作者 | 磊哥
来源 | Java面试真题解析(ID:aimianshi666)
转载请联系授权(微信ID:GG_Stone)
单例模式的实现方法有很多种,如饿汉模式、懒汉模式、静态内部类和枚举等,当面试官问到“为什么单例模式一定要加 volatile?”时,那么他指的是为什么懒汉模式中的私有变量要加 volatile?
懒汉模式指的是对象的创建是懒加载的方式,并不是在程序启动时就创建对象,而是第一次被真正使用时才创建对象。
要解释为什么要加 volatile?我们先来看懒汉模式的具体实现代码:
public class Singleton {
// 1.防止外部直接 new 对象破坏单例模式
private Singleton() {}
// 2.通过私有变量保存单例对象【添加了 volatile 修饰】
private static volatile Singleton instance = null;
// 3.提供公共获取单例对象的方法
public static Singleton getInstance() {
if (instance == null) { // 第 1 次效验
synchronized (Singleton.class) {
if (instance == null) { // 第 2 次效验
instance = new Singleton();
}
}
}
return instance;
}
}
从上述代码可以看出,为了保证线程安全和高性能,代码中使用了两次 if 和 synchronized 来保证程序的执行。那既然已经有 synchronized 来保证线程安全了,为什么还要给变量加 volatile 呢?在解释这个问题之前,我们先要搞懂一个前置知识:volatile 有什么用呢?
一、volatile 作用
volatile 有两个主要的作用,第一,解决内存可见性问题,第二,防止指令重排序。
1、 内存可见性问题
所谓内存可见性问题,指的是多个线程同时操作一个变量,其中某个线程修改了变量的值之后,其他线程感知不到变量的修改,这就是内存可见性问题。而使用 volatile 就可以解决内存可见性问题,比如以下代码,当没有添加 volatile 时,它的实现如下:
private static boolean flag = false;
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
// 如果 flag 变量为 true 就终止执行
while (!flag) {
}
System.out.println("终止执行");
}
});
t1.start();
// 1s 之后将 flag 变量的值修改为 true
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("设置 flag 变量的值为 true!");
flag = true;
}
});
t2.start();
}
以上程序的执行结果如下:
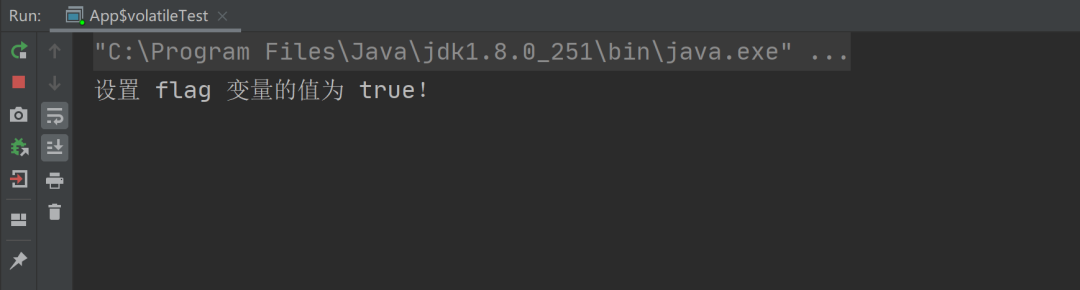
然而,以上程序执行了 N 久之后,依然没有结束执行,这说明线程 2 在修改了 flag 变量之后,线程 1 根本没有感知到变量的修改。那么接下来,我们尝试给 flag 加上 volatile,实现代码如下:
public class volatileTest {
private static volatile boolean flag = false;
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
// 如果 flag 变量为 true 就终止执行
while (!flag) {
}
System.out.println("终止执行");
}
});
t1.start();
// 1s 之后将 flag 变量的值修改为 true
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("设置 flag 变量的值为 true!");
flag = true;
}
});
t2.start();
}
}
以上程序的执行结果如下:
 从上述执行结果我们可以看出,使用 volatile 之后就可以解决程序中的内存可见性问题了。
从上述执行结果我们可以看出,使用 volatile 之后就可以解决程序中的内存可见性问题了。
2、防止指令重排序
指令重排序是指在程序执行过程中,编译器或 JVM 常常会对指令进行重新排序,已提高程序的执行性能。指令重排序的设计初衷确实很好,在单线程中也能发挥很棒的作用,然而在多线程中,使用指令重排序就可能会导致线程安全问题了。
所谓线程安全问题是指程序的执行结果,和我们的预期不相符。比如我们预期的正确结果是 0,但程序的执行结果却是 1,那么这就是线程安全问题。
而使用 volatile 可以禁止指令重排序,从而保证程序在多线程运行时能够正确执行。
二、为什么要用 volatile?
回到主题,我们在单例模式中使用 volatile,主要是使用 volatile 可以禁止指令重排序,从而保证程序的正常运行。这里可能会有读者提出疑问,不是已经使用了 synchronized 来保证线程安全吗?那为什么还要再加 volatile 呢?看下面的代码:
public class Singleton {
private Singleton() {}
// 使用 volatile 禁止指令重排序
private static volatile Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) { // ①
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton(); // ②
}
}
}
return instance;
}
}
注意观察上述代码,我标记了第 ① 处和第 ② 处的两行代码。给私有变量加 volatile 主要是为了防止第 ② 处执行时,也就是“instance = new Singleton()”执行时的指令重排序的,这行代码看似只是一个创建对象的过程,然而它的实际执行却分为以下 3 步:
- 创建内存空间。
- 在内存空间中初始化对象 Singleton。
- 将内存地址赋值给 instance 对象(执行了此步骤,instance 就不等于 null 了)。
试想一下,如果不加 volatile,那么线程 1 在执行到上述代码的第 ② 处时就可能会执行指令重排序,将原本是 1、2、3 的执行顺序,重排为 1、3、2。但是特殊情况下,线程 1 在执行完第 3 步之后,如果来了线程 2 执行到上述代码的第 ① 处,判断 instance 对象已经不为 null,但此时线程 1 还未将对象实例化完,那么线程 2 将会得到一个被实例化“一半”的对象,从而导致程序执行出错,这就是为什么要给私有变量添加 volatile 的原因了。
总结
使用 volatile 可以解决内存可见性问题和防止指令重排序,我们在单例模式中使用 volatile 主要是使用 volatile 的后一个特性(防止指令重排序),从而避免多线程执行的情况下,因为指令重排序而导致某些线程得到一个未被完全实例化的对象,从而导致程序执行出错的情况。