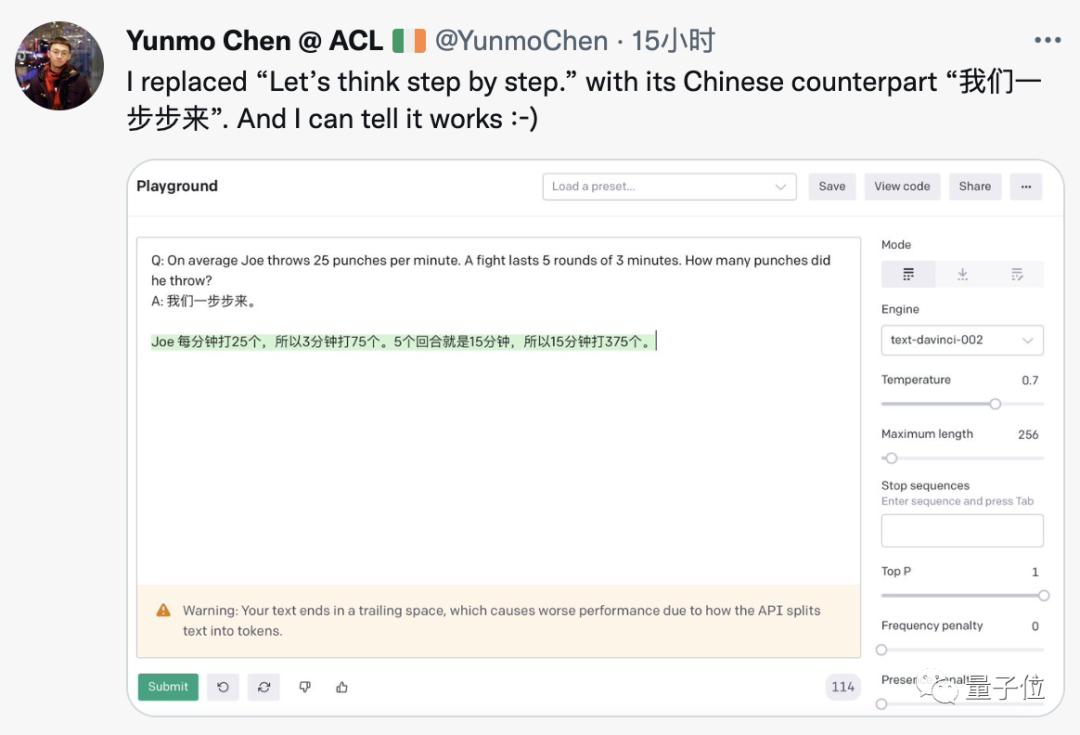
最早把这篇论文转发到社交网络的谷歌研究员表示,新的all you need增加了。
看到这里,各路大佬纷纷脑洞大开,玩起了梗。
如果鼓励AI“你能行的,我相信你”会怎样?
威胁AI一下说“时间不多了”或者“你头上有把枪”又会如何?
对AI说“开车稳一点”会成为自动驾驶解决方案吗?

还有人提出,这简直和科幻故事《银河系漫游指南》的剧情一样,实现通用人工智能的关键是知道如何正确地向AI提问。
那么,这种神奇现象究竟怎么回事?
语言大模型是零样本推理者
发现这个现象的是谷歌大脑与东京大学的合作研究,探索了语言大模型在零样本场景下的表现。
论文标题《语言大模型是零样本推理者》还致敬了GPT-3的《语言模型是少样本学习者》。

