












最近一段时间,人工智能技术在大模型方面有了突破性进展,昨天谷歌提出的 Imagen 再次引发了人们对于 AI 能力的讨论。通过大量数据的预训练学习,算法已经有了前所未有的逼真图像构建和语言理解能力。
在很多人看来,我们距离通用人工智能已经近了,不过知名学者、纽约大学教授 Gary Marcus 不是这样想的。
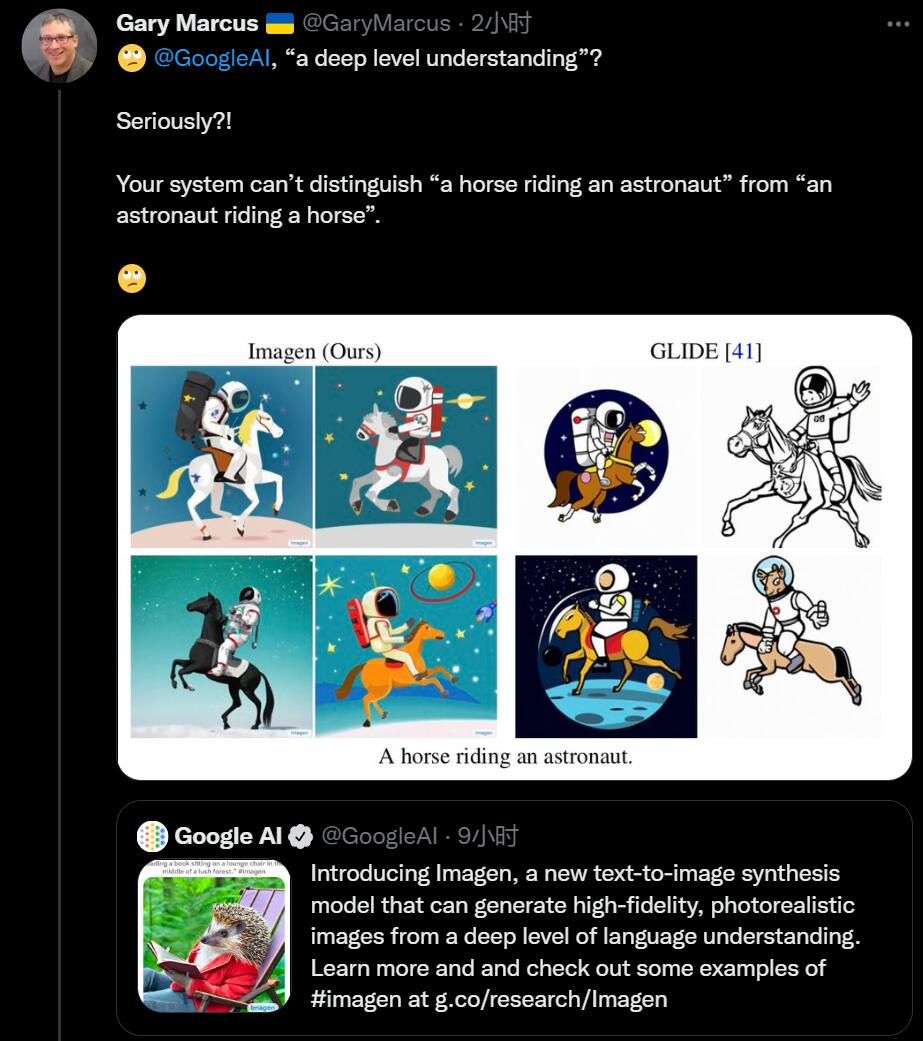
近日,他的文章《The New Science of Alt Intelligence》对 DeepMind 研究主任 Nando de Freitas 「规模致胜」的观点进行了反驳,让我们看看他是怎么说的。
以下是Gary Marcus的原文:
几十年来,AI 领域一直存在一个假设,即人工智能应该从自然智能中汲取灵感。John McCarthy 撰写了关于 AI 为什么需要常识的开创性论文——《Programs with Common Sense》;Marvin Minsky 写了著名的《Society of Mind》一书,试图从人类的思维中寻找灵感;因在行为经济学方面的贡献而获得诺贝尔经济学奖的 Herb Simon 写了著名的《Models of Thought》,旨在解释「新开发的计算机语言如何表达心理过程理论,以便计算机能够模拟预测的人类行为。」
据我所知,目前很大一部分 AI 研究人员(至少是那些比较有影响力的研究人员)根本不在乎这些。相反,他们将更多精力放在了一个被我称为「Alt Intelligence」(替代智能)的方向上(感谢 Naveen Rao 对这一术语的贡献)。
Alt Intelligence 不是指构造出能够以人类智能的方式解决问题的机器,而是利用从人类行为中获取的大量数据来代替智能。目前,Alt Intelligence 的主要工作是规模化。这种系统的拥护者认为,系统越大,我们就越接近真正的智能,甚至意识。
研究 Alt Intelligence 本身并没有什么新鲜的,但与之相关的傲慢却非常新鲜。
有一段时间,我看到了一些迹象,当前的人工智能超级明星,乃至整个人工智能领域的大部分人,对人类认知不屑一顾,忽视甚至嘲笑语言学、认知心理学、人类学和哲学等领域的学者。
但今天早上,我发现了一条关于 Alt Intelligence 的新推文。推文作者、DeepMind 研究主任 Nando de Freitas 宣称,AI「现在完全取决于规模」。事实上,在他看来(也许是故意用激烈的言辞来挑衅),AI 领域更难的挑战已经解决了。「游戏结束了!」他说。
从本质上来说,追寻 Alt Intelligence 并没有错。
