













大家好,我是Tom哥
5G 时代,运营商网络不断提速,成本越来越低,流量越来越便宜。
给 互联网、物联网、互联网+ 各个行业的高速发展创造了非常好的有利条件,同时也产生了海量数据。
如何做好数据分析,计算,提取有价值信息,大数据技术一直是一个热门赛道。
今天我们就对 Hadoop、Hive、Spark 做下分析对比。
Hadoop
Hadoop 称为大数据技术的基石。
由两部分组成,分布式存储(HDFS)和分布式计算(MapReduce)。
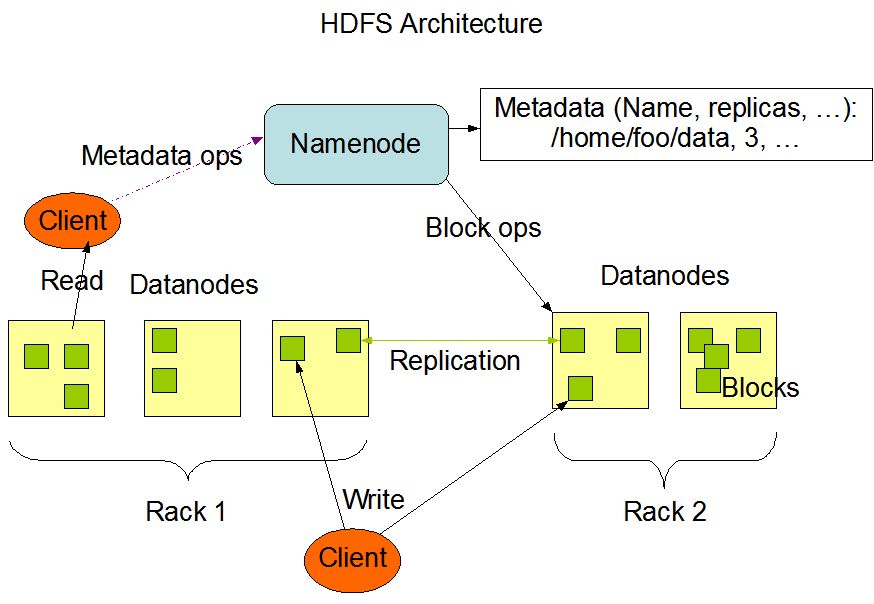
HDFS 有两个关键组件:
1、NameNode
负责分布式文件系统的元数据(MetaData)管理,如:文件路径名、数据块的 ID 以及存储位置等信息,相当于操作系统中文件分配表(FAT)的角色。
2、DataNode
负责文件数据的存储和读写操作,HDFS 将文件数据分割成若干数据块(Block),每个 DataNode 存储一部分数据块,从而将一个大文件分割存储在整个 HDFS 集群中。
HDFS的高可用设计:数据存储故障容错、磁盘故障容错、DataNode故障容错、NameNode故障容错。
MapReduce 既是一个编程模型,又是一个计算框架。
包含 Map 和 Reduce 两个过程。
计算过程:
- 首先,将输入的内容转换为 < key , Value > 健值对。
- 将相同的 key 集中在一起,形成 < key,List >。
- 最后,将 List 进行归约合并,输出零或多个 < key , Value >。
public void map(Object key, Text value, Context context)
public void reduce(Text key, Iterable<IntWritable> values, Context context ) - 1.
- 2.