所用方法属于Chain of Thought Prompting (思维链路提示,以下简称CoT),今年一月刚由谷歌大脑团队提出。

最早的CoT应用于少样本学习,在提问的同时给一个分步骤回答的示例来引导AI。

这次的最新研究提出零样本CoT,主要改动是简化了示例的部分。
- 第一步,把题干改写成“Q:xxx,A:xxx”的形式,其中触发句A可以提取出语言模型的思考过程。
- 第二步属于额外实验,增加了“答案是……”的提示促使语言模型给出最终答案。
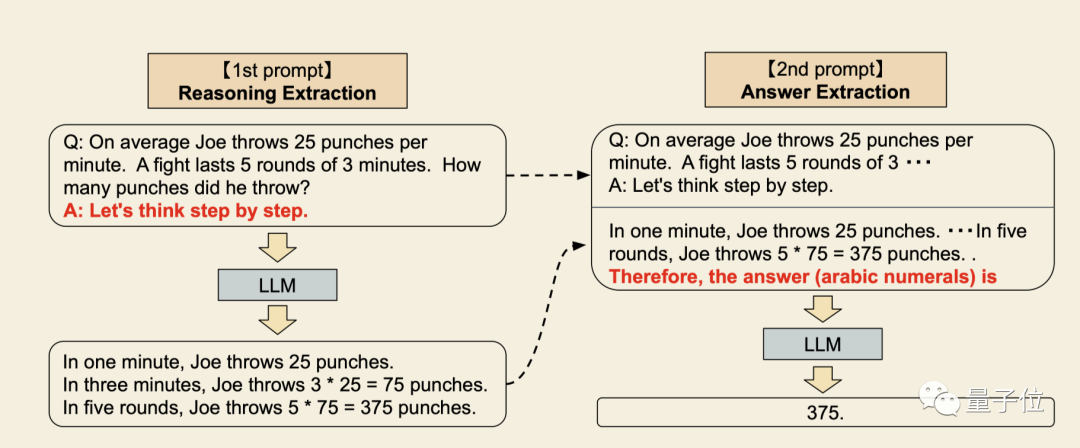
这样做最大的好处是通用,不再需要对不同问题类型提供专用的示例。
论文中对各类问题做了充分实验,包括12项测试:
- 6个数学问题测试集,SingleEq、AddSub、SVAMP和更有挑战的MultiArith, AQUA-RAT, GSM8K。
- 2个常识推理测试集,CommonsenseQA和StrategyQA。
- 2个符号推理测试集,Last Letter Concatenation和Coin Flip。
- 以及BIG-bench中的日期理解问题、跟踪乱序物体任务。
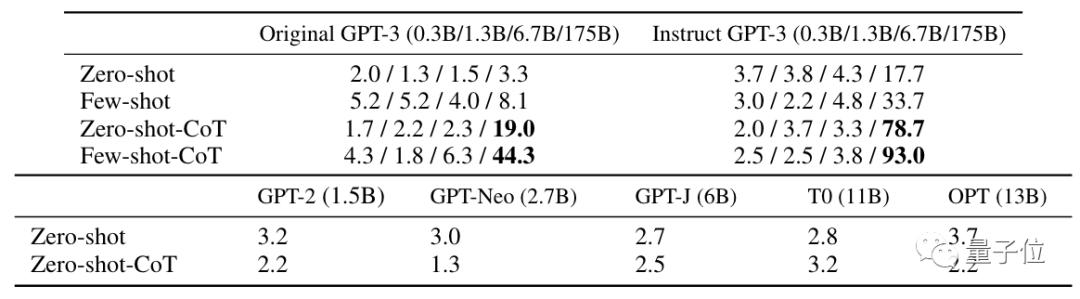
与普通的零样本学习相比,零样本CoT在其中10项中取得更好效果。
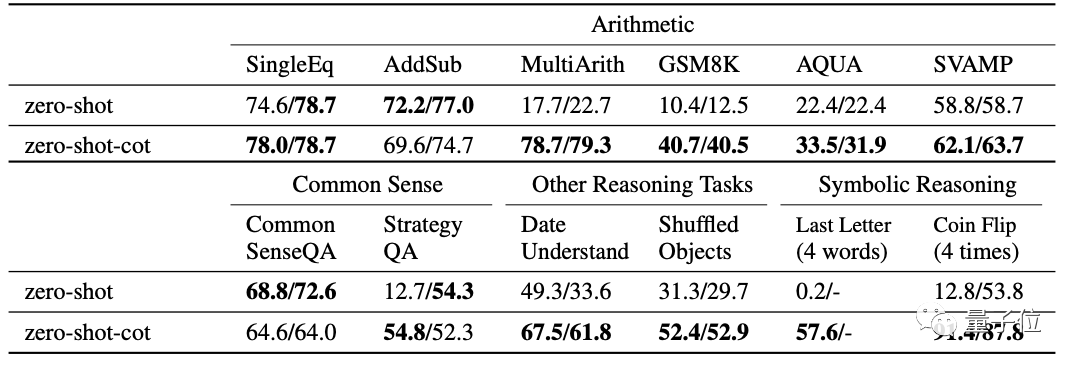
△右侧值为额外实验结果
在比较有难度的MultiArith和GSM8K数学测试中,用GPT-3最新版本Text-davinci-002 (175B)做了更深入实验。
如果给8次尝试机会取最好结果,还能进一步提升准确率至93%。
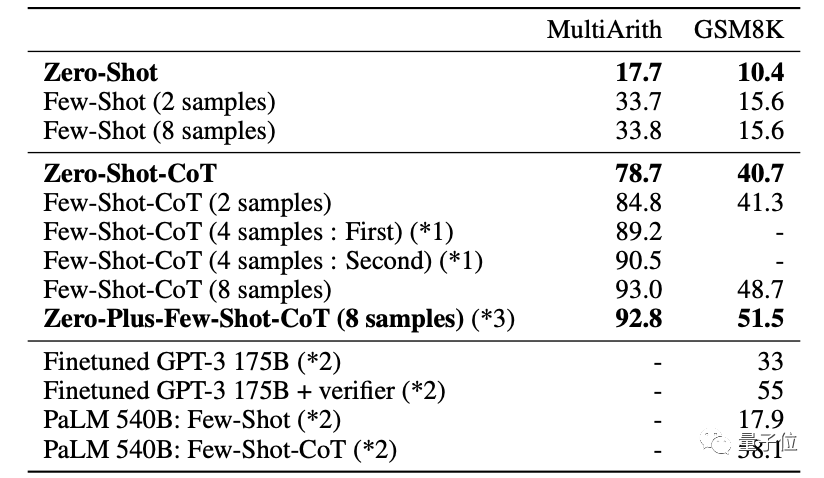
在错误结果分析中研究人员还发现,很多问题中其实AI的推理过程是正确的,只是答案无法收敛至唯一确定时会给出多个备选。

