













译者 | 陈峻
审校 | 孙淑娟
Java 8 的并行流是改进大型集合处理的直接方法。本文在此基础上介绍了三种不同的改进算法,并通过比较,给出了能够带来更优越性能的方法。
和许多其他编程语言类似,Java拥有一组数据结构对象,可以被用来表示某些单个单元,及其可以执行的一组操作。从处理大数据量的计算程序来看,其典型操作会涉及到对每个对象进行转换等各种集合。在本文中,我们将借用ETL(提取、转换和加载)的基本概念,将提取/捕获到的数据从原来的形式,转换为指定的形式,以便将其存放到另一个数据库中。当然,我们会在此讲述数据库元素的转换、抽象操作的概念,以便你更好地理解集合处理的本质。
1.基础知识
从Java 1.2开始,我们便主要依赖于作为集合层级结构的java.util.Collection根接口。而在Java 7发布之前,能够显著提升大型集合的处理性能的唯一方法是:并行化操作。不过,随着Java 8的出现,新的java.util.stream包提供了支持元素流进行功能性样式(functional-style)操作的Stream API。Stream API通过被集成到Collections API中,可以对集合进行诸如顺序或并行的map-reduce转换等批量操作。
从那时起,Java便提供了一种原生的方式,来尝试着改进应用于集合的转换操作的并行化性能。之所以被称为是一种“尝试”的策略,其原因在于它只是简单地使用了并行流式操作,并不能保证一定会有更好的性能。毕竟其他潜在的因素也可能产生影响。尽管如此,并行流提供了寻求改进处理性能的一个思路和起点。
下面,我将对一个大型的Java集合采用简单的转换操作,比较原生的顺序和并行处理、以及三种基于其他算法的并行流策略,在性能上的优劣。
2.转换操作
针对转换操作,我们定义了一个功能性的接口。如下面的代码段所示,你只需要将一个 R 类型的元素,应用到变换操作上,便可返回一个 S 类型的变换对象。
Java
@FunctionalInterface
public interface ElementConverter<R, S> {
S apply(R param);
}
该操作旨在将一个作为参数提供的字符串,转换为大写字母的形式。下面的两个代码段分别创建了两个ElementConverter接口的实现。其中的一个是将某个字符串转换为大写字符串:
Java
public class UpperCaseConverter implements ElementConverter<String, String> {
@Override
public String apply(String param) {
return param.toUpperCase();
}
}
另一个是对集合执行相同的操作:
Java
public class CollectionUpperCaseConverter implements ElementConverter<List<String>, List<String>> {
@Override
public List<String> apply(List<String> param) {
return param.stream().map(String::toUpperCase).collect(Collectors.toList());
}
}
除了上述辅助方法,我们还为每个并行处理的策略,编写了一个专用的方法,来实现AsynchronousExecutor类。具体请参见如下代码段:
Java
public class AsynchronousExecutor<T, E> {
private static final Integer MINUTES_WAITING_THREADS = 1;
private Integer numThreads;
private ExecutorService executor;
private List<E> outputList;
public AsynchronousExecutor(int threads) {
this.numThreads = threads;
this.executor = Executors.newFixedThreadPool(this.numThreads);
this.outputList = new ArrayList<>();
}
// Methods for each parallel processing strategy
public void shutdown() {
this.executor.shutdown();
try {
this.executor.awaitTermination(MINUTES_WAITING_THREADS, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}
3.子列表分区
首个用于增强大型集合转换操作的并行策略是,基于java.util.AbstractList的扩展。简单地说,CollectionPartitioner会将源集合拆分成多个子列表。每个子列表的大小是根据处理过程中使用到的线程数计算的。
首先,我们通过将获取源集合大小除以线程数,来计算出子列表块的大小。然后,每个子列表会根据索引对(frommindex, toIndex),从源集合中复制出来,并完成数值的同步计算。其对应的代码段如下所示:
Java
fromIndex = thread id + chunk size
toIndex = MIN(fromIndex + chunk size, source collection size)
Java
public final class CollectionPartitioner<T> extends AbstractList<List<T>> {
private final List<T> list;
private final int chunkSize;
public CollectionPartitioner(List<T> list, int numThreads) {
this.list = list;
this.chunkSize = (list.size() % numThreads == 0) ?
