













近年来,包括 GPT-2 在内的大型语言模型在文本生成方面非常成功,然而,大型语言模型会生成不连贯的长文本。一个原因是不能提前计划或表征长段文本动态。因此,它们常常产生游离的内容,语篇结构差,关联性低 ; 文本在生成时似乎没有锚定目标。当自回归模型生成更长的文本时,这些连贯性问题进一步恶化,因为模型很难推断超出其预期的文本终点。这些问题表明,大型语言模型目前无法正确捕捉文档从开始到结束的演变过程,而这对于完成面向目标的任务至关重要,例如故事、对话或菜谱生成。
但是,使用学习的局部动态去生成精准的 goal-conditioned trajectories 是很难的,尤其是长跨度的 trajectories。
在近期的一项研究中,斯坦福大学的研究者探索了一种替代方案,该替代方案明确假设了具有 goal-conditioned 生成的简单、固定动态模型。这种新颖的方法提高了长文本生成的性能,人类评估者对其输出的评分比基线方法高 28.6%。
研究者提出了时间控制(Time Control),作为学习已知 goal-conditioned 动态的潜在空间的方法。他们假设非目标导向生成的 meandering 文本在潜在空间内可以表征为布朗运动,这种运动使得相邻句子的嵌入变得更为相似,相距较远的句子相异。借助固定的开始和结束节点,目标导向的行为能够合并进该模型。在这种情况下,布朗运动变为了布朗桥,由此产生的潜在轨迹遵循简单的封闭式动态。

论文链接:https://arxiv.org/pdf/2203.11370.pdf
在时间控制中,研究者推导了一个新的对比目标,用于学习一个具有布朗桥动态的潜空间。然后,利用这个潜在空间来生成保持局部连贯性并提高全局连贯性的文本。为了完成文本生成,时间控制首先通过固定在起始点和终止点的布朗桥过程规划一个潜在的轨迹。然后它有条件地使用这个潜在规划生成句子。在本文中,研究者根据时间控制的潜在轨迹,通过微调 GPT2 来解码潜在规划、生成文本。来自时间控制的轨迹作为文档中的抽象语义位置,指导生成精细调整的语言模型。
总体来说,这项研究的贡献包括:
- 推导了时间控制语言模型,该语言模型用一种新的对比目标学习的布朗桥动态显式地模拟潜在结构。
- 在一系列文本域中,与针对具体任务的方法相比,时间控制能够生成更多或同样连贯的任务文本,包括文本填充和强制生成长文本。