论文的最后,研究团队提出这项研究不仅可以作为零样本CoT的基线,更希望让学界认识到在构建微调数据集和少样本提示模版之前,充分发掘语言大模型零样本能力的重要性。
研究团队来自东京大学松尾研究室。

负责人松尾丰教授,同时是软银董事会中的第一位人工智能专家。

团队成员中的客座教授顾世翔来自谷歌大脑团队,顾世翔本科师从三巨头之一Hinton,博士毕业于剑桥大学。
加点“魔法”已经成为AI圈新潮了
零样本CoT究竟为何起作用还有待探索。
不过有人实验得出,这种办法似乎只对GPT-3(text-davinci-002)比较有效,他尝试了001版本,发现收效甚微。
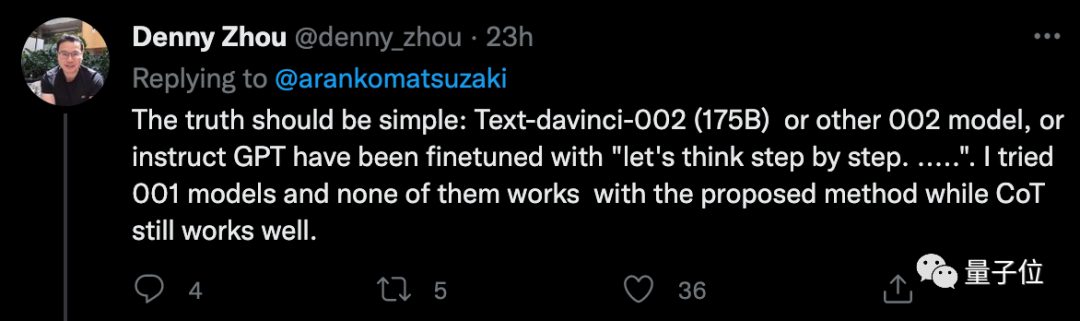
他列出了一个自己做的例子。
提问:请将machine,learning中每个单词的最后一个字母连起来。
GPT-3在提示下给出的答案是连起来了两个单词中的所有字母。

