译者 | 李睿
审校 | 孙淑娟
网站抓取(Scraping)是一门安全性比较薄弱的学科。人们经常使用服务器来解决,而调试和解决这些问题非常困难,至少现在是这样。

抓取采用现代浏览器构建的网站比十年前更具挑战性。jsoup是一个方便的API,它通过DOM遍历、CSS选择器、类似JQuery的方法等使抓取网站变得简单。但这并非没有挑战,因为每个抓取的API都可能是一颗定时炸弹。
现实世界的HTML是脆弱的。因为它不是一个文档化的API,所以会在没有通知的情况下进行更改。当Java程序在抓取方面失败时,可能就面临更多的麻烦。在某些情况下,这是一个简单的问题,可以在本地复制并部署。但在本地测试用例中,DOM树中的一些细微变化可能更难观察到。在这些情况下,需要在推动更新之前了解解析树中的问题。否则,开发的软件产品可能会损坏。
什么是jsoup?JavaHTML解析器
在深入了解调试jsoup的具体细节之前,先回答上面的问题,并讨论jsoup背后的核心概念。
jsoup网站将其定义为:jsoup是一个用于处理真实世界HTML的Java库。它使用HTML5 DOM方法和CSS选择器提供了一个非常方便的API,用于获取URL以及提取和操作数据。
jsoup实现了WHATWG HTML5规范,并将HTML解析为与现代浏览器相同的DOM。
考虑到这一点,可以直接从同一个网站上获取一个简单的示例:
Java
1 Document doc = Jsoup.connect("https://en.wikipedia.org/").get();
2 log(doc.title());
3 Elements newsHeadlines = doc.select("#mp-itn b a");
4 for (Element headline : newsHeadlines) {
5 log("%s\n\t%s",
6 headline.attr("title"), headline.absUrl("href"));
7 }- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
这段代码片段摘自维基百科的标题。在上面的代码中,可以看到几个有趣的特性:
- 与URL的连接实际上是无缝的——只需将字符串URL传递给connect方法。
- 某些子元素有特殊情况。例如。Title被公开为一个简单的方法,它返回一个字符串而不从DOM树中选择。
- 可以使用非常复杂的选择器语法来选择条目。
简单的jsoup测试
为了演示调试,创建了一个简单的演示。
XML
1 <dependency>
2 <groupId>org.jsoup</groupId>
3 <artifactId>jsoup</artifactId>
4 <version>1.14.3</version>
5 </dependency>- 1.
- 2.
- 3.
- 4.
- 5.
可以使用以下Maven依赖项将jsoup安装到任何Java程序中。Maven将无缝下载jsoupjar:
Java
1 public Set<String> listLinks(String url, boolean includeMedia) throws IOException {
2 Document doc = Jsoup.connect(url).get();
3 Elements links = doc.select("a[href]");
4 Elements imports = doc.select("link[href]");
5
6 Set<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
7 if(includeMedia) {
8 Elements media = doc.select("[src]");
9 for (Element src : media) {
10 result.add(src.absUrl("src"));
11 //result.add(src.attr("abs:src"));
12 }
13 }
14
15 for (Element link : imports) {
16 result.add(link.absUrl("abs:href"));
17 }
18
19 for (Element link : links) {
20 result.add(link.absUrl("abs:href"));
21 }
22
23 return result;
24 }- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
本段代码可以获取输入的字符串URL。也可以使用输入流,但这在解析相对URL时会稍微复杂一些(无论如何都需要一个基本URL)。然后搜索具有src属性的链接和对象。最后代码将它们全部添加到一个集合中,以保持条目的排序和唯一性。
我们使用以下代码将其公开为Web服务:
1
2 public class ParseLinksWS {
3 private final ParseLinks parseLinks;
4
5 public ParseLinksWS(ParseLinks parseLinks) {
6 this.parseLinks = parseLinks;
7 }
8
9 ("/parseLinks")
10 public Set<String> listLinks( String url, (required = false) Boolean includeMedia) throws IOException {
11 return parseLinks.listLinks(url, includeMedia == null ? true : includeMedia);
12 }
13 }- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
一旦运行应用程序,就可以通过一个简单的curl命令使用它:
Java
1 curl -H "Content-Type: application/json" "http://localhost:8080/parseLinks?url=https%3A%2F%2Flightrun.com"- 1.
