












1 前言
在发布DALL·E的15个月后,OpenAI在今年春天带了续作DALL·E 2,以其更加惊艳的效果和丰富的可玩性迅速占领了各大AI社区的头条。近年来,随着生成对抗网络(GAN)、变分自编码器(VAE)、扩散模型(Diffusion models)的出现,深度学习已向世人展现其强大的图像生成能力;加上GPT-3、BERT等NLP模型的成功,人类正逐步打破文本和图像的信息界限。
在DALL·E 2中,只需输入简单的文本(prompt),它就可以生成多张1024*1024的高清图像。这些图像甚至可以将不合常理的语义表示,以超现实主义的形式创造出天马行空的视觉效果,例如图1中“写实风格的骑马的宇航员(An astronaut riding a horse in a photorealistic style)”。
 图1. DALL·E 2生成示例
图1. DALL·E 2生成示例
本文将深入解读DALL·E等新范式如何通过文本创造出众多惊人的图像,文中涵盖大量背景知识和基础技术的介绍,同样适合初涉图像生成领域的读者。
2 图像生成
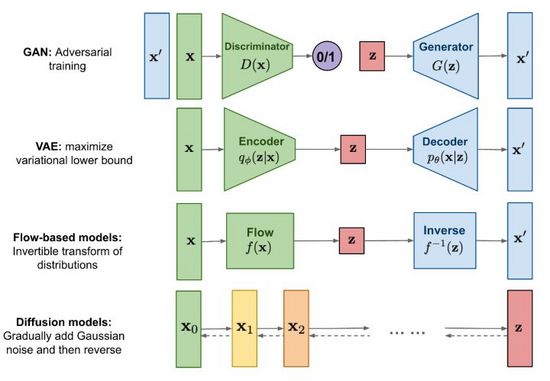
图2. 主流图像生成方法
自2014年生成对抗网络(GAN)诞生以来,图像生成研究成为了深度学习乃至整个人工智能领域的重要前沿课题,现阶段技术发展之强已达到以假乱真的程度。除了为人熟知的生成对抗网络(GAN),主流方法还包括变分自编码器(VAE)和基于流的生成模型(Flow-based models),以及近期颇受关注的扩散模型(Diffusion models)。借助图2我们探寻一下各个方法的特点和区别。
2.1 生成对抗网络(GAN)
GAN的全称是 G enerative A dversarial N etworks,从名称不难读出“对抗(Adversarial)”是其成功之精髓。对抗的思想受博弈论启发,在训练生成器(Generator)的同时,训练一个判别器(Discriminator)来判断输入是真实图像还是生成图像,两者在一个极小极大游戏中相互博弈不断变强,如式(1)。当从随机噪声生成足以“骗”过的图像时,我们认为较好地拟合出了真实图像的数据分布,通过采样可以生成大量逼真的图像。
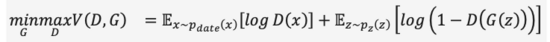
GAN是生成式模型中应用最广泛的技术,在图像、视频、语音和NLP等众多数据合成场景大放异彩。除了直接从随机噪声生成内容外,我们还可以将条件(例如分类标签)作为输入加入生成器和判别器,使得生成结果符合条件输入的属性,让生成内容得以控制。虽然GAN效果出众,但由于博弈机制的存在,其训练稳定性差且容易出现模式崩溃(Mode collapse),如何让模型平稳地达到博弈均衡点,也是GAN的热点研究话题。
2.2 变分自编码器(VAE)
变分自编码器(Variational Autoencoder)是自编码器的一种变体,传统的自编码器旨在以无监督的方式训练一个神经网络,完成将原始输入压缩成中间表示和将恢复成两个过程,前者通过编码器(Encoder)将原始高维输入转换为低维隐层编码,后者通过解码器(Decoder)从编码中重建数据。不难看出,自编码器的目标是学习一个恒等函数,我们可以使用交叉熵(Cross-entropy)或者均方差(Mean Square Error)构建重建损失量化输入和输出的差异。如图3所示,在上述过程中我们获得了低纬度的隐层编码,它捕捉了原始数据的潜在属性,可以用于数据压缩和特征表示。