(list.size() / numThreads) : (list.size() / numThreads) + 1;
}
@Override
public synchronized List<T> get(int index) {
var fromIndex = index * chunkSize;
var toIndex = Math.min(fromIndex + chunkSize, list.size());
if (fromIndex > toIndex) {
return Collections.emptyList(); // Index out of allowed interval
}
return this.list.subList(fromIndex, toIndex);
}
@Override
public int size() {
return (int) Math.ceil((double) list.size() / (double) chunkSize);
}
}
一旦每个线程把变换操作应用到其各自的子列表中的所有对象处,它就必须将修改后的对象同步、并添加到输出列表中。下面的代码段展示了这些步骤都是由AsynchronousExecutor类的特定方法完成的。
Java
public class AsynchronousExecutor<T, E> {
public void processSublistPartition(List<T> inputList, ElementConverter<List<T>, List<E>> converter) {
var partitioner = new CollectionPartitioner<T>(inputList, numThreads);
IntStream.range(0, numThreads).forEach(t -> this.executor.execute(() -> {
var thOutput = converter.apply(partitioner.get(t));
if (Objects.nonNull(thOutput) && !thOutput.isEmpty()) {
synchronized (this.outputList) {
this.outputList.addAll(thOutput);
}
}
}));
}
}
4.浅分区
第二种并行处理策略采用的是浅拷贝(shallow copy)的概念。事实上,各个进程中涉及到的线程,并不会收到从源集合复制过来的子列表。相反,每个线程都会使用子列表分区策略的相同数值,去计算其各自的索引对(fromIndex,toIndex),并直接对源集合进行操作。不过,这都是基于源集合不能被修改的前提。也就是说,线程会根据源集合自己的切片去读取各种对象,并将新转换的对象存储在与原始集合大小相同的新集合中。
值得注意的是,该策略在变换操作期间并没有任何同步执行点。也就是说,所有线程都是完全独立地执行着各自的任务。当然,我们可以使用至少两种不同的方法,来组装待输出的集合。
5.基于列表的浅分区
此方法在处理集合之前,会创建一个由各种默认元素组成的新列表。各种线程可以访问新的列表中,由索引对(frommindex, toIndex)分隔的不相交切片(Disjoint slice)。它们存储着从源集合中读取到的、由相应切片生成的每个新对象。这种方法会使用一个新的专用类--AsynchronousExecutor。请参见如下代码段:
Java
public class AsynchronousExecutor<T, E> {
public void processShallowPartitionList(List<T> inputList, ElementConverter<T, E> converter) {
var chunkSize = (inputList.size() % this.numThreads == 0) ?
(inputList.size() / this.numThreads) : (inputList.size() / this.numThreads) + 1;
this.outputList = new ArrayList<>(Collections.nCopies(inputList.size(), null));
IntStream.range(0, numThreads).forEach(t -> this.executor.execute(() -> {
var fromIndex = t * chunkSize;
var toIndex = Math.min(fromIndex + chunkSize, inputList.size());
if (fromIndex > toIndex) {
fromIndex = toIndex;
}
IntStream.range(fromIndex, toIndex)
.forEach(i -> this.outputList.set(i, converter.apply(inputList.get(i))));
}));
}
}
6.基于数组的浅分区
该方法与前一种方法的不同之处在于,各个线程使用的是数组、而不是列表,来存储转换后的新对象。毕竟,线程在完成了其操作后,数组就会被转换为输出列表。同样地,新的方法会根据该策略,被添加到AsynchronousExecutor类中。请参见如下代码段:
Java
public class AsynchronousExecutor<T, E> {
public void processShallowPartitionArray(List<T> inputList, ElementConverter<T, E> converter)
var chunkSize = (inputList.size() % this.numThreads == 0) ?
