作者 | 中国移动云能力中心PaaS产品部 赵慧慧
近些年来,容器技术迅速席卷全球,颠覆了应用的开发、交付和运行模式。容器技术作为云原生技术领域的技术基石,也是现今最热门的一种服务器端技术。容器以及容器编排技术成为基础设施领域最炙手可热的关键词,随着容器及周边生态技术的蓬勃发展,容器社区当仁不让成为开源社区最活跃的生态圈之一。同时,以容器技术为核心的容器生态圈在云计算、互联网等领域得到了广泛应用。
那么,容器到底是怎么一回事?它有什么样的特性?又是如何运行起来的呢?
下面我们简单介绍一下以Docker容器为主的Linux容器的实现原理。
容器最初是为了解决PaaS项目应用的托管问题,其目的是提供一个便利的打包机制和包运行技术,来解决应用在部署过程中云端环境和本地环境不一致的问题,从而实现应用一次打包随处部署的便捷功能。
容器通过提供一个容器镜像,对应用程序运行所需的整个环境(包括操作系统)进行打包;同时在运行时,将压缩包放入“沙盒”中解压并在其中运行,利用虚拟化的“沙盒”技术实现在同一操作系统上不同应用程序之间无感知的运行,仿佛应用程序自己独占整个操作系统的资源。
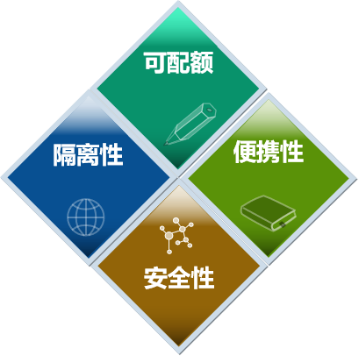
容器具有便携性、隔离性、可配额和安全性四个特性。
利用容器技术,用户部署应用只需要两步,第一步制作应用的容器镜像,第二步是利用容器命令创建一个”沙盒“,在沙盒中运行自己的应用。
那么,容器的镜像是如何制作的?容器所谓的“沙盒”的实现原理又是通过什么技术来实现的?
容器镜像是利用Linux的Union FS技术,将应用程序所依赖的运行操作系统、工具包、依赖库、配置文件、运行脚本等各种环境信息以分层的方式联合挂载到同一个目录下,作为镜像的根目录。
沙盒技术,顾名思义,就是在应用程序运行时为程序设计一个边界,使得不同应用之间可以独立运行而不互相干扰。其实这个沙盒技术并不是什么黑科技,其本质就是利用Linux的Namespace和Cgroups来实现应用隔离和资源限制,它并不是一个真正存在的边界。

综上所述,容器本质上是基于Linux内核的Namespace、Cgroups和Union FS等技术对进程进行封装隔离的操作系统层面的虚拟化技术。
01容器运行原理
接下来,我们展开介绍下,容器是如何利用沙盒技术实现进程的隔离与限制的,从而实现容器应用进程无感知运行的。依据前面的介绍,我们知道,该功能是基于Namespace和Cgroups实现的。
1.1 进程的资源隔离
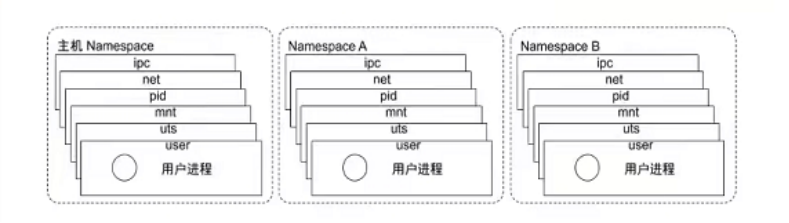
进程的隔离是指对进程视图的隔离,从进程的角度出发,能够看到的系统进程、网络信息、主机信息和用户信息等资源。容器对资源的隔离主要是通过Namespace技术实现的。Namespace是Linux Kernel提供的一种资源隔离方案,不同的Namespace下的资源是独立的,系统可以为容器进程分配不同的Namespace,从而保证各进程对彼此是透明的。
直接讲概念比较抽象,接下来,我们以进程资源为例,来介绍Namespace是如何实现容器进程间PID的隔离的。
我们利用Docker启动一个busybox容器并进入,运行ps指令:
zhh@DESKTOP-0EN6PGM:~$ docker run -it busybox /bin/sh
/ # ps -ef
PID USER TIME COMMAND
1 root 0:00 /bin/sh
8 root 0:00 ps -ef
我们再启动一个ubuntu容器并进入,运行ps指令:
zhh@DESKTOP-0EN6PGM:~$ docker run -it ubuntu /bin/sh
# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 10:19 pts/0 00:00:00 /bin/sh
root 7 1 0 10:19 pts/0 00:00:00 ps -ef
我们在宿主机上运行ps指令:
zhh@DESKTOP-0EN6PGM:~$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 May13 ? 00:00:00 /init
root 15 1 0 May13 ? 00:00:00 /init
root 123 15 0 May13 ? 00:00:33 /usr/bin/dockerd -p /var/run/docker.pid
root 141 123 0 May13 ? 00:01:16 containerd --config /var/run/docker/containerd/containerd.toml --log-lev
root 970 15 0 May13 ? 00:00:06 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 581ff6f571ae9a90fce
root 991 970 0 May13 ? 00:00:00 nginx: master process nginx -g daemon off;