- 验证了结论,潜在表征通过评估与人类实验的语篇一致性来竞争性地捕捉文本动态。
- 同时调整了方法,以理解对比目标的重要性,强化了布朗桥动态,并明确建立潜在动态模型。
时间控制(TIME CONTROL)
时间控制背后的洞察是学习一个具有平滑时间动态的潜在空间,用于建模和生成连贯的文本。研究者将时间控制分为三个部分。第一部分讨论通过对比学习训练编码器将句子映射到布朗桥的潜在空间。第二部分讨论了训练解码器从这个潜在空间重构句子。第三部分讨论了从时间控制生成文本。
使用布朗桥动态训练编码器
这里的编码器是一个从原始输入空间到潜在空间的非线性映射,f_θ: X → Z。该编码器的目标是将高维顺序数据映射到低维潜在随机过程,在本文中是布朗桥过程。在 t = 0 的任意起点 z_0 和 t = T 的终点 z_T 之间的布朗桥过程的密度是:
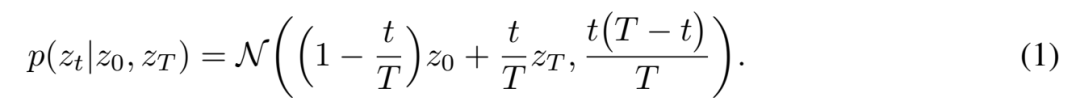
这种密度很容易理解: 它就像 trajectory 起点和终点之间的一个嘈杂的线性插值,起点的 z_T 应该更像 z_0,终点更像 z_T。不确定度在中间区域最高,在终点附近最低。
图 1 展示了目标如何转换为训练编码器的语言设置。客观事实取材于文献中的三句话。从同一文本中抽取的句子构成了一个平滑的潜在 trajectory,它们应该彼此接近,在潜在空间中遵循条件密度。从不同文本中抽取的句子不应该构成一个平稳的 trajectory,也不太可能遵循桥动态。

图 1
使用潜在规划训练解码器
这一部分讨论了如何训练一个语言模型来解码潜在的生成计划。首先使用预训练的编码器 f_θ 将训练数据集中的所有句子映射到学习的潜在空间。这给出了数据集文档的句子级潜在代码 (z0,. . . ,zT,. . ,zT) 的布朗桥轨迹。然后,并不从零开始学习解码器,而是根据过去上下文和潜在计划微调 GPT2 生成文本。
在推理时间根据潜在规划生成文本
图 2 展示了经过训练的解码器如何在推理时生成文本。给定两个端点 z_0,z_T,从一个潜在的布朗桥中抽取 trajectory 样本,然后由这个桥上的解码器生成。在许多情况下,我们可能并不清楚布朗桥的结束点。在这种情况下,可以编码一组对应于开始点和结束点的句子(例如训练集的第一个和最后一个句子),并对这些点拟合高斯形成一个密度估计。在这种情况下,生成涉及到首先从高斯采样,然后像以前一样从桥生成。有关训练和生成的更多细节,可以参阅附录 b。
