作为一名后端程序员,可以说天天都要跟数据库打交道,不管使用的是 MySQL, Oracle 还是 SQL Server,毫无疑问都逃不开 SQL,所以日常工作中对于 SQL 的性能优化可谓说十分重要。今天阿粉就带大家看一下,每个后端程序员都应该知道的十个提升查询性能的技巧。
1.使用 Exists 代替子查询
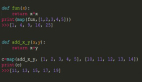
子查询在日常的工作中不可避免一定会使用到,很多时候我们的用法都是这样的:
SELECT Id, Name
FROM Employee
WHERE DeptId In (SELECT Id
FROM Department
WHERE Name like '%Management%');
相信大家平常肯定都是这样来使用的,其实还有一种更好的方法,如下所示:
SELECT Id, Name
FROM Employee
WHERE DeptId Exist (SELECT Id
FROM Department
WHERE Name like '%Management%');
这里我们使用 exist 关键字而不是 In 关键字,当然如果在数据量不大的时候,两种方式都可以,但是当数据量很大的时候,exist 的方式会比 in 的方式效率高很多。因为 Exist 函数根据查询结果返回一个布尔值,速度会快很多。
2.适当的使用 JOIN 来代替子查询
除了上面的exist 之外在有些场景我们可以使用 JOIN 来替换子查询,毕竟子查询的效果是很差的,如下所示:
SELECT Id, Name
FROM Employee
WHERE DeptId in (SELECT Id
FROM Department
WHERE Name like '%Management%');
使用 JOIN 的方式如下:
SELECT Emp.Id, Emp.Name,Dept.DeptName
FROM Employee Emp
RIGHT JOIN Department Dept on Emp.DeptId = Dept.Id WHERE Dept.DeptName like '%Management%';
3.使用 Where 替代不必要的Having
对于 where 的使用相信大家都很擅长,但是对于 Having 的使用可能平时用的不多,阿粉这里只能说:用得不多,挺好的!对于 Having 我们是能不用就不用不到万不得已的时候不要用,说真的阿粉工作这么多年,真没有使用 Having 的场景。我们先看下面的示例:
Having 的用法
SELECT Emp.Id, Emp.Name,Dept.DeptName,Emp.Salary
FROM Employee Emp
RIGHT JOIN Department Dept on Emp.DeptId = Dept.Id
GROUP BY dept.DeptName
HAVING Emp.Salary >= 20000;
Where 的用法
SELECT Emp.Id, Emp.Name,Dept.DeptName,Emp.Salary
FROM Employee Emp
RIGHT JOIN Department Dept on Emp.DeptId = Dept.Id
WHERE Emp.Salary >= 20000;
为什么说 Having 的性能没有 Where 高呢?那是因为 Where 是一种精确的匹配,但是 Having 是需要配合 Group By 来配合使用,只要涉及到 Group By 自然就效率高不起来了。
4.使用精确的字段类型
有些小伙伴为了系统的可扩展性或者压根就不知道该把数据库字段的类型设置什么,所以就全部使用 char 或者 varchar,总觉得这样更灵活,但是往往这个时候是对系统的最大隐患。
在使用时间类型的字段的时候,就需要设置成 DateTime,不能用 varchar;在使用标识是否删除的时候就应该使用 tinyint,能用 varchar 的就不要用 char;对于大字段 text 需要独立出来,这样在查询的时候就不会影响性能;对于能设置成唯一键的就需要设置成唯一键,因为你永远无法避免程序会出现脏数据,要在数据层保证一致性。
5.使用批处理代替循环
在插入数据的时候的,我们可以使用 values 来批量进行插入,而不是通过循环来进行单条数据的查询,如下所示:
//不可取
For(Int i = 0;i <= 5; i++)
{
INSER INTO Table1(Id,Value) Values( i , 'Value' + i );
}
//推荐
INSERT INTO Table1(Id, Value)
Values(1,Value1),(2,Value2),(2,Value3),(4,Value4),(5,Value5);
不过要注意 values 后面的数量也是有限制的,所以两者可以结合使用,具体的可以根据表字段的多少来决定分多少批来执行。另外这里有一个注意的点,很多系统都会底层做操作日志,而且很多时候可能是 SQL 级别的,那这个时候就需要注意,记录操作日志的表的字段是有长度限制的,这里整个 SQL 的长度是不能超过日志字段的长度的。
6.使用 UNION ALL 替代 UNION
在使用联合查询的时候,很多时候我们会使用到 UNION ALL 或者 UNION 来联合多个表,进行汇总。那么 UNION ALL 和 UNION 的区别是什么呢?这两个的区别是 UNION ALL 会返回联合后的所有行记录,而 UNION 是会进行去重后返回。
比如说我们有两张表 teacher 和 student,里面的数据分别是下面:


这里这两张表当中,存在相同的一条数据,就是(4, 马六)这一条数据,我们可以看看使用 UNION ALL 和 UNION 的效果。


可以看到第二次的查询结果中已经少了一行,说明我们上面说的 UNION 会去重的逻辑是存在的,而且去重是全字段都相同的时候才会被去重。
7.用精确的字段代替 *
另一个比较影响性能的点是使用 *,很多小伙伴为了省事,在编写查询语句的时候,会使用 * 来代替所有的字段,其实并不是说这种写法有什么问题,只是这种写法有点不可控,使用 * 表示要查询所有字段,当我们的表是一个很简单的表,而且里面的字段都是一些小字段的时候,使用 * 完全是可以的。
但是如果是对于一些大表特别是有 text 这种大字段的表,或者是一些敏感数据的表,我们还使用 * 号去查询数据的话,就会有很大的问题了,一方面是有安全隐患,一方面还是增加磁盘,内存和网络的传输,完全得不偿失。
8.给必要的字段增加索引
索引作为数据库里面一个很重要的内容,相比大家都不陌生,给必要的字段加上索引也是很有必要的,除了主键索引,我们还可以添加聚簇索引和唯一索引。
总结
后端程序员除了跟服务器打交道之外最多的就是跟数据库打交道了,如何在数据库层面提效也是一个长久的话题,这也是为什么数据库能得到发展的原因,从关系型数据库到 NoSQL 数据库,从 MySQL 到 ClickHouse,数据库行业也在长久的发展。