对此,作者之一顾世翔回复表示,其实“咒语”对初始版、改良版的GPT-3都有效果,这些结果在论文中也有体现。
也有人发出质疑,表示难道深度学习变成了一场找“神奇咒语”的游戏?
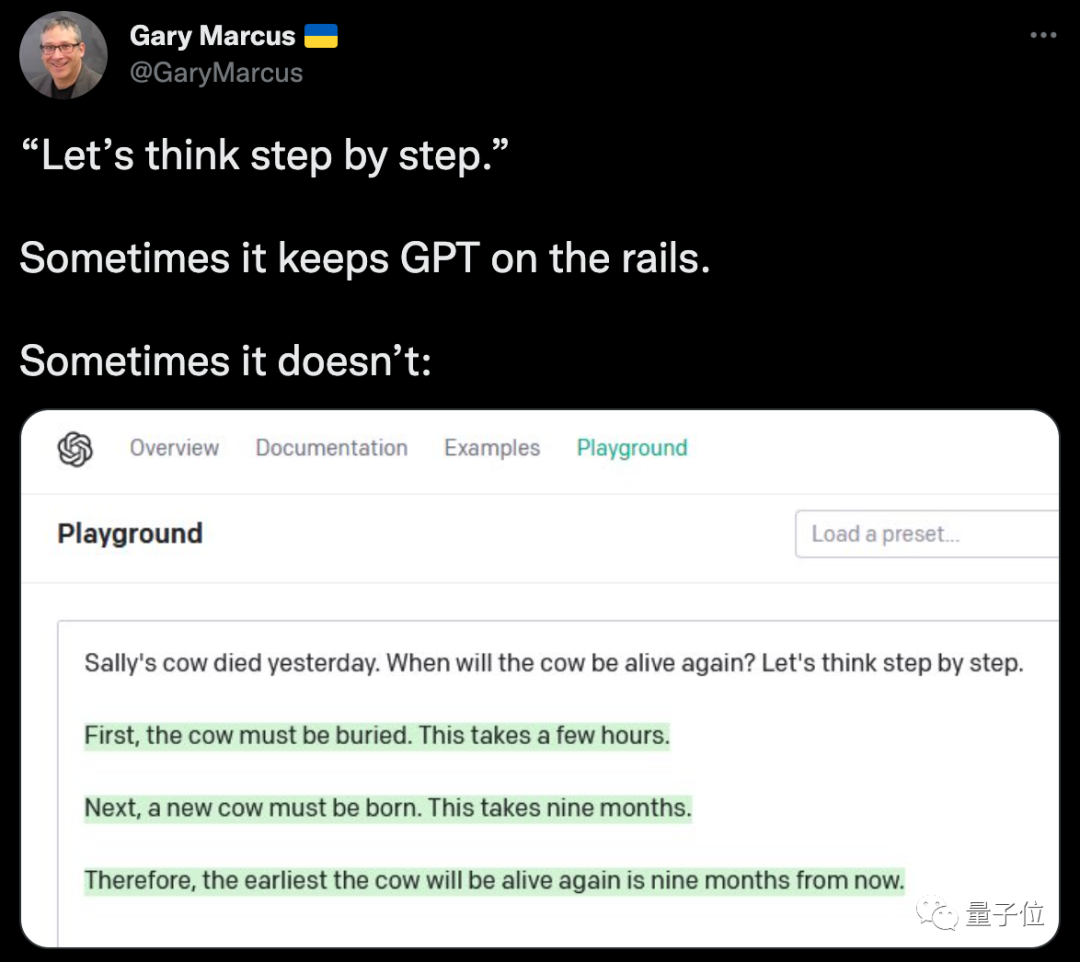
同时,我们在吐槽队伍里又看到了马库斯的身影。
他也列出了一个失败的例子,GPT-3在“咒语”加持下也没弄明白,莎莉的牛到底会不会起死回生……
不过值得注意的是,类似这种稍微给AI加点小魔法,提升效果立竿见影的例子已经不稀奇了。
有网友分享,自己用GPT-3时加几个中间命令,确实能得到更满意的结果。
此前谷歌和MIT的研究人员发现,无需更改底层架构,只要训练语言模型会像程序员debug时那样“打断点”,模型读代码、做算术的能力唰唰唰地就上去了。