转换成代码落地,分别继承 Mapper 和 Reducer 两个类,然后实现里面的两个默认方法,完成业务逻辑。
所有的复杂的业务全部抽象成 Map 和 Reduce 这两个函数计算,当我们面对复杂的具体业务功能通过 Map 和 Reduce 的多次 自由组合,从而实现业务逻辑。
当然,上面的程序在分布式系统中需要引擎调度,该计算框架也称为 MapReduce。
所以,MapReduce 即是 编程模型,MapReduce 代码程序,也是调度分布式计算的引擎框架。
亮点:
- 数据不出门,算法满天跑。每次任务计算,只需要将对应的任务分发到数据所在的服务器上。避免大数据传输的性能损耗。
- 引入 shuffle 机制,将不同服务器的中间计算结果,通过 Partitioner 用 Key 的哈希值对 Reduce 任务数取模,分组路由到 Reduce 服务器上,进行合并计算。
- 框架自带调度引擎。
不足:
- 每次 Map 任务的计算结果都会写入到本地文件系统,速度会慢些。
- 如果实现复杂的业务逻辑,通过 Map -- Reduce 的多次自由组合,开发成本还是有些大。
Tom哥有话说:
Hadoop 作为大数据框架的鼻祖,在海量数据处理方面确实让我们眼前一亮。
但是完美总是需要持续打磨,Hadoop在处理速度、开发门槛等方面有很多不足。慢慢的随着达尔文进化论,市场上开始百花齐放,各种优秀的大数据框架陆续出现。
Hive
大数据时代,数据分析师岗位非常多,这帮人擅长通过 SQL 来进行数据分析和统计。
SQL 方式操控数据简单、直接,比起 MapReduce代码 ,大大降低了编程难度,提升了开发效率。

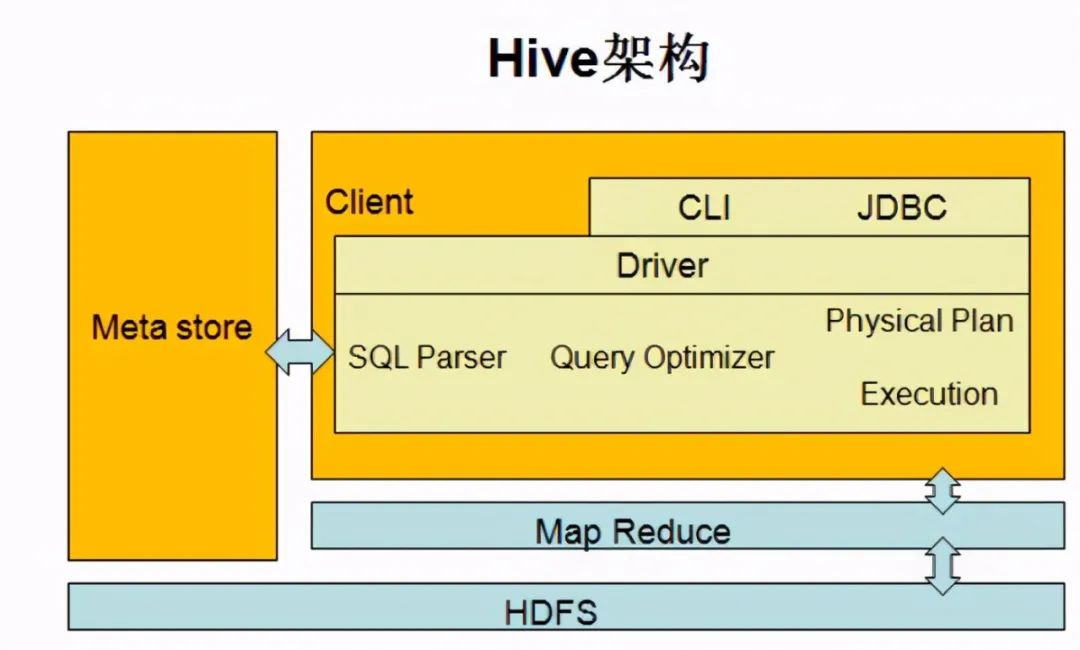
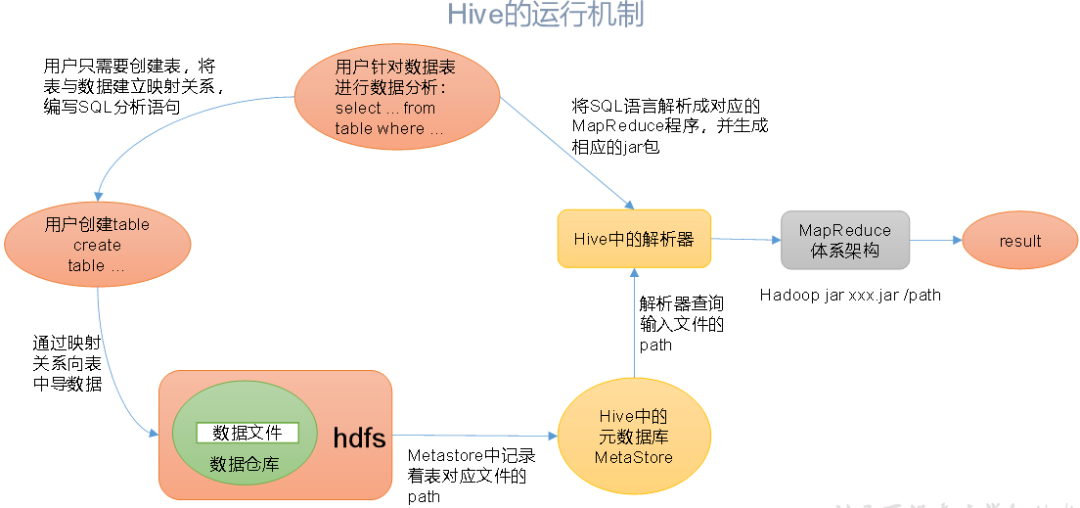
Hive 通过执行引擎 Driver 将数据表的信息记录在 Metastore 元数据组件中(包含表名、字段名、字段类型、关联的HDFS文件路径)。
运行过程:
- 通过 Hive 的命令行工具或 JDBC,提交 SQL 语句。
- Driver 将语句提交给编译器,进行 SQL解析、语法分析、语法优化等一系列操作,生成函数的 DAG(有向无环图)。
- 根据执行计划,生成一个 MapReduce 任务作业。
- 最后,提交给 Hadoop MapReduce 计算框架处理。
Tom哥有话说:
Hive 可以直白理解为 Hadoop 的 API 包装,采用 SQL 语法实现业务,底层依然 Map Reduce 引擎来执行,但是转换逻辑被 Hive 作为通用模块实现掉了。