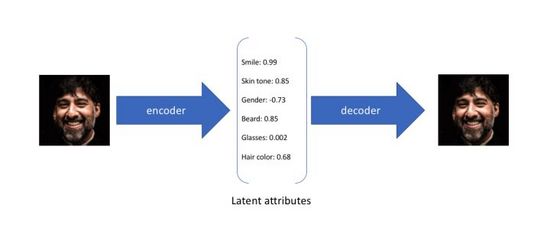
图3. 自编码器的潜在属性编码
由于自编码器仅关注隐层编码的重建能力,其隐层空间分布往往是无规律和不均匀的,在连续的隐层空间随机采样或者插值得到一组编码通常会产生无意义和不可解释的生成结果。为了构建一个有规律的隐层空间,使得我们可以在不同潜在属性上随机地采样和平滑地插值,最后通过解码器生成有意义的图像,研究者们在2014年提出了变分自编码器。
变分自编码器不再将输入映射成隐层空间中的一个固定编码,而是转换成对隐层空间的概率分布估计,为了方便表示我们假设先验分布是一个标准高斯分布。同样的,我们训练一个概率解码器建模,实现从隐层空间分布到真实数据分布的映射。当给定一个输入,我们通过后验分布估计出关于分布的参数(多元高斯模型的均值和协方差),并在此分布上采样,可使用重参数化技巧使采样可导(为随机变量),最后通过概率解码器输出关于的分布,如图4所示。为了使生成图像尽量真实,我们需要求解后验分布,目标是最大化真实图像的对数似然。
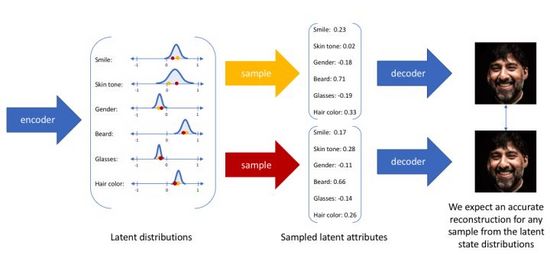
图4. 变分自编码器的采样生成过程
遗憾的是,真实的后验分布根据贝叶斯模型包含对在连续空间上的积分,是不可直接求解的。为了解决上述问题,变分自编码器使用了变分推理的方法,引入一个可学习的概率编码器去近似真实的后验分布,使用KL散度度量两个分布的差异,将这个问题从求解真实的后验分布转化为如何缩小两个分布之间的距离。
我们省略中间推导过程,将上式展开得到式(2),
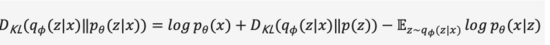
由于KL散度非负,我们可以将我们的最大化目标转写成式(3),
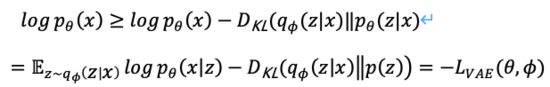
综上,我们将关于概率编码器和概率解码器的定义为模型的损失函数,其负数形式称为的证据下界(Evidence Lower Bound),最大化证据下界等效于最大化目标。上述变分过程是VAE及各种变体的核心思想,通过变分推理将问题转化为最大化生成真实数据的证据下界。
2.3 基于流的生成模型(Flow-based models)
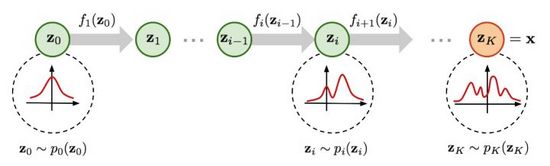
图5. 基于流的生成过程
如图5所示,假设原始数据分布可以通过一系列可逆的转化函数从已知分布获得,即。通过雅各布矩阵行列式和变量变化规则,我们可以直接估计真实数据的概率密度函数(式(4)),最大化可计算的对数似然。
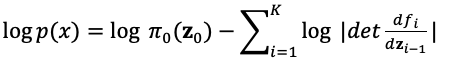
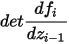 是转换函数的雅各布行列式,因此要求可逆之外还要求容易计算出其雅各布行列式。基于流的生成模型如Glow采用1x1可逆卷积进行精确的密度估计,在人脸生成上取得不错的效果。
是转换函数的雅各布行列式,因此要求可逆之外还要求容易计算出其雅各布行列式。基于流的生成模型如Glow采用1x1可逆卷积进行精确的密度估计,在人脸生成上取得不错的效果。
2.4 扩散模型(Diffusion models)

图6. 扩散模型的扩散和逆向过程
扩散模型定义了正向和逆向两个过程,正向过程或称扩散过程是从真实数据分布采样,逐步向样本添加高斯噪声,生成噪声样本序列,加噪过程可用方差参数控制,当时,可近似等同于一个高斯分布。其扩散过程是预设的可控过程,加噪过程可用条件分布表示为式(5),
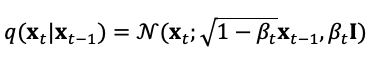