zhh 1404 1069 0 18:15 pts/1 00:00:00 docker run -it busybox /bin/sh
root 1426 15 0 18:15 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 3483345c6e118a57aa0
root 1447 1426 0 18:15 ? 00:00:00 /bin/sh
root 1489 1 0 18:17 ? 00:00:00 /init
root 1490 1489 0 18:17 ? 00:00:00 /init
zhh 1491 1490 0 18:17 pts/3 00:00:00 -bash
zhh 1711 1491 0 18:19 pts/3 00:00:00 docker run -it ubuntu /bin/sh
root 1732 15 0 18:19 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace moby -id e465bbb573ad8f9e365
root 1752 1732 0 18:19 ? 00:00:00 /bin/sh
zhh 1796 1277 0 18:20 pts/2 00:00:00 ps -ef
可以看到,busybox、ubuntu和宿主机上的进程,看到的PID都是不一样的,这就是所谓的进程资源的视图隔离;而且我们发现,busybox和ubuntu两个容器进程的初始PID都是1,但是在宿主机进程中,我们发现他们真正的PID分别是1447和1752。这种机制其实就是对被隔离应用的进程空间动了手脚,使得这些进程只能”看到“重新计算过的PID(如PID=1),而实际在宿主机的操作系统中,他们的进程号还是原来的PID。
这种容器进程的PID的不同视图就是通过Linux的Namespace机制实现的。具体的实现方法就是,在Linux创建新进程的时候,给进程创建方法clone指定一个可选参数CLONE_NEWPID:
int pid = clone(main_function, staci_size, CLONE_NEWPID | SIGCHLD, NULL)
这时,新创建的进程将会进入一个全新的进程空间。在这个进程空间里,只能看到自己这个Namespace下的进程。
另外,除了PID Namespace之外,Linux Kernel还提供了IPC、Network、Mount、UTS和USER其他五种类型的隔离,用来对各种进程上下文进行资源隔离。如Network Namespace用于让被隔离进程只“看到”当前Namespace下的网络设备和配置;我们在刚刚启动的busybox容器中查看网络,查看容器的ip信息:
zhh@DESKTOP-0EN6PGM:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: bond0: <BROADCAST,MULTICAST,MASTER> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 1a:ab:21:b6:fa:62 brd ff:ff:ff:ff:ff:ff
3: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether ce:18:83:36:ee:32 brd ff:ff:ff:ff:ff:ff
4: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1350 qdisc mq state UP group default qlen 1000
link/ether 00:15:5d:c1:47:08 brd ff:ff:ff:ff:ff:ff
inet 172.25.170.17/20 brd 172.25.175.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::215:5dff:fec1:4708/64 scope link
valid_lft forever preferred_lft forever
在宿主机上查看ip信息:
zhh@DESKTOP-0EN6PGM:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: bond0: <BROADCAST,MULTICAST,MASTER> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 1a:ab:21:b6:fa:62 brd ff:ff:ff:ff:ff:ff
3: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether ce:18:83:36:ee:32 brd ff:ff:ff:ff:ff:ff