这将打印出Lightrun主页中引用的URL列表。
调试内容失败
当元素对象更改时,会出现典型的字符串抓取问题。例如,维基百科可以更改其页面的结构,而上面的选择方法可能会失败。这通常是一个微妙的失败,是在处理嵌套节点元素和文档间依赖关系时。例如Java对象层次结构中缺少DOM元素,这可能会触发选择方法的失败。大多数开发人员通过记录大量数据来解决这个问题。产生这个问题的原因有三个:
- 日志数据量大——它们既难以阅读,又非常昂贵。
- 隐私/GDPR违规——被抓取的网站可能包含特定用户的私人信息。
- 在最初实施抓取之后,抓取的站点可能会更改为包含私人信息。记录这些私人信息可能会违反各种隐私法规。
如果没有足够的日志并且无法在本地重现问题,就会陷入到添加日志、构建、测试、部署、重现这样的重复循环中。
Lightrun提供了一种更好的方法。只需直接在生产中跟踪特定故障、验证问题,并创建适用于一个部署的修复程序。
注:本文假设安装了Lightrun并了解其背后的基本概念。如果没有,可以查看文档。
在浏览器DOM中找到自己的方式
假设不知道从何开始,那么jsoup API是一个很好的起点。它可以带回用户代码。很酷的是,无论代码如何都会有效。通过深入研究API调用,可以找到快照的正确行/文件。
在此处按ctrl键(在Mac上使用Meta-click)选择方法调用:
Java
1 Elements links = doc.select("a[href]");- 1.
它带到了Element类。在其中,按ctrl键单击选择器“select”方法,可以放置一个条件快照来查看每个执行“a[href]”查询的情况:
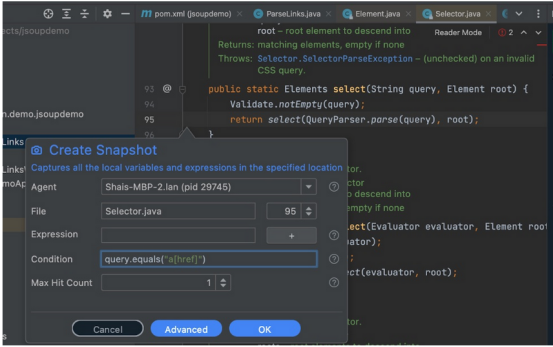
这可以显示执行该查询的方法/行:
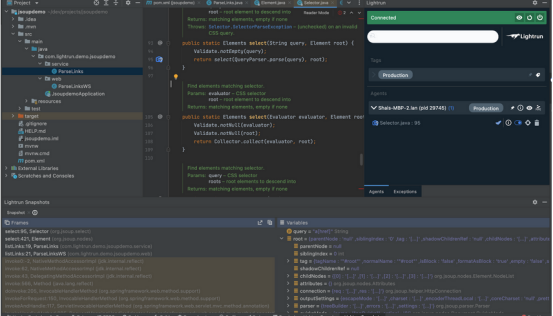
这对缩小文档对象层次结构中的一般问题区域有很大帮助。
有时采用快照可能还不够,可能需要使用日志。日志记录的优点是可以生成大量信息,但仅针对特定情况和按需生成。
日志的价值在于,它们能够以非常类似于单步执行代码的方式跟踪问题。放置快照的位置对于日志来说是有问题的。我们知道发送的查询,但还没有返回的值。可以用日志轻松解决这个问题。首先,添加一个包含以下文本的日志:
"Executing query {query}"
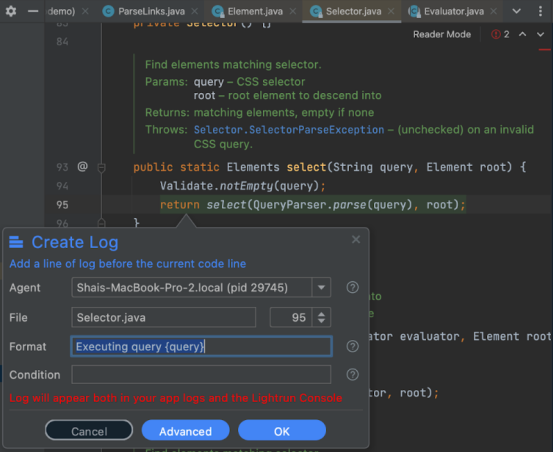
然后,要找出返回了多少条目,只需转到调用者(我们知道这要归功于快照中的堆栈)并在那里添加以下日志:
Links query returned {links.size()}- 1.