(inputList.size() / this.numThreads) : (inputList.size() / this.numThreads) + 1;
Object[] outputArr = new Object[inputList.size()];
IntStream.range(0, numThreads).forEach(t -> this.executor.execute(() -> {
var fromIndex = t * chunkSize;
var toIndex = Math.min(fromIndex + chunkSize, inputList.size());
if (fromIndex > toIndex) {
fromIndex = toIndex;
}
IntStream.range(fromIndex, toIndex)
.forEach(i -> outputArr[i] = converter.apply(inputList.get(i)));
}));
this.shutdown();
this.outputList = (List<E>) Arrays.asList(outputArr);
}
}
7.策略比较
我们规定,每个策略的CPU时间都是通过取5次执行的平均值来进行计算。而每次执行都会生成1百万和1千万个随机字符串的对象集合。上述代码被跑在Ubuntu 20.04 LTS 64位的操作系统上。该系统的主机具有12 GB的RAM和3.40 GHz的Intel Xeon E3-1240 V3 CPU。该CPU为4内核双线程。其结果如下图所示:
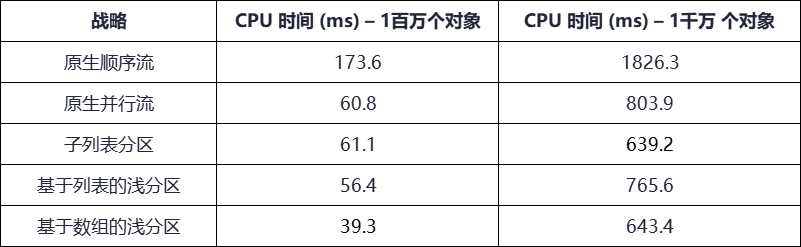
我们可以看到,第一行结果是由原生顺序流实现了最高的CPU时间。实际上,它已经被添加到了建立初始化性能参数的测试中。接着,我们简单地将策略更改为原生并行流,1百万个对象的集合提升了约34.4%,而1千万个对象集合也提升了44%。下面,原生并行流策略的性能将被作为其他三种策略的参考标准。
如上图所示,对于1百万个对象的集合而言,我们并没有观察到基于列表的浅分区策略在CPU时间上的减少(只有约7%的细微改进),而子列表分区策略的性能则更差。那么,亮点便是基于数组的浅分区。它大幅减少了约35.4%的CPU时间。
另一方面,对于1千万个对象的集合而言,所有三种策略都优于并行流时间。其中,子列表分区实现了最佳的性能改进,它将CPU的执行时间减少了约20.5%。当然,基于阵列的浅分区策略也有相似的性能提升,它将CPU时间提高了近20%。
由于基于数组的浅分区策略在两种集合大小下都表现出了不俗的性能,因此我们有必要对其“加速比”进行分析。此处的“加速比”是通过T(1)/T(p)的比率计算出来的。其中T表示有p个线程正在运行的程序所用到的CPU时间。而T(1)对应的是我们顺序执行程序所需要的时间。下面便是我为该策略绘制线程数与加速比的结果图表。
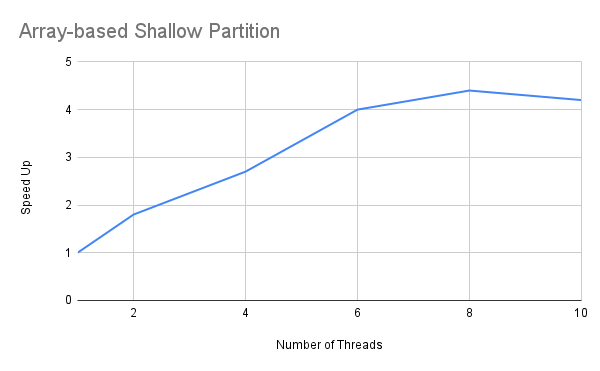
由于上述所有测试都是在4核双线程的主机上进行的,我们曾预见在八线程上,该策略的加速比会更加明显。不过由上述图表可知,该算法最大加速比的峰值为4.4倍。同样,1千万个对象的集合也达到了非常相似的加速比。在此,我就没必要重新绘制图表了。这就意味着该策略不会根据用到的线程数,线性地提高其整体性能。
8.小结
虽然原生顺序流的使用,为我们提供了一个可靠的初始参考,来加速大型集合的处理。但是作为替代性尝试的并行化策略,则能够实现更好的性能。而上文介绍的三种不同算法,能够为你带来更优越的并行流性能。你可以在GitHub存储库获得其完整的源代码。它是一个Maven项目,其对应的特定模块为dzone-async-exec。
原文链接:https://dzone.com/articles/speeding-up-large-collections-processing-in-java
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。


















