延时消息(定时消息)指的在分布式异步消息场景下,生产端发送一条消息,希望在指定延时或者指定时间点被消费端消费到,而不是立刻被消费。
延时消息适用的业务场景非常的广泛,在分布式系统环境下,延时消息的功能一般会在下沉到中间件层,通常是 MQ 中内置这个功能或者内聚成一个公共基础服务。
本文旨在探讨常见延时消息的实现方案以及方案设计的优缺点。

实现方案
基于外部存储实现的方案
这里讨论的外部存储指的是在 MQ 本身自带的存储以外又引入的其他的存储系统。
基于外部存储的方案本质上都是一个套路,将 MQ 和 延时模块 区分开来,延时消息模块是一个独立的服务/进程。延时消息先保留到其他存储介质中,然后在消息到期时再投递到 MQ。当然还有一些细节性的设计,比如消息进入的延时消息模块时已经到期则直接投递这类的逻辑,这里不展开讨论。
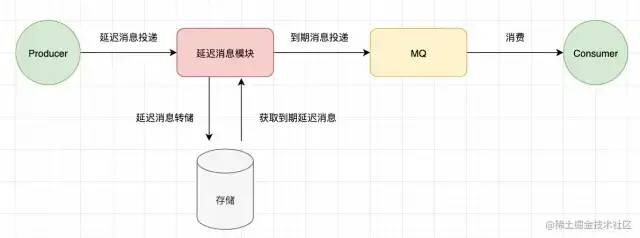
下述方案不同的是,采用了不同的存储系统。
基于 数据库(如MySQL)
基于关系型数据库(如MySQL)延时消息表的方式来实现。
CREATE TABLE `delay_msg` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`delivery_time` DATETIME NOT NULL COMMENT '投递时间',
`payloads` blob COMMENT '消息内容',
PRIMARY KEY (`id`),
KEY `time_index` (`delivery_time`)
)
通过定时线程定时扫描到期的消息,然后进行投递。定时线程的扫描间隔理论上就是你延时消息的最小时间精度。
- 优点:实现简单;
- 缺点:B+Tree索引不适合消息场景的大量写入;
基于 RocksDB
RocksDB 的方案其实就是在上述方案上选择了比较合适的存储介质。
RocksDB 使用的是LSM Tree,LSM 树更适合大量写入的场景。滴滴开源的DDMQ中的延时消息模块 Chronos 就是采用了这个方案。
DDMQ 这个项目简单来说就是在 RocketMQ 外面加了一层统一的代理层,在这个代理层就可以做一些功能维度的扩展。延时消息的逻辑就是代理层实现了对延时消息的转发,如果是延时消息,会先投递到 RocketMQ 中 Chronos 专用的 topic 中。延时消息模块 Chronos 消费得到延时消息转储到 RocksDB,后面就是类似的逻辑了,定时扫描到期的消息,然后往 RocketMQ 中投递。
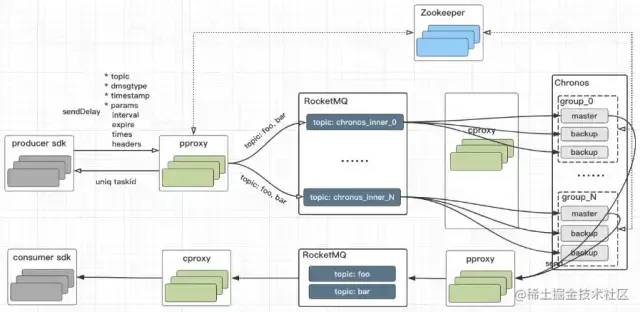
这个方案老实说是一个比较重的方案。因为基于 RocksDB 来实现的话,从数据可用性的角度考虑,你还需要自己去处理多副本的数据同步等逻辑。
- 优点:RocksDB LSM 树很适合消息场景的大量写入;
- 缺点:实现方案较重,如果你采用这个方案,需要自己实现 RocksDB 的数据容灾逻辑;
基于Redis
再来聊聊 Redis 的方案。下面放一个比较完善的方案。
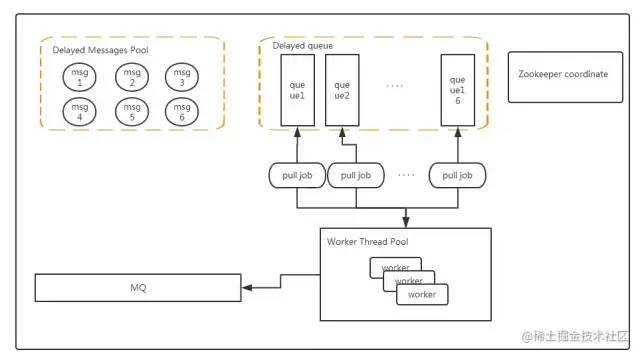
- Messages Pool 所有的延时消息存放,结构为KV结构,key为消息ID,value为一个具体的message(这里选择Redis Hash结构主要是因为hash结构能存储较大的数据量,数据较多时候会进行渐进式rehash扩容,并且对于HSET和HGET命令来说时间复杂度都是O(1))
- Delayed Queue是16个有序队列(队列支持水平扩展),结构为ZSET,value 为 messages pool中消息ID,score为过期时间(分为多个队列是为了提高扫描的速度)
- Worker 代表处理线程,通过定时任务扫描 Delayed Queue 中到期的消息
这个方案选用 Redis 存储在我看来有几点考虑:
- Redis ZSET 很适合实现延时队列;
- 性能问题,虽然 ZSET 插入是一个 O(logn) 的操作,但是Redis 基于内存操作,并且内部做了很多性能方面的优化。
但是这个方案其实也有需要斟酌的地方,上述方案通过创建多个 Delayed Queue 来满足对于并发性能的要求,但这也带来了多个 Delayed Queue 如何在多个节点情况下均匀分配,并且很可能出现到期消息并发重复处理的情况,是否要引入分布式锁之类的并发控制设计?