4: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1350 qdisc mq state UP group default qlen 1000
link/ether 00:15:5d:c1:47:08 brd ff:ff:ff:ff:ff:ff
inet 172.25.170.17/20 brd 172.25.175.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::215:5dff:fec1:4708/64 scope link
valid_lft forever preferred_lft forever
由此可以发现,容器进程实际上就是通过在创建进程时指定所需要启用的一组Namespace参数来为进程开辟一系列Namespace,使得容器进程拥有自己独特的文件系统、网络信息、用户管理、主机名等,保证当前进程只能“看到”自己的资源,从而实现容器进程的资源隔离。
我们可以在/proc目录下找到刚刚启动的busybox进程中的所有Namespace:
zhh@DESKTOP-0EN6PGM:/proc/1711$ sudo ls -la /proc/1447/ns
[sudo] password for zhh:
total 0
dr-x--x--x 2 root root 0 May 15 18:15 .
dr-xr-xr-x 9 root root 0 May 15 18:15 ..
lrwxrwxrwx 1 root root 0 May 15 20:34 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 May 15 20:34 ipc -> 'ipc:[4026532324]'
lrwxrwxrwx 1 root root 0 May 15 20:34 mnt -> 'mnt:[4026532322]'
lrwxrwxrwx 1 root root 0 May 15 18:15 net -> 'net:[4026532327]'
lrwxrwxrwx 1 root root 0 May 15 20:34 pid -> 'pid:[4026532325]'
lrwxrwxrwx 1 root root 0 May 15 20:34 pid_for_children -> 'pid:[4026532325]'
lrwxrwxrwx 1 root root 0 May 15 20:34 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 May 15 20:34 uts -> 'uts:[4026532323]
1.2 进程的资源限制
前面我们介绍了容器进程实际上就是一个Linux进程,虽然它通过Namespace修改了进程的视图,使进程只能看到该Namespace下的各种资源,但Namespace只是限定了进程的“视线”;但这些被隔离进程与普通进程没有太大区别,它与其他普通进程一样共享宿主机上的所有资源,这意味着虽然它所能够使用的资源(如CPU、内存)随时可以被宿主机上的其他进程占用,当然它也可能用光所有的资源。“沙盒”除了对进程实现封闭的视图限制外,还需要是对进程进行资源限制。
容器技术对资源的限制主要是通过Linux Cgroups技术实现的。Cgroups是Linux下用于对一个或一组进程进行资源(CPU、内存、磁盘I/O、网络带宽)控制和监控的机制,简单点说它的主要作用就是限制一个进程组能够使用cpu、内存、磁盘、带宽等资源的上限。不同资源的具体管理工作由相应的Cgroups子系统来实现,在Ubuntu机器里,可以使用mount 指令看到所有的子系统:
zhh@DESKTOP-0EN6PGM:~$ mount -t cgroup
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
cgroup on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
可以看到,Cgroups有十几个子系统,系统通过这些子系统用来控制每种类型的资源,如cpu用来限制进程组可以访问的cpu使用率,cpuset用来在多核cpu系统中为任务分配单独的cpu和内存, memory用来限制进程组的内存使用上限及生成内存资源报告等。这些子系统是一系列文件系统目录,他们均在/sys/fs/cgroup目录路径下,Cgroups通过Hierarchy层级树的方式对资源进行管理,层级树把Cgroups串成一个树型结构,使Cgroups可以做到继承。
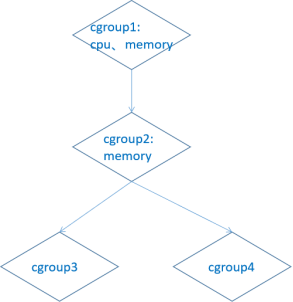
如图所示,cgroup1 中限制了使用 cpu 及 内存资源,它将控制子节点的 cpu 和内存分配(即限制 cgroup2、cgroup3、cgroup4 中的cpu及内存资源分配)。cgroup2 中限制了内存资源,但是没有限制cpu的资源。结果是 cgroup3 和 cgroup4 的内存资源受 cgroup2内存的限制,同时cgroup3 和 cgroup4 受 cgroup1 的cpu的限制。