Alt Intelligence 代表了一种关于如何构建智能系统的直觉(或者说一系列直觉)。由于还没有人知道如何构建可以媲美人类智能的灵活性和智慧的系统,因此对于人们来说,追求关于如何实现这一点的多种不同假设是一场公平的游戏。Nando de Freitas 尽可能直白地为这一假设辩护,我把它称为 Scaling-Uber-Alles(规模大于一切)。
当然,这个名字并不完全公平。De Freitas 非常清楚,你不能指望只把模型做大就能取得成功。人们最近做了大量的扩展,并取得了一些巨大的成功,但也遇到了一些障碍。在深入探讨 De Freitas 如何面对现状之前,让我们先来看看现状是怎样的。
现状
像 DALL-E 2、GPT-3、Flamingo 和 Gato 这样的系统似乎令人兴奋,但仔细研究过这些模型的人不会把它们与人类智能混为一谈。
例如,DALL-E 2 可以根据文字描述创作出逼真的艺术作品,如「一个骑着马的宇航员」:

但它也很容易犯令人惊讶的错误,比如当文字描述是「一个红方块放在一个蓝方块上」时,DALL-E 的生成结果如左图所示,右图是之前的模型所生成的结果。显然,DALL-E 的生成结果还不如之前的模型。

当我和 Ernest Davis、Scott Aaronson 深入研究这个问题时,我们发现了许多类似的例子:
此外,表面上看起来非常惊艳的 Flamingo 也有自己的 bug,就像 DeepMind 高级研究科学家 Murray Shanahan 在一篇推文中所指出的那样,Flamingo 的第一作者 Jean-Baptiste Alayrac 后来也补充了一些例子。例如,Shanahan 向 Flamingo 展示了这样一张图片:
并围绕这张图片展开了以下漏洞百出的对话:

看起来是「无中生有」了。
前段时间,DeepMind 还发布了多模态、多任务、多具身的「通才」智能体 Gato,但当你看那些小字的时候,你仍然能够发现不可靠的地方。

当然,深度学习的捍卫者会指出,人类也会犯错。
但任何一个诚实的人都会意识到,这些错误表明,有些东西目前是存在缺陷的。毫不夸张地说,如果我的孩子经常犯这样的错误,我会放下手头的一切工作,立即带他们去看神经科医生。
所以,让我们诚实一点:规模化还没有起效,但它是有可能的,或者说 de Freitas 的理论——时代精神的清晰表达——是这样的。
Scaling-Uber-Alles
那么,de Freitas 是如何将现实与抱负调和到一起的呢?事实上,现在已经有数十亿美元被投入到了 Transformer 和其他许多相关领域,训练数据集已经从兆字节扩展到千兆字节,参数量从数百万扩展到数万亿。然而,自 1988 年以来,在许多著作中被详细记录的令人费解的错误仍然存在。