在量不大的场景下,上述方案的架构其实可以蜕化成主从架构,只允许主节点来处理任务,从节点只做容灾备份。实现难度更低更可控。
定时线程检查的缺陷与改进
上述几个方案中,都通过线程定时扫描的方案来获取到期的消息。
定时线程的方案在消息量较少的时候,会浪费资源,在消息量非常多的时候,又会出现因为扫描间隔设置不合理导致延时时间不准确的问题。可以借助 JDK Timer 类中的思想,通过 wait-notify 来节省 CPU 资源。
获取中最近的延时消息,然后wait(执行时间-当前时间),这样就不需要浪费资源到达时间时会自动响应,如果有新的消息进入,并且比我们等待的消息还要小,那么直接notify唤醒,重新获取这个更小的消息,然后又wait,如此循环。
开源 MQ 中的实现方案
再来讲讲目前自带延时消息功能的开源MQ,它们是如何实现的
RocketMQ
RocketMQ 开源版本支持延时消息,但是只支持 18 个 Level 的延时,并不支持任意时间。只不过这个 Level 在 RocketMQ 中可以自定义的,所幸来说对普通业务算是够用的。默认值为“1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”,18个level。
通俗的讲,设定了延时 Level 的消息会被暂存在名为 SCHEDULE_TOPIC_XXXX的topic中,并根据 level 存入特定的queue,queueId = delayTimeLevel – 1,即一个queue只存相同延时的消息,保证具有相同发送延时的消息能够顺序消费。broker会调度地消费SCHEDULE_TOPIC_XXXX,将消息写入真实的topic。
下面是整个实现方案的示意图,红色代表投递延时消息,紫色代表定时调度到期的延时消息:
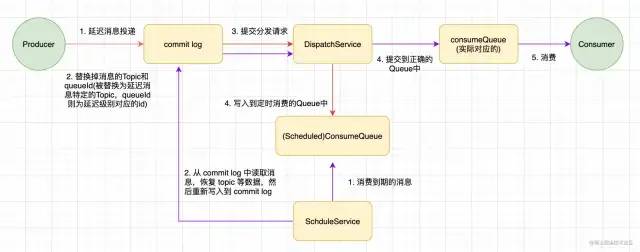
优点:
- Level 数固定,每个 Level 有自己的定时器,开销不大;
- 将 Level 相同的消息放入到同一个 Queue 中,保证了同一 Level 消息的顺序性;不同 Level 放到不同的 Queue 中,保证了投递的时间准确性;
- 通过只支持固定的Level,将不同延时消息的排序变成了固定Level Topic 的追加写操作。
缺点:
- Level 配置的修改代价太大,固定 Level 不灵活;
- CommitLog 会因为延时消息的存在变得很大。
Pulsar
Pulsar 支持“任意时间”的延时消息,但实现方式和 RocketMQ 不同。
通俗的讲,Pulsar 的延时消息会直接进入到客户端发送指定的 Topic 中,然后在堆外内存中创建一个基于时间的优先级队列,来维护延时消息的索引信息。延时时间最短的会放在头上,时间越长越靠后。在进行消费逻辑时候,再判断是否有到期需要投递的消息,如果有就从队列里面拿出,根据延时消息的索引查询到对应的消息进行消费。
如果节点崩溃,在这个 broker 节点上的 Topics 会转移到其他可用的 broker 上,上面提到的这个优先级队列也会被重建。
下面是 Pulsar 公众号中对于 Pulsar 延时消息的示意图。
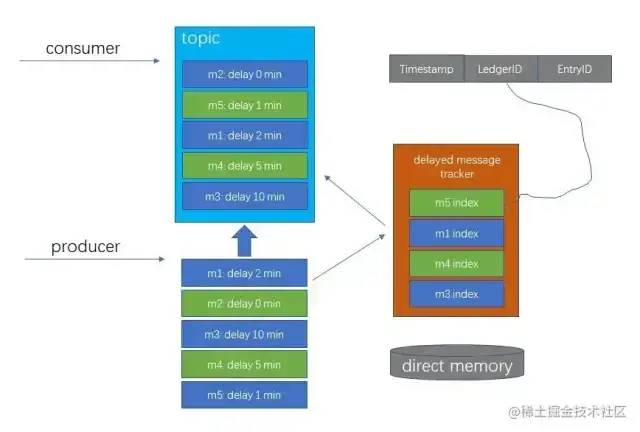
乍一看会觉得这个方案其实非常简单,还能支持任意时间的消息。但是这个方案有几个比较大的问题:
- 内存开销:维护延时消息索引的队列是放在堆外内存中的,并且这个队列是以订阅组(Kafka中的消费组)为维度的,比如你这个 Topic 有 N 个订阅组,那么如果你这个 Topic 使用了延时消息,就会创建 N 个 队列;并且随着延时消息的增多,时间跨度的增加,每个队列的内存占用也会上升。(是的,在这个方案下,支持任意的延时消息反而有可能让这个缺陷更严重);
- 故障转移之后延时消息索引队列的重建时间开销:对于跨度时间长的大规模延时消息,重建时间可能会到小时级别。
- 存储开销:延时消息的时间跨度会影响到 Pulsar 中已经消费的消息数据的空间回收。打个比方,你的 Topic 如果业务上要求支持一个月跨度的延时消息,然后你发了一个延时一个月的消息,那么你这个 Topic 中底层的存储就会保留整整一个月的消息数据,即使这一个月中99%的正常消息都已经消费了。
对于前面第一点和第二点的问题,社区也设计了解决方案,在队列中加入时间分区,Broker 只加载当前较近的时间片的队列到内存,其余时间片分区持久化磁盘,示例图如下图所示:
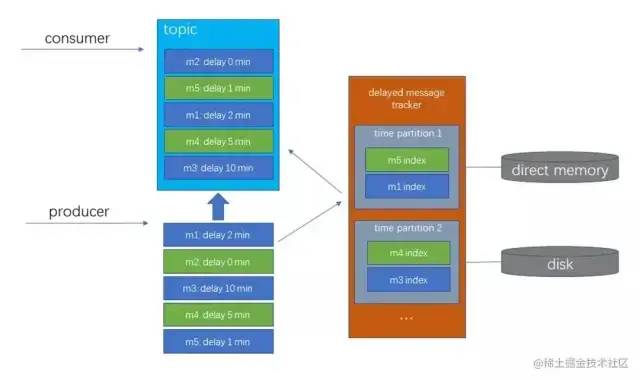
但是目前,这个方案并没有对应的实现版本。可以在实际使用时,规定只能使用较小时间跨度的延时消息,来减少前两点缺陷的影响。
另外,因为内存中存的并不是延时消息的全量数据,只是索引,所以可能要积压上百万条延时消息才可能对内存造成显著影响,从这个角度来看,官方暂时没有完善前两个问题也可以理解了。
至于第三个问题,估计是比较难解决的,需要在数据存储层将延时消息和正常消息区分开来,单独存储延时消息。
QMQ
QMQ提供任意时间的延时/定时消息,你可以指定消息在未来两年内(可配置)任意时间内投递。
把 QMQ 放到最后,是因为我觉得 QMQ 是目前开源 MQ 中延时消息设计最合理的。里面设计的核心简单来说就是 多级时间轮 + 延时加载 + 延时消息单独磁盘存储。
QMQ的延时/定时消息使用的是两层 hash wheel 来实现的。
第一层位于磁盘上,每个小时为一个刻度(默认为一个小时一个刻度,可以根据实际情况在配置里进行调整),每个刻度会生成一个日志文件(schedule log),因为QMQ支持两年内的延时消息(默认支持两年内,可以进行配置修改),则最多会生成 2 * 366 * 24 = 17568 个文件(如果需要支持的最大延时时间更短,则生成的文件更少)。
第二层在内存中,当消息的投递时间即将到来的时候,会将这个小时的消息索引(索引包括消息在schedule log中的offset和size)从磁盘文件加载到内存中的hash wheel上,内存中的hash wheel则是以500ms为一个刻度。
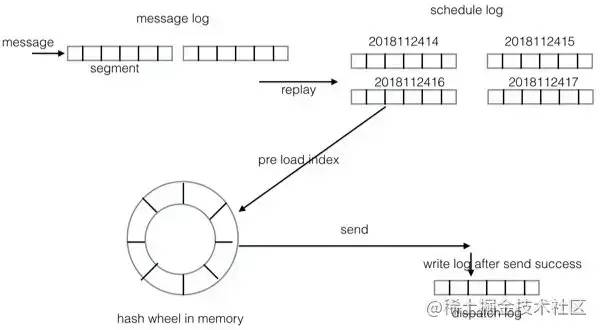
总结一下设计上的亮点:
- 时间轮算法适合延时/定时消息的场景,省去延时消息的排序,插入删除操作都是 O(1) 的时间复杂度;
- 通过多级时间轮设计,支持了超大时间跨度的延时消息;
- 通过延时加载,内存中只会有最近要消费的消息,更久的延时消息会被存储在磁盘中,对内存友好;
- 延时消息单独存储(schedule log),不会影响到正常消息的空间回收;
本文汇总了目前业界常见的延时消息方案,并且讨论了各个方案的优缺点。希望对读者有所启发。