我们发现 Hive 本质上并没有什么技术创新,只是将 数据库 和 MapReduce 两者有效结合,但是却给上层的程序员提供了极大的开发便利。
虽然,在性能方面没有质的飞跃,但是由于开发门槛大大降低,在离线批处理占有非常大市场。
Spark
无论是 MapReduce 还是 Hive 在执行速度上其实是很慢的,但是没有比较就没有伤害,直到 Spark 框架的横空出现,人们的意识也发生了重大改变。
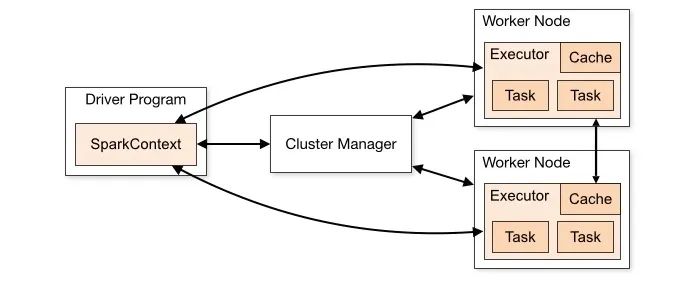
Spark 将大数据集合抽象成一个 RDD 对象,然后提供了 转换、动作 两大类算子函数,对RDD进行处理,并得到一个新的 RDD,然后继续后续迭代计算,像 Stream 流一样依次执行,直到任务结束。内部也是采用分片处理,每个分片都会分配一个执行线程。
传统的面向对象编程思路:
将一个数据集合作为入参传递给一个函数方法,经过运算,返回一个新的数据集合。然后将这个新的数据集合作为入参传递给下一个函数方法,直到最后计算完成,输出结果。
如果这个数据集有 1亿条,总共两次函数运算,每一个函数运算,都要遍历1亿次,那么总的时间复杂度是 2亿次。
函数式编程思路:
将数据集合转换成流,每个元素依次经过上面两个函数处理,最后得到一个新的结果集合。整个流程只需要遍历一趟,那么总的时间复杂度是 1亿次。
面对海量的数据以及较多的算子组合运算,这种性能累计提升还是非常明显的。
Spark 的一些亮点:
引入惰性计算,只有当开发者调用了 Actions 算子,之前的转换算子才会执行。
以 shuffle 为边界,将 DAG 切分多个阶段,一个阶段里的多个算子(如:textFile、flatMap、map)可以合并成一个任务,然后采用上面的函数编程思想处理数据分片。
使用 内存 存储中间计算结果:
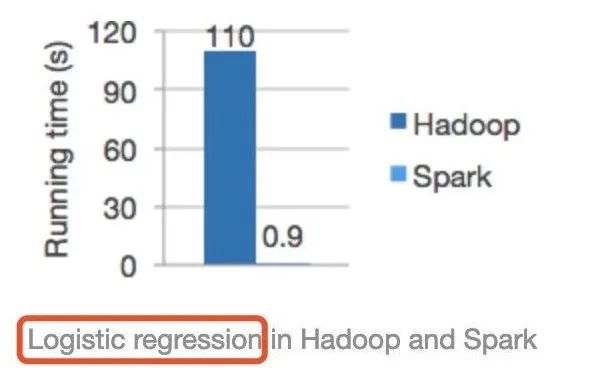
借助这些亮点优化,Spark 比 MapReduce 运行速度快很多。上图是逻辑回归机器学习算法的运行时间比较 ,Spark 比 MapReduce 快 100 多倍。
当然Spark 为了保留 Hive 的SQL优势,也推出了 Spark SQL,将 SQL 语句解析成 Spark 的执行计划,在 Spark 上执行。
Tom哥有话说:
Spark 像个孙猴子一样横空出世,也是有先天条件的。Hadoop 早期受内存容量和成本制约很大,但随着科技进步,到了Spark时期内存条件已经具备,架构思路也可以直接按照内存的玩法标准来设计。
有时候就是这样,赶上一个好时候,猪都能飞上天。要想成功,天时地利人和,缺一不可。



