对于一些人(比如我自己)来说,这些问题的存在可能意味着我们需要进行根本性的反思,比如 Davis 和我在《Rebooting AI》一书中所指出的那些。但对于 de Freitas 来说,事情却不是这样(其他很多人可能也和他持一样的想法,我并不是要把他单独拎出来讲,我只是觉得他的言论比较有代表性)。
在推文中,他详细阐述了他对调和现实与当前问题的看法,「(我们需要)让模型变得更大、更安全、计算效率更高、采样更快、存储更智能、模式更多,此外还需要研究数据创新、在线 / 离线等等。」重点是,没有一个词来自认知心理学、语言学或哲学(也许 smarter memory 勉强能算)。
在后续的帖子中,de Freitas 还说到:
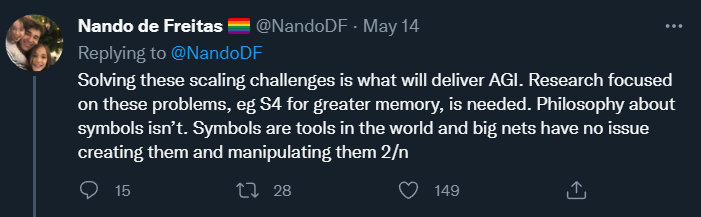
这再次印证了他「规模化大于一切」的声明,并表明了一个目标:其野心不仅仅是更好的 AI,而是 AGI。
AGI 即通用人工智能,它至少与人类智能一样好、一样足智多谋且适用范围广泛。当前我们实现的狭义的人工智能实际上是替代智能(alt intelligence),其标志性的成功是国际象棋(深蓝与人类智能毫无关系)和围棋(AlphaGo 与人类智能关系也不大)等游戏。De Freitas 有着更为远大的目标,值得称赞的是,他对这些目标非常坦率。那么,他要怎么来实现自己的目标呢?这里要重申一下,de Freitas 重点关注的是用于容纳更大数据集的技术工具。其他的想法,例如来自哲学或认知科学的想法,可能很重要,但却被排除了。
他说,「关于符号的哲学并无必要」。也许这是对我长期以来将符号操纵整合到认知科学和人工智能中的运动的反驳。这个想法最近又出现在了 Nautilus 杂志上,尽管阐述并不充分。在此我简要回应:他所说的「[neural] nets have no issue creating [symbols] and manipulating them」既忽略了历史,也忽略了现实。他忽略的历史是:许多神经网络爱好者几十年来一直反对符号;他忽略的现实是:像前面提到的「蓝色立方体上的红色立方体」这类符号性描述仍然能够难住 2022 年的 SOTA 模型。
在推文结尾,De Freitas 表达了他对 Rich Sutton 著名文章《苦涩的教训》的赞同:
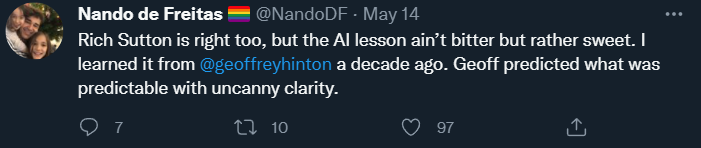
Sutton 的论点是,唯一导致人工智能进步的是更多的数据、更有效的计算。在我看来,Sutton 只对了一半,他对过去的描述几乎是正确的,但他对未来的归纳预测却无法令人信服。
到目前为止,在大多数领域(当然不是所有领域),大数据已经(暂时)战胜了精心设计的知识工程。
但世界上几乎所有的软件,从网络浏览器到电子表格再到文字处理器,仍然依赖于知识工程,而 Sutton 忽略了这一点。举个例子,Sumit Gulwani 出色的 Flash Fill 功能是一种非常有用的一次性学习系统,它根本不是建立在大数据的前提下,而是建立在经典的编程技术之上。