针对不同的资源限制,只要将限制策略在不同的子系统目录中进行配置即可。每种资源具体被限制的方法,可以在子系统目录下看到。如在cpu子系统中,可以看到如下文件:
zhh@DESKTOP-0EN6PGM:~$ ll /sys/fs/cgroup/cpu
total 0
dr-xr-xr-x 3 root root 0 May 13 19:28 ./
drwxr-xr-x 16 root root 320 May 13 19:28 ../
-rw-r--r-- 1 root root 0 May 13 19:42 cgroup.clone_children
-rw-r--r-- 1 root root 0 May 13 19:42 cgroup.procs
-r--r--r-- 1 root root 0 May 13 19:42 cgroup.sane_behavior
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 May 13 19:32 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 May 13 19:32 cpu.rt_period_us
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 May 13 19:32 cpu.shares
-r--r--r-- 1 root root 0 May 13 19:42 cpu.stat
-rw-r--r-- 1 root root 0 May 13 19:42 notify_on_release
-rw-r--r-- 1 root root 0 May 13 19:42 release_agent
-rw-r--r-- 1 root root 0 May 13 19:42 tasks
可以看到对cpu的限制方法有很多。其中,cpu.shares表示可出让的能够获得的CPU使用时间的相对值,cpu.cfs_period_us用来配置时间周期长度,cpu.cfs_quota_us配置当前Cgroup在cpu.cfs_period_us时间内最多可以使用的CPU时间数。所以我们可以通过cpu.cfs_period_us和cpu.cfs_quota_us组合设置,来限制进程组的CPU使用率。
以一个例子来说明下具体控制过程:
首先建立一个用于限制cpu的控制组,在/sys/fs/cgroup/cpu目录下创建一个子目录test
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu$ sudo mkdir test
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu$ cd test
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu/test$ ll
total 0
drwxr-xr-x 2 root root 0 May 16 11:13 ./
dr-xr-xr-x 4 root root 0 May 13 19:28 ../
-rw-r--r-- 1 root root 0 May 16 11:13 cgroup.clone_children
-rw-r--r-- 1 root root 0 May 16 11:13 cgroup.procs
-rw-r--r-- 1 root root 0 May 16 11:13 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 May 16 11:13 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 May 16 11:13 cpu.rt_period_us
-rw-r--r-- 1 root root 0 May 16 11:13 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 May 16 11:13 cpu.shares
-r--r--r-- 1 root root 0 May 16 11:13 cpu.stat
-rw-r--r-- 1 root root 0 May 16 11:13 notify_on_release
-rw-r--r-- 1 root root 0 May 16 11:13 tasks
可以发现,在这个新建的test目录下,自动生成了子系统对应的资源限制文件。
现在看下cpu.cfs_quota_us cpu.cfs_period_us 两个文件的内容:
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu/test$ cat cpu.cfs_quota_us cpu.cfs_period_us
-1
100000
cpu.cfs_quota_us的初始值为-1,表示还没有任何cpu时间的限制。