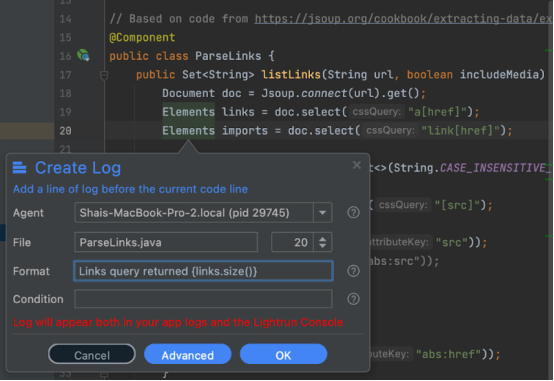
这会产生以下日志,让我们看到有147个a[href]链接。这样做的好处是额外的日志与场景中预先存在的日志交错:
Feb 02, 2022 11:25:27 AM org.jsoup.select.Selector select
INFO: LOGPOINT: Executing query a[href]
Feb 02, 2022 11:25:27 AM com.lightrun.demo.jsoupdemo.service.ParseLinks listLinks
INFO: LOGPOINT: Links query returned 147
Feb 02, 2022 11:25:27 AM org.jsoup.select.Selector select
INFO: LOGPOINT: Executing query link[href]
Feb 02, 2022 11:25:27 AM org.jsoup.select.Selector select
INFO: LOGPOINT: Executing query [src]- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
避免安全和GDPR问题
GDPR和安全问题可能是将用户信息泄漏到日志中的问题。这可能是一个主要问题,Lightrun可以帮助显著降低这种风险。
Lightrun提供了两种可能的解决方案,可以在适用时串联使用。
(1)日志管道
GDPR的最大问题是日志摄取。如果记录私人用户数据,然后将其发送到云端,它会在那里保存很长时间,并且事后很难找到,也很难修复。
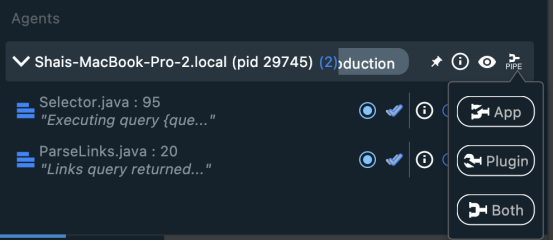
Lightrun提供了将Lightrun的所有注入日志直接通过管道传输到IDE的能力。这样做的好处是可以消除可能使用日志的其他开发人员的干扰。它还可以跳过摄取(可选)。
如果仅将日志发送到插件,需要将管道模式选择为“插件”。
(2)PII减少/阻止列表
个人身份信息(PII)是GDPR法规的核心,也是一个主要的安全风险。而企业中的恶意开发人员可能希望使用Lightrun来窃取用户信息。阻止列表阻止开发人员在特定文件中放置操作。
验证个人身份信息(PII) 可以减少从日志中隐藏匹配特定模式的信息(例如信用卡格式等)。这可以由管理员角色在Lightrun Web界面中定义。
结语
对于Java内容抓取,jsoup显然是领导者。使用jsoup进行开发远远超过字符串操作,甚至在处理连接方面。除了获取文档对象外,它还处理DOM元素和脚本所需的复杂方面。
抓取是一项有风险的业务。当网站发生轻微变化时,它可能会在眨眼间崩溃。更糟糕的是,它可能会以奇怪的方式影响某些用户,而这些方式不可能在本地复制。
而有了Lightrun,可以直接在生产环境中调试此类故障,并快速发布工作版本。
原文标题:Debugging jsoup Java Code in Production Using Lightrun,作者:Shai Almog