原理也非常简单,就是在计算步骤较多的程序里,让模型把每一步都编码成文本,并将它们记录到一个称为“便签”的暂存器中。
由此一来,模型的计算过程变得更加清晰有序,性能自然大幅提升。
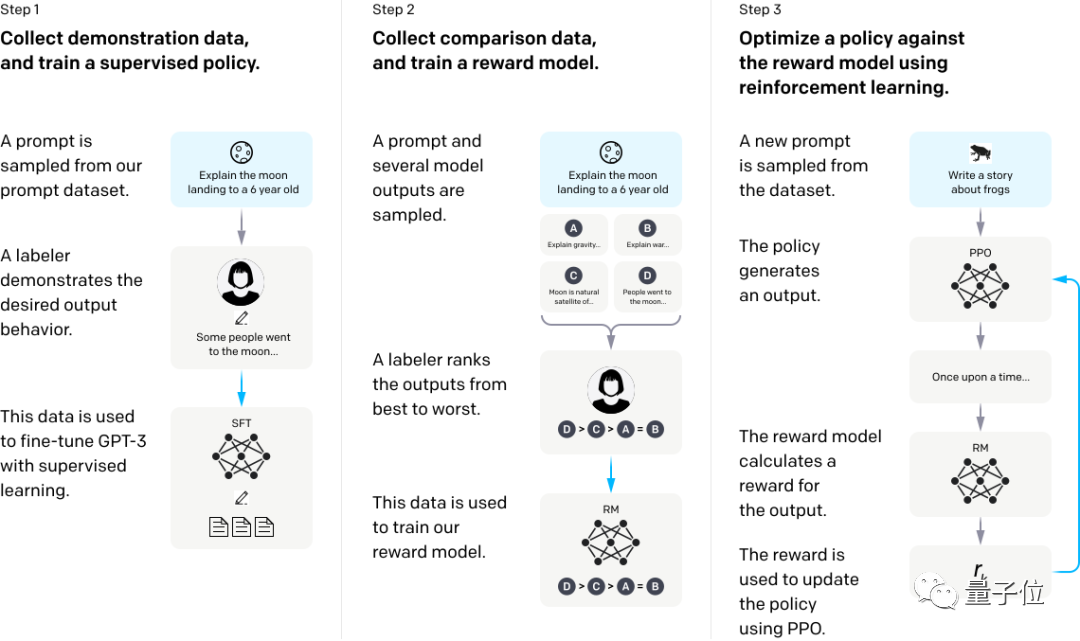
还有本项实验中用来测试的Instruct GPT-3,也是一个典型的例子。
只需让GPT-3从人类反馈中强化学习,它就能明显改善答非所问的情况。
具体来看就是先用一些人类的示范回答微调模型,然后收集某个问题的几组不同输出数据,人工对几组答案进行排序,并在此数据集上训练奖励模型。
最后,使用RM作为奖励函数,近端策略优化(PPO)算法微调GPT-3策略,以强化学习方法最大化奖励。
包括引爆这次话题的推特博主Aran,正是当初发现加一句“虚幻引擎”就能让AI生成图像画质飞升的那位。

前谷歌机器人大佬Eric Jang此前也发现,强化学习也能运用类似的思维来提升计算效率。

也有人表示,这种用在AI上的技巧,不正是自己平常动脑时会用的吗?

实际上,此前Bengio就从脑科学入手,提出AI的运转模式应该像人类动脑模式一样。
人类的认知任务可以分为系统1认知和系统2认知。
系统1认知任务,是指那些无意识完成的任务。比如你可以马上辨别出手里拿的是什么东西,但是却无法和别人解释,自己是怎么完成这个过程的。
系统2认知任务,是指人类大脑需要按照一定步骤完成的认知。比如做一道加减法运算,你可以很清楚地解释最终答案是如何得出的。
而这次加的“咒语”,正是让AI更进一步,学会按步骤来思考。
面对这样的趋势,有学者认为“提示工程正在取代特征工程”。
那么“提示词猎人”会成为下一代NLP研究者的外号么?

论文地址:https://arxiv.org/abs/2205.11916
参考链接:
[1]https://twitter.com/arankomatsuzaki/status/1529278580189908993
[2]https://evjang.com/2021/10/23/generalization.html