第二步,在后台执行这样一个脚本程序:while : ;do : ; done &,它执行了一个死循环,可以把系统CPU占满;我们用top指令查看CPU占用情况,输出显示,CPU的使用率已经到100%了。
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu/test$ while : ;do : ; done &
[1] 1918
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu/test$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1918 zhh 20 0 10168 1824 0 R 100.0 0.0 0:17.76 bash
现在,我们修改test目录下的文件,来对test控制组设置cpu最大使用上限。
首先向cpu.cfs_quota_us文件写入20ms,这意味着每100ms(pu.cfs_period_us文件设置)的时间里,被test控制组限制的进程只能使用20ms(cpu.cfs_quota_us)的CPU时间。
echo 20000 > cpu.cfs_quota_us
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu/test$ cat cpu.cfs_quota_us cpu.cfs_period_us
20000
100000
其次,将刚刚创建的死循环进程PID写入tasks文件,使得test控制组可以控制该进程:
echo 1918 > tasks
通过这两步设置,该进程最大可使用的CPU带宽就被控制到了20%。我们运行top指令来验证下结果:
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu/test$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1918 zhh 20 0 10168 1824 0 R 19.6 0.0 15:48.34 bash
可以看到,该进程的CPU使用率立即降到了20%以下。
通过上述例子我们了解到Cgroups控制进程的方法,简单而言,它就是一个子系统目录(如test)加上一组资源限制文件(如/test目录下的各种限制方法文件)的组合。对于Linux容器来说,他们只需要在每个子系统下面为每个容器创建一个控制组,然后在启动容器进程之后,把这个进程的PID填写到对应控制组的tasks文件中即可。
以Docker项目为例,在安装完Docker之后,Docker会自动在Cgroups每个子系统中创建docker控制组作为Docker容器进程的根控制组。
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu$ ll /sys/fs/cgroup/cpu
2.total 0
dr-xr-xr-x 4 root root 0 May 13 19:28 ./
drwxr-xr-x 16 root root 320 May 13 19:28 ../
-rw-r--r-- 1 root root 0 May 13 19:42 cgroup.clone_children
-rw-r--r-- 1 root root 0 May 13 19:42 cgroup.procs
-r--r--r-- 1 root root 0 May 13 19:42 cgroup.sane_behavior
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 May 13 19:32 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 May 13 19:32 cpu.rt_period_us
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 May 13 19:32 cpu.shares
-r--r--r-- 1 root root 0 May 13 19:42 cpu.stat
drwxr-xr-x 5 root root 0 May 13 19:34 docker/
-rw-r--r-- 1 root root 0 May 13 19:42 notify_on_release
-rw-r--r-- 1 root root 0 May 13 19:42 release_agent
-rw-r--r-- 1 root root 0 May 13 19:42 tasks
drwxr-xr-x 2 root root 0 May 16 11:13 test/
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/cpu$ ll /sys/fs/cgroup/memory
total 0
dr-xr-xr-x 3 root root 0 May 13 19:28 ./