我认为任何纯粹的深度学习 / 大数据系统都无法与之匹敌。
事实上,像 Steve Pinker、Judea Pearl、Jerry Fodor 和我这样的认知科学家几十年来一直指出的人工智能的关键问题实际上还没有得到解决。是的,机器可以很好地玩游戏,深度学习在语音识别等领域做出了巨大贡献。但目前没有任何人工智能可以具备足够的理解力认识任何文本,并建立一个能正常说话、完成任务的模型,也不能像《星际迷航》电影里的计算机一样可以进行推理并产生有凝聚力的响应。
我们仍处在人工智能的早期阶段。
使用特定策略在一些问题上取得成功并不能保证我们能以类似的方式解决所有问题。如果没有意识到这样,那简直是愚蠢的,特别是当一些失败模式(不可靠性、奇怪的错误、组合性失败和不理解)自 Fodor 和 Pinker 在 1988 年指出它们之后仍没有改变时。结语
很高兴能看到 Scaling-Über-Alles 尚未完全达成共识,即使在 DeepMind 也是如此:
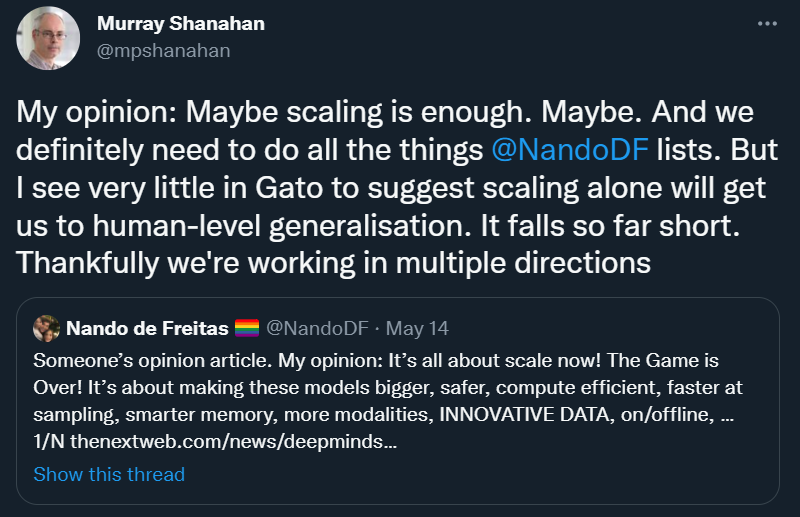
我完全同意 Murray Shanahan 的看法:「I see very little in Gato to suggest scaling alone will get us to human-level generalisation」。
让我们鼓励一个思想足够开放的领域,人们可以在很多方向上开展自己的工作,而不会过早地抛弃碰巧尚未完全发展的想法。毕竟,通向(通用)人工智能的最佳途径可能不是 Alt Intelligence 这条路。
正如前面所述,我很乐意把 Gato 视为「替代智能」——一种建立智能替代方法的有趣探索,但我们需要客观看待它:它不会像大脑那样工作,它不会像孩子那样学习,它不懂语言,不符合人类价值观,不能被信任用来完成关键任务。
它可能比我们目前拥有的任何其他东西都好,但仍然不能真正起作用,即使在对它进行了巨大的投资之后,我们也该暂停一下。
它应该把我们带回人工智能初创的时代。人工智能当然不应该是人类智能的盲从复制品,毕竟它有自己的缺陷,背负着糟糕的记忆和认知偏见。但它应该从人类和动物的认知中寻找线索。莱特兄弟没有模仿鸟类,但他们从鸟类的飞行控制中学到了一些知识。知道什么可以借鉴,什么不可以借鉴,我们可能就成功了一大半。
我认为底线是,人工智能曾经重视但现在不再追求的东西:如果我们要构建 AGI,我们将需要向人类学习一些东西——他们是如何推理和理解物理世界的,以及他们是如何表示和获得语言及复杂概念的。
如果否定这种想法,那就太狂妄了。



