从扩散过程的定义可以看出,我们可以在任意步长上使用上式采样,
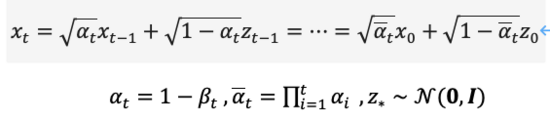
同样我们也可以把扩散过程逆向,从高斯噪声中采样,学习一个模型来估计真实的条件概率分布,因此逆向过程可定义为式(7),
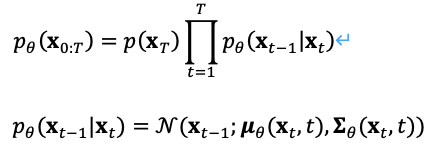
扩散模型的优化目标有多种选择,例如在训练过程中由于可以从正向过程直接计算,于是我们可以从预测的分布中采样,采样过程可以加入图像分类和文本标签作为条件输入,用最小均方差优化重建损失,这个过程等效于自编码器。
在去噪扩散概率模型DDPM中,作者通过重参数化技术构建了简化版的噪声预测模型损失(式(8)),在步长时输入加噪数据 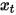 训练模型去预测噪声
训练模型去预测噪声 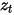 ,推理过程中使用
,推理过程中使用
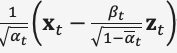
预测去噪数据 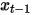 的高斯分布均值,实现人脸图像去噪。
的高斯分布均值,实现人脸图像去噪。
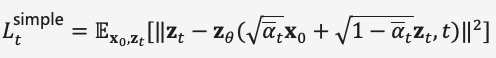
3 多模态表示学习
3.1 NLP on Transformer
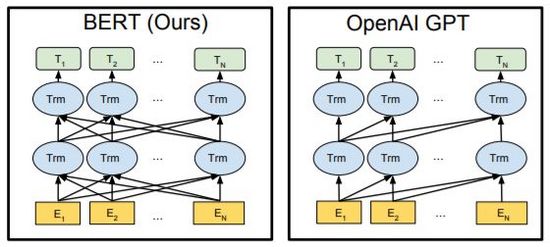
图7. BERT与GPT
BERT与GPT是近年来NLP领域中非常强大的预训练语言模型,在文章生成,代码生成,机器翻译,Q&A等下游任务中取得巨大突破。两者均使用了Transformer作为算法的主要框架,实现细节上略有不同(图7)。
BERT本质上是一个双向编码器,通过Mask Language Model(MLM)和Next Sentence Prediction(NSP)两个任务,使用自监督的方式学习文本的特征表示,可代替Word2Vec迁移至其他的学习任务中。GPT本质是自回归解码器,通过使用海量数据和不断堆叠模型,最大化语言模型预测下个文本的似然值。重要的是,训练过程中GPT的后序文本被mask使其在前序文本训练预测时不可见,而在BERT中所有文本均相互可见并参与self-attention计算,BERT通过随机mask或替换输入,提升模型鲁棒性和表达能力。
3.2 ViT(Vision Transformer)
Transformer在NLP领域取得的巨大成功,引发了研究者们对于其图像特征表达能力的思考。与NLP不同,图像信息是数量庞大和冗余的,直接使用Transformer建模会因Tokens数量过大导致模型无法学习。直到2020年研究者们提出了ViT,通过Patch和线性投影的方法,降低了图像数据的维度,使用Transformer Encoder作为图像编码器输出分类预测结果,取得了可观的效果。
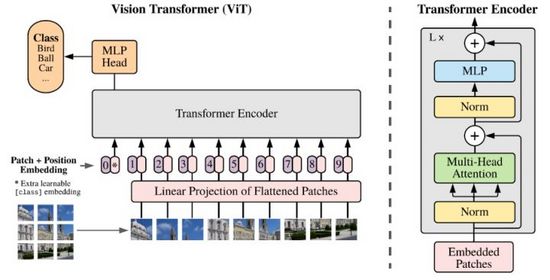
图8. ViT
现如今Transformer已成为图像处理领域新的研究对象,以其强大的潜力不断挑战CNN的地位。
3.3 CLIP