drwxr-xr-x 16 root root 320 May 13 19:28 ../
-rw-r--r-- 1 root root 0 May 16 10:02 cgroup.clone_children
--w--w--w- 1 root root 0 May 16 10:02 cgroup.event_control
-rw-r--r-- 1 root root 0 May 16 10:02 cgroup.procs
-r--r--r-- 1 root root 0 May 16 10:02 cgroup.sane_behavior
drwxr-xr-x 5 root root 0 May 13 19:34 docker/
-r--r--r-- 1 root root 0 May 16 10:02 memory.stat
-rw-r--r-- 1 root root 0 May 13 19:32 memory.swappiness
-r--r--r-- 1 root root 0 May 16 10:02 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 May 16 10:02 memory.use_hierarchy
-rw-r--r-- 1 root root 0 May 16 10:02 notify_on_release
-rw-r--r-- 1 root root 0 May 16 10:02 release_agent
-rw-r--r-- 1 root root 0 May 16 10:02 tasks
zhh@DESKTOP-0EN6PGM:/sys/fs/cgroup/blkio$ ll /sys/fs/cgroup/blkio
total 0
dr-xr-xr-x 3 root root 0 May 13 19:28 ./
drwxr-xr-x 16 root root 320 May 13 19:28 ../
--w------- 1 root root 0 May 16 12:35 blkio.reset_stats
-rw-r--r-- 1 root root 0 May 16 12:35 cgroup.clone_children
-rw-r--r-- 1 root root 0 May 16 12:35 cgroup.procs
-r--r--r-- 1 root root 0 May 16 12:35 cgroup.sane_behavior
drwxr-xr-x 5 root root 0 May 13 19:34 docker/
-rw-r--r-- 1 root root 0 May 16 12:35 notify_on_release
-rw-r--r-- 1 root root 0 May 16 12:35 release_agent
-rw-r--r-- 1 root root 0 May 16 12:35 tasks
以后,每启动一个Docker容器,Docker都会在每个子系统的docker控制组中以该容器进程的container id为名称新建一个子控制组,同时将该进程的PID添加到子控制组的tasks文件中,从而完成对新运行Docker容器进程的各种资源的限制。
zhh@DESKTOP-0EN6PGM:~$ ll /sys/fs/cgroup/cpu/docker
total 0
drwxr-xr-x 4 root root 0 May 13 19:34 ./
dr-xr-xr-x 4 root root 0 May 13 19:28 ../
drwxr-xr-x 2 root root 0 May 15 18:15 3483345c6e118a57aa08c2857b1917870b55ef9fad607385776f335d9a3ec98e/
-rw-r--r-- 1 root root 0 May 13 19:42 cgroup.clone_children
-rw-r--r-- 1 root root 0 May 13 19:42 cgroup.procs
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.rt_period_us
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 May 13 19:42 cpu.shares
-r--r--r-- 1 root root 0 May 13 19:42 cpu.stat
drwxr-xr-x 2 root root 0 May 15 18:19 e465bbb573ad8f9e365ef4c350cd0b4ad0e7c15f8b553deca85ed65e3b3d8a0e/
-rw-r--r-- 1 root root 0 May 13 19:42 notify_on_release
-rw-r--r-- 1 root root 0 May 13 19:42 tasks