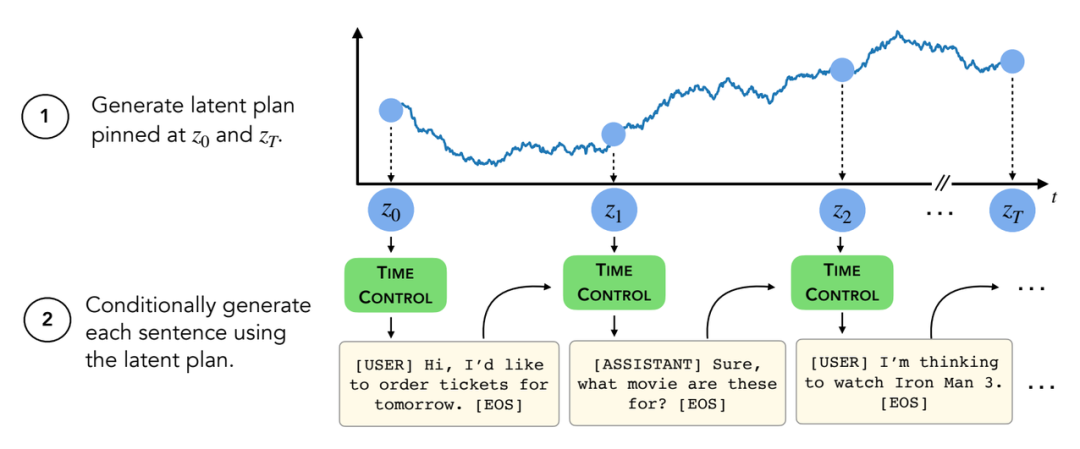
图 2
实验
在实验部分,研究者评估了时间控制捕捉文本动态的能力。具体来说,可拆分为以下的研究问题:
1、时间控制能够为局部文本动态建模吗?第 4.1 节使用一个句子排序预测任务来研究这个问题: 给定来自同一文档的两个句子,评估不同的模型是否能够预测它们的原始顺序。
2、时间控制能生成局部连贯的文本吗?第 4.2 节使用文本填充任务来研究这个问题: 给定前缀和后缀,评估不同模型之间填充的效果。
3、时间可以控制全局文本动态模型吗?第 4.3 节通过检查生成部分的长度来研究维基百科城市文章的文本生成问题。
4、时间控制可以生成长的连贯文档吗?第 4.4 节研究了强制长文本生成的这个问题: 评估模型在生成过程中被迫外推时如何保存全局文本统计数据(例如典型的部分顺序和长度)。
研究者使用不同的潜在维度运行时间控制(d = 8,16,32)。编码器架构是一个从 Huggingface 获得的冻结的 GPT2 预训练模型和可训练的 MLP 网络。研究者提取出与 EOS token 对应的最后一层隐藏状态,并在隐藏状态的顶部训练 4 层 MLP。该 MLP 网络具有中级的 ReLU 激活,并且受到随机梯度下降的训练,学习率为 1 e-4,动量为 0.9。
这里评价了时间控制在语篇连贯设置中对局部语篇动态的模拟效果(RQ1)。语篇连贯通常是通过测试线性分类器是否能够检测有序和无序句子对来衡量表征是否能够捕获语篇结构。这里比较了时间控制的编码器与 GPT2 的最后一层的隐藏状态对应的 EOS token(Radford et al., 2019), BERT (Devlin et al., 2019), ALBERT (Lan et al., 2019), Sentence BERT (Reimers et al., 2019), SimCSE (Gao et al., 2021)。后四种方法被设计为句子嵌入模型。如表 1 所示,也进行了消融研究。

表 1: 语篇连贯的准确率由训练过的线性分类器的测试准确率来衡量。
RQ1 的答案是肯定的:时间控制可以对对话和文章中的局部文本动态进行建模。