CLIP(Contrastive Language-Image Pretraining)是OpenAI提出的连接图像和文本特征表示的对比学习方法。如图9所示,CLIP成功将文本-图像对通过Transformer编码生成Tokens对,使用点积运算衡量相似度,由此对于每个文本我们获得关于所有图像的one-hot分类概率,反之每个图像也能获得关于所有文本的分类概率。在训练过程中,我们对图9(1)概率矩阵每行每列计算交叉熵损失进行优化。
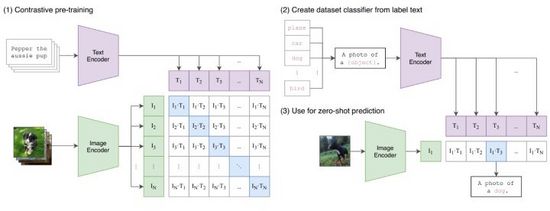
图9. CLIP
CLIP将文本和图像的特征表示映射到同一空间,虽然没有实现跨模态的信息传递,但作为特征压缩、相似性度量和跨模态表示学习的方法,是十分有效的。直观的,我们把图像Tokens在标签范围生成的所有文本提示中与之特征最相似的输出,即完成了一次图像分类(图9(2)),特别当图像和标签的数据分布未曾在训练集出现过,CLIP仍然有零样本(zero-shot)学习的能力。
4 跨模态图像生成
经过前面两章的介绍,我们系统性地回顾了图像生成和多模态表示学习相关基础技术,本章将介绍三个最新的跨模态图像生成方法,解读它们如何使用这些基础技术进行建模。
4.1 DALL·E
DALL·E由OpenAI在2021年初提出,旨在训练一个输入文本到输出图像的自回归解码器。由CLIP的成功经验可知,文本特征和图像特征可以编码在同一特征空间中,因此我们可以使用Transformer将文本和图像特征自回归建模为单个数据流(“autoregressively models the text and image tokens as a single stream of data”)。
DALL·E的训练过程分成两个阶段,一是训练一个变分自编码器用于图像编解码,二是训练一个文本和图像的自回归解码器用于预测生成图像的Tokens,如图10所示。
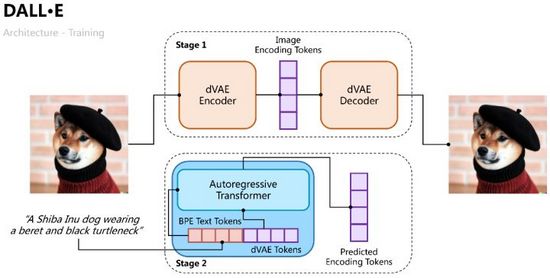
图10. DALL·E的训练过程
推理过程则比较直观,将文本Tokens用自回归Transformer逐步解码出图像Tokens,解码过程中我们可以通过分类概率采样多组样本,再将多组样本Tokens输入变分自编码中解码出多张生成图像,并通过CLIP相似性计算排序择优,如图11所示。
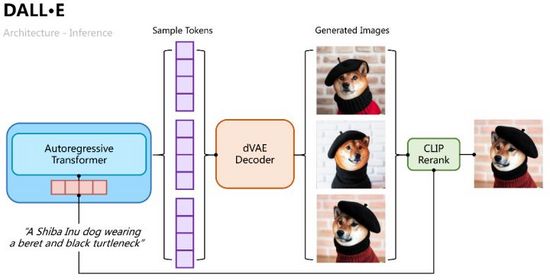
图11. DALL·E的推理过程
和VAE一样我们用概率编码器和概率解码器,分别建模隐层特征的后验概率分布和生成图像的似然概率分布,使用建模由Transformer预测的文本和图像的联合概率分布作为先验(在第一阶段初始化为均匀分布),同理可得优化目标的证据下界,
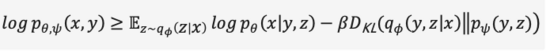
在第一阶段的训练过程中,DALL·E使用了一个离散变分自编码器(Discrete VAE)简称dVAE,是Vector Quantized VAE(VQ-VAE)的升级版。在VAE中我们用一个概率分布刻画了连续的隐层空间,通过随机采样得到隐层编码,但是这个编码并不像离散的语言文字具有确定性。为了学习图像隐层空间的“语言”,VQ-VAE使用了一组可学习的向量量化表示隐层空间,这个量化的隐层空间我们称为Embedding Space或者Codebook/Vocabulary。VQ-VAE的训练过程和预测过程旨在寻找与图像编码向量距离最近的隐层向量,再将映射得到的向量语言解码成图像(图12),损失函数由三部分构成,分别优化重构损失、更新Embedding Space和更新编码器,梯度终止。
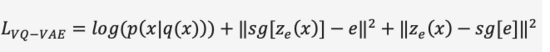
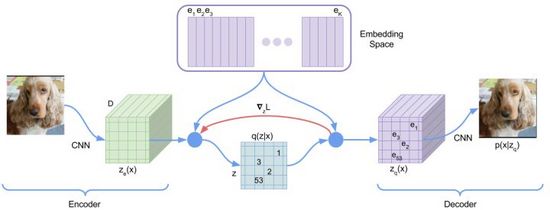