zhh@DESKTOP-0EN6PGM:~$ cat /sys/fs/cgroup/cpu/docker/3483345c6e118a57aa08c2857b1917870b55ef9fad607385776f335d9a3ec98e/tasks
1447
02容器镜像
知道了容器是怎么运行的,回过头来,我们再看下容器的镜像是如何生成的。前面我们说了,容器是利用Union FS对应用程序及其依赖的环境打包的,那具体是如何是对应用程序打包的呢?在讲解打包过程之前,我们先简单介绍下打包机制依赖的底层技术Union FS。
Union FS(Union File System,联合文件系统),是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下,简单来说就是将不同位置的目录联合挂载到同一个目录下。
Linux常用的UnionFS 有AUFS、OverlayFS 和 Btrfs 等,我们以实现相对简单的 OverlayFS 为例介绍下联合挂载机制。
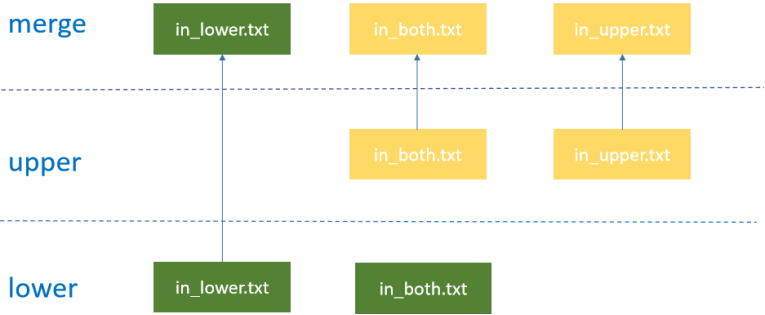
OverlayFS 文件系统主要有三层,lower层、upper层和merged。lower层是只读层,用户不能修改这个层的文件;upper层是可读写层,用户能够修改这个层的文件;而 merged是合并层,把 lower 层和 upper层的文件合并展示,合并时上层目录文件覆盖。具体的合并原则是:不同层的文件会合并到一起,相同文件upper层覆盖lower层;同时支持目录级别的合并,同名同级目录按照前述规则递归合并。
比如,有两个目录lower和upper,他们分别有两个文件:
zhh@DESKTOP-0EN6PGM:~/zhh_test$ tree
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
└── upper
├── in_both.txt
└── in_upper.txt
zhh@DESKTOP-0EN6PGM:~/zhh_test$ cat ./lower/in_both.txt
from lower
zhh@DESKTOP-0EN6PGM:~/zhh_test$ cat ./upper/in_both.txt
from upper
通过联合挂载的方式将这两个目录挂载到一个公共的目录merged上:
zhh@DESKTOP-0EN6PGM:~/zhh_test$ mkdir work merged
zhh@DESKTOP-0EN6PGM:~/zhh_test$ sudo mount -t overlay overlay -o lowerdir=lower,upperdir=upper,workdir=work merged
此时查看merged目录的内容,就能看到lower和upper目录的文件被合并到了一起,同时合并后的in_both.txt文件的内容来源于upper目录中in_both.txt。
zhh@DESKTOP-0EN6PGM:~/zhh_test$ tree
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
│ ├── in_both.txt
│ ├── in_lower.txt
│ └── in_upper.txt
├── upper
│ ├── in_both.txt
│ └── in_upper.txt
└── work
└── work [error opening dir]
zhh@DESKTOP-0EN6PGM:~/zhh_test$ cat ./merged/in_both.txt
from upper
容器镜像就是通过这种分层和联合挂载机制进行制作的。一个容器镜像包含应用程序可用的文件系统和其他元数据,如运行工具包、代理、可执行文件等,这些镜像信息都是以不同的层级堆叠到一起,这些增量的层最后合并生成一个容器镜像。
我们来看下一个简单的nginx镜像(Docker版本是20.10.7):
zhh@DESKTOP-0EN6PGM:~/zhh_test$ docker image inspect nginx
[
{
"Id": "sha256:605c77e624ddb75e6110f997c58876baa13f8754486b461117934b24a9dc3a85",
"RepoTags": [
"nginx:latest"
],
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/43901fba40fd6f81050240748bee4ec1ac3be768def67b5813eb8f956b1e52de/diff:/var/lib/docker/overlay2/5a2f34d3d0f96655f3dce2fe822e5a14d728175f6604e58828f866cae7d4e315/diff:/var/lib/docker/overlay2/262e9cdaa2404c678d64f47025814d44514f7b4466d3e7eb5045d95fc81a0b4a/diff:/var/lib/docker/overlay2/12ecab077a366b393f5bf6ffa46fde9c7b72823cf8cc5149ee070d9d3ead19aa/diff:/var/lib/docker/overlay2/b1620d376b7e3f656ce1ae28c40f1c6a4d7ae094852226090fe38dba680468d4/diff",