然后,实验了评估时间控制如何生成局部连贯文本 (RQ2) 的文本填充设置。文本填充需要一个模型,让一个缺少句子的不完整文本变得完整。例如,「Patty 很高兴她的朋友们能来。Patty 和她的朋友们玩得很开心。」这里文本填充的挑战是生成一个与左右相邻句子局部连贯的句子。
研究者在 BLEU (Papineni et al. ,2002) ,ROUGE (Lin,2004) ,BLEURT (Sellam et al. ,2020)和 BERTScore (Zhang et al. ,2019)上评估了生成句和 ground truth 填充句之间的语篇连贯性,如表 2 和表 17 所示。
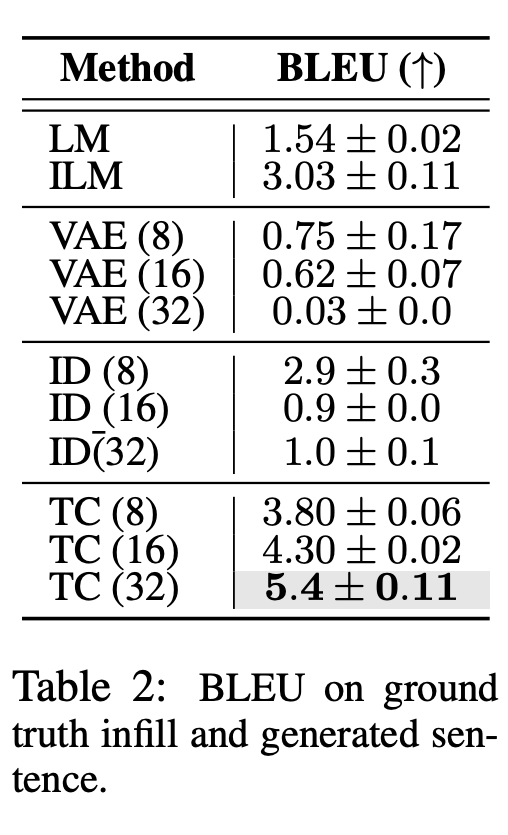
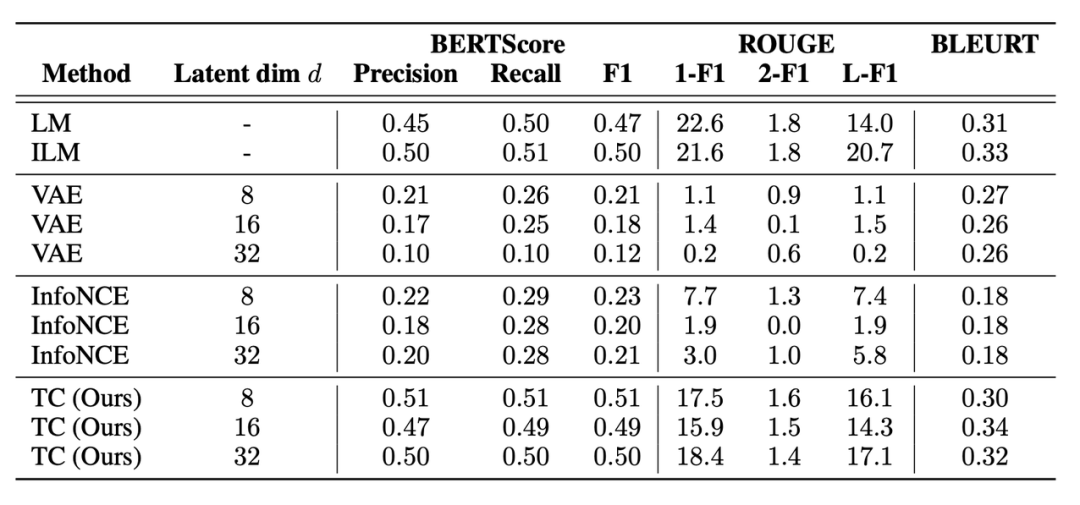
此外还包括人类作为补充句子的生成结果连贯程度的评估。参与者被要求对 ILM、LM 和 Time Control 生成的填充句子进行 1-5 的评分(从不合理到非常合理)。

RQ2 的答案是:由于明确了潜在动态,时间控制可以生成局部连贯的文本。
通过评估这些方法是否模拟了 Wikisection 上的文档结构,研究者评估了时间控制对全局文本动态 (RQ3) 建模的效果。他们检查了生成的区段长度是否与数据集中的平均长度匹配。Wikisection 的每份文档都包含一个城市的摘要、历史、地理和人口部分。
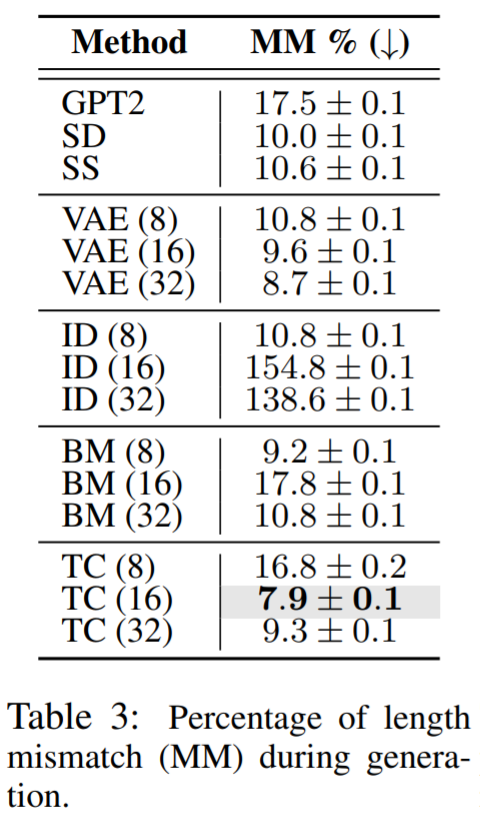
评估结果肯定了时间控制对于建模全局文本动态的重要性,例如匹配文档结构,这回答了 RQ3。
在省略 EOS token 的情况下,研究者评估了时间控制生成全局连贯文本 (RQ4) 的效果,称之为强制长文本生成设置,因为模型必须在生成时外推到其自然的终点以外。作为参考,1000 个 token 要比一般的 Wikisection 文档(最长的文本域)长 50% 。在这项任务上,本文提出的方法也获得了更好的表现。
总结来说,时间控制提高了文本填充和话语连贯性任务的性能,并在排序和文本长度一致性为长文本生成保留了文本结构,证明了本文提出的方法能够生成更多局部和全局连贯的文本。团队认为,时间控制还可以扩展到具有顺序数据的其他领域,例如视频或音频,或者在没有已知固定起点和终点的情况下处理任意桥接过程。
更多详情可参考原论文。

