图12. VQ-VAE
VQ-VAE由于最近邻选择假设使其后验概率是确定的,即距离最近的隐层向量概率为1其余为0,不具有随机性;距离最近的向量选择过程不可导,使用了straight-through estimator方法将的梯度传递给。
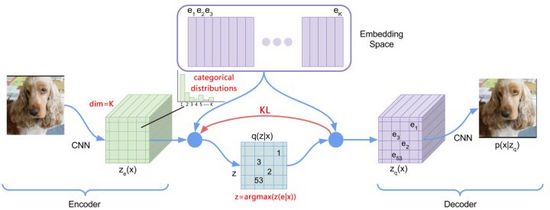
图13. dVAE
为了优化上述问题,DALL·E使用Gumbel-Softmax构建了新的dVAE(图13),解码器的输出变为Embedding Space上32*32个K=8192维分类概率,在训练过程中对分类概率的Softmax计算加入噪声引入随机性,使用逐步减小的温度让概率分布近似one-hot编码,对隐层向量的选择重参数化使其可导(式(11)),推理过程中仍取最近邻。
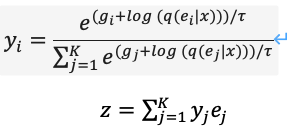
PyTorch实现中可设置hard=True输出近似的one-hot编码,同时通过 y_hard = y_hard - y_soft.detach() + y_soft 保持可导。
当第一阶段训练完成后,我们可以固定dVAE对于每对文本-图像生成预测目标的图像Tokens。在第二阶段训练过程中,DALL·E使用BPE方法将文本先编码成和图像Tokens相同维度d=3968的文本Tokens,再将文本Tokens和图像Tokens Concat到一起,加入位置编码和Padding编码,使用Transformer Encoder进行自回归预测,如图14所示。为了提升计算速度,DALL·E还采用了Row、Column、Convolutional三种稀疏化的attention mask机制。
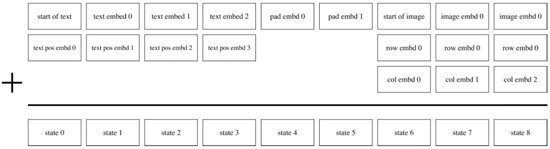
图14. DALL·E的自回归解码器
基于上述实现,DALL·E可根据文本输入不仅可生成“真实”的图像,还可进行融合创作、场景理解和风格转化,如图15。此外,DALL·E在零样本和专业领域的效果可能变差,且生成的图像分辨率(256*256)较低。

图15. DALL·E的多种生成场景
4.2 DALL·E 2
为了进一步提升图像生成质量和探求文本-图像特征空间的可解释性,OpenAI结合扩散模型和CLIP在2022年4月提出了DALL·E 2,不仅将生成尺寸增加到了1024*1024,还通过特征空间的插值操作,可视化了文本-图像特征空间的迁移过程。
如图16所示,DALL·E 2将CLIP对比学习得到的text embedding、image embedding作为模型输入和预测对象,具体过程是学习一个先验Prior,从text预测对应的image embedding,文章分别用自回归Transformer和扩散模型两种方式训练,后者在各数据集上表现更好;再学习一个扩散模型解码器UnCLIP,可看做是CLIP图像编码器的逆向过程,将Prior预测得到的image embedding作为条件加入中实现控制,text embedding和文本内容作为可选条件,为了提升分辨率UnCLIP还增加了两个上采样解码器(CNN网络)用于逆向生成更大尺寸的图像。
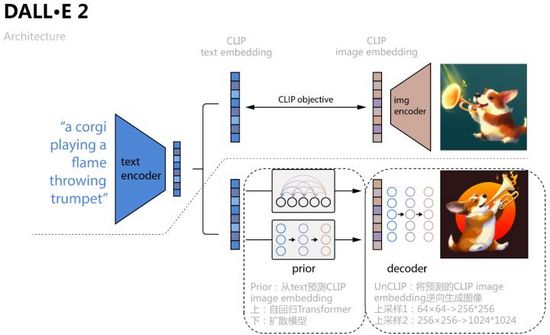
图16. DALL·E 2
在Prior的扩散模型训练中,DALL·E 2使用了一个Transformer Decoder预测扩散过程,输入序列为BPE-encoded text + text embedding + timestep embedding+ 当前加噪的image embedding,预测去噪的image embedding,用MSE构建损失函数,