"MergedDir": "/var/lib/docker/overlay2/eadef61b88e735d1b04f9f095d766d69f588f3ba2d926461a46fe1ee7823c7da/merged",
"UpperDir": "/var/lib/docker/overlay2/eadef61b88e735d1b04f9f095d766d69f588f3ba2d926461a46fe1ee7823c7da/diff",
"WorkDir": "/var/lib/docker/overlay2/eadef61b88e735d1b04f9f095d766d69f588f3ba2d926461a46fe1ee7823c7da/work"
},
"Name": "overlay2"
},
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:2edcec3590a4ec7f40cf0743c15d78fb39d8326bc029073b41ef9727da6c851f",
"sha256:e379e8aedd4d72bb4c529a4ca07a4e4d230b5a1d3f7a61bc80179e8f02421ad8",
"sha256:b8d6e692a25e11b0d32c5c3dd544b71b1085ddc1fddad08e68cbd7fda7f70221",
"sha256:f1db227348d0a5e0b99b15a096d930d1a69db7474a1847acbc31f05e4ef8df8c",
"sha256:32ce5f6a5106cc637d09a98289782edf47c32cb082dc475dd47cbf19a4f866da",
"sha256:d874fd2bc83bb3322b566df739681fbd2248c58d3369cb25908d68e7ed6040a6"
]
},
}
]
从上面可以看到,该nginx基础镜像由6个镜像层组成,它利用overlay2联合文件系统,合并/var/lib/docker/overlay2/43901fba***等lower层的目录和/var/lib/docker/overlay2/eadef61b8***等upper层的目录,构建出的nginx文件系统目录。
为了便捷镜像的制作过程和减少镜像的存储空间,容器镜像可以基于已经制作好的一些基础镜像(如系统文件镜像)进行构建,基础镜像以一个基础层(Layer)的形式内置于镜像层中;同时容器的镜像层可以在多个镜像之间共享和征用,如果某个已经被下载的容器已经包含了后面下载的镜像的某些层,那么后面下载的镜像就无须再下载这些层,两个镜像共享这些公共的镜像层,这种分层共享的方法大大提升了镜像在网络上的分发效率。
但是容器运行的时候,可能会修改这些基础层的文件内容,一旦基础层的文件系统被修改,那它就无法以一个纯净的标准状态被其他镜像引用。如何在基础层不被修改的前提下,实现容器修改的需求,从而保证基础镜像的一致性呢?
容器技术设计基础镜像层为只读层,这些基础镜像层的挂载方式都是只读的,不允许被修改。同时在基础镜像之上又增加了一个可读写层,挂载方式为rw(即read write),专门用于满足容器修改文件系统内容的需求。容器在对文件修改时,如果该文件已经在基础层,则会先将此文件复制到可读写层然后再应用进程的修改到文件,因此进程修改的是该文件在可读写层的拷贝,依据UnionFS合并原理,上层文件覆盖下层文件,因此用户进程看到的是修改后的可读写层的拷贝文件,这样就实现了对基础文件的“修改”功能。初始情况下,可读写层是空的,只有在容器进行写操作时,这些修改才会以增量的方式出现在该层,这种修改方式称为写时复制(Copy-on-Write)。当我们使用完了这个修改后的容器之后,还可以使用commit和push来保存这个修改过的可读写层,并上传到公共的镜像仓库供他人使用。
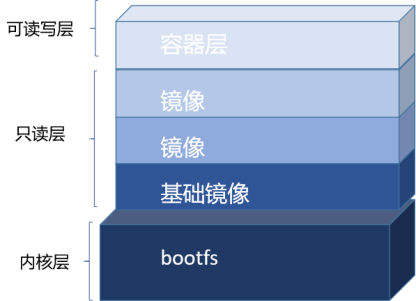
最终,在容器运行时,这三类层被联合挂载到容器的根目录下,表现为一个包含操作系统的应用程序环境供容器使用。当然,这个镜像只是操作系统的文件和目录,并不包含操作系统内核,容器真正运行还是基于宿主机的系统内核。
03总结
以上,我们介绍了Linux容器技术的实现方式,主要有镜像实现和运行时实现两个方面。容器镜像以UnionFS为技术载体通过分层镜像的设计来组件增量式的容器镜像,在镜像制作完成之后,Linux系统基于该镜像系统文件启动容器,并通过Namespace技术对容器的视图做限制,同时利用Cgroups控制进程最大可使用的各类系统资源。