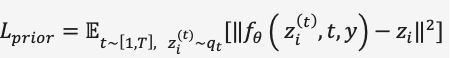
DALL·E 2为避免模型对于特定的文本标签产生定向类型的生成结果,降低了特征丰富性,对于扩散模型的预测条件增加限制,保证无分类器引导(classifier-free guidance)。例如,在Prior和UnCLIP的扩散模型训练中,对于加入text embedding等条件设置drop概率,使生成过程不完成依赖条件输入。因此在逆向生成过程中,我们可以通过image embedding采样生成同一张图像的不同变体同时保持基本特征,还可以分别在image embedding和text embedding插值,控制插值比例可生成平滑迁移的可视化结果,如图17所示。

图17. DALL·E 2可实现的图像特征保持和迁移
DALL·E 2对Prior和UnCLIP的有效性做了大量验证实验,例如通过三种方式1)只将文本内容输入UnCLIP生成模型;2)只将文本内容和text embedding输入UnCLIP生成模型;3)在上述方法基础上加入Prior预测的image embedding,三种方法的生成效果逐渐提升验证了Prior有效性。另外,DALL·E 2使用了PCA对隐层空间的embedding降维,随着维度降低生成图像的语义特征逐渐减弱。最后,DALL·E 2在MS-COCO数据集上对比了其他方法,取得了FID= 10.39最好的生成质量(图18)。
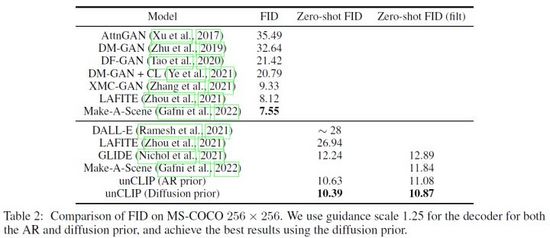
图18. DALL·E 2在MS-COCO数据集上的对比结果
4.3 ERNIE-VILG
ERNIE-VILG是百度文心在2022年初提出的中文场景的文本-图像双向生成模型。
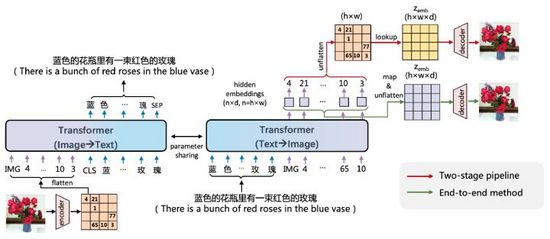
图19. ERNIE-VILG
ERNIE-VILG的思路和DALL·E相似,通过预训练的变分自编码器编码图像特征,使用Transformer将文本Tokens和图像Tokens自回归预测,主要不同点在于:
- ERNIE-VILG依靠百度文心平台技术,可以处理中文场景;
- 除了Text-to-Image自回归过程,还建模了Image-to-Text方向过程,且双向过程参数共享;
- Text-to-Image自回归过程中,Text Tokens之间不做mask处理;
- 图像编解码使用了VQ-VAE和VQ-GAN,通过map&flatten将的图像解码过程与自回归过程连接,实现了端到端训练。
ERNIE-VILG的另一个强大之处是,在中文场景可以处理多个物体和复杂位置关系的生成问题,如图20。

图20. ERNIE-VILG的生成示例
四、总结
本文通过实例解读了最新的以文生图的新范式,包含变分自编码器和扩散模型等生成方法的应用,CLIP等文本-图像潜在空间表示学习的方法,以及离散化和重参数化等建模技术。
现如今文本到图像的生成技术有较高的门槛,其训练成本远超人脸识别、机器翻译、语音合成等单模态方法,以DALL·E为例,OpenAI收集并标注了2.5亿对样本,使用了1024块V100 GPU训练了120亿参数量的模型。此外,图像生成领域一直存在种族歧视、暴力情色、敏感隐私等问题。从2020年开始,越来越多的AI团队投入到跨模态生成研究中,不久的将来我们可能在真实世界和生成世界中真假难分。

























