













无论是数据通讯技术的演进、互联网技术的革新、还是视觉呈现的升级,都是得益于更强大的计算、更大容量更安全的存储以及更高效的网络。 英伟达网络结合客户需求,提出了基于InfiniBand网络为基础的集群架构方案,不仅可以提供更高带宽的网络服务,同时也降低了网络传输负载对计算资源的消耗,降低了延时,又完美地将HPC与数据中心融合,构建了元宇宙发展的基石。
近日,在由51CTO主办的MetaCon元宇宙技术大会《人机交互与高性能网络》分会场上,英伟达网络高级产品经理陈龙老师聚焦Meta集群的高性能网络方案做了整体介绍,为元宇宙技术爱好者深度揭秘了什么是InfiniBand以及InfiniBand加速计算和存储等精彩内容!
一、InfiniBand网络集群架构产生的背景
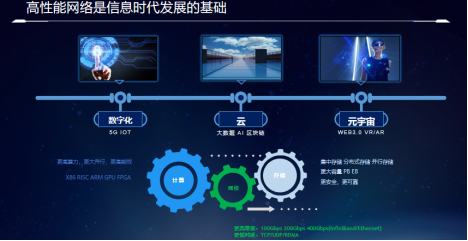
众所周知,我们现在是处于一个信息化的时代,一切信息都是以数字化为基础的。5G、IoT的普及为我们构建了数以亿万的终端,打开了数字化的终端。每时每刻数以亿计的数据源源不断地生成,汇入云端,而大数据、AI、区块链为代表的技术可以在数据中心构建的云端高效的数据存储同时,不断地分析、提炼数据,挖掘潜在的数据,反馈给终端,服务社会。
近年来,随着web3.0和VR、AR技术的不断完善,互联网的边界不断被打破,在Meta的带领下,元宇宙的时代正在悄然来临。技术革命在丰富我们生活的同时,支持信息化时代的基石仍然没有改变,计算、存储和网络仍是其技术发展的主旋律。
无论是从2G到5G的数据通讯技术的演进,还是web1.0、web2.0、web3.0互联网技术的不断革新,还有视觉呈现从图片到视频到VR、AR的过渡,支持其发展的无非是以下三点。
第 一,要更强大的计算:1.更多的核心做并行计算;2.异构计算,突破X86 CPU架构的限制。RISC-V、ARM、GPU、FPGA等计算单元的出现,满足专业计算的需求。
第二,容量更大、更安全的存储。容量从TB到EB级的存储,存储架构也更加丰富,集中,分布式存储、并行存储满足大容量、高性能数据存储的需求。
第三,作为数据、计算和存储的桥梁,网络在计算存储演进的同时,自身的发展也极其迅速,从100G、200G、400G不断发展,同时也从原有的TCP、UDP的网络连接向RDMA扩展,不断地提升网络传输的性能。
另一方面,作为数据服务的提供商,为了应对云化部署的大潮,纷纷提出了云原生的概念,从应用的角度重新设计架构,让服务可以变得更加高效。与此同时,设计中心也在面临着另外一项变革,云化不仅在传统的数据中心的业务内发生改变,也对HPC类的需求发生实质性的影响,越来越多的HPC的应用类似像仿真建模、图形渲染、AI训练、数字孪生都部署在云端,满足各行各业发展的需求。
在此背景之下,英伟达网络结合客户需求提出基于InfiniBand网络为基础的集群架构方案,高效能地来完成客户需求。相对于传统的网络方案,InfiniBand不仅提出了更高带宽的网络服务,也降低了网络传输负载对计算资源的消耗,降低了延时,也完美地将HPC与数据中心融合在一起,构建了元宇宙发展的基石。
二、Meta集群到底是什么?
元宇宙旗舰公司Meta和图形图像AI领域公司英伟达,共同高调发布了基于DGX SuperPOD架构的Meta专用集群架构,用于实现Meta抢占元宇宙时代技术制高点的主要武器,负责AI算法、数据计算场景的应用。这次公布已经上线的一期集群规模是搭载了6080块的A100的760台DGX服务器,所有GPU采用了200Gbps的InfiniBand HDR网卡,实现了高效的数据传输,整体集群性能达到1.89亿TF32精度的计算能力。
如此之高的计算,使得Meta成为AI领域内业界性能最高的集群,而如此规模之大的集群仅仅是Meta构建元宇宙时代霸主雄心的开始,后期的二期扩建将达到16000块GPU,整体集群的能力将高达5亿,存储的数据带宽将达到16TB。
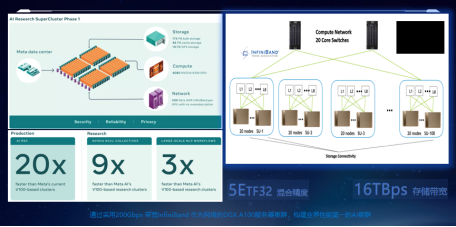
再来看一下Meta公布的集群架构图。这么庞大的集群,将采用20台800口的InfiniBand柜式交换机作为网络的骨干层,下面连接100个Pod,每个Pod内部署8台40口InfiniBand HDR的交换机,实现全网络无阻塞的CLOS架构,从而达到相比之前Facebook AI集群20倍性能计算的提升、9倍NCCL并行计算的能力、3倍AI模型建模的参数训练。除此之外,集群还部署了10PB的NFS的集中数据存储,46PB的块存储,提供内存数据恢复,175PB的块存储,而这一切都是以InfiniBand的网络实现数据传输的快速传输解决方案。

是什么原因让InfiniBand成为Meta集群的首要方案呢?从InfiniBand的网络发展历程来看,网卡会跟以太卡有所不同,其实我们现在熟知的以太网络的网卡的很多设计都是从InfiniBand这里借鉴过来的。从图上可以看出,早在20年前InfiniBand就发展出了万兆卡,2008年已经演进到了40Gbps,随后平均每三年左右就会发展出新的产品。今年已经量产了400G的NDL网卡,所以这InfiniBand成为GPU集群的首选方案,代际演进也将会变成两年一代,2023年英伟达会发布800G的XDR网卡,2025年将发布1.6TB的GDL网卡,为消除数据传输之间的鸿沟奠定了坚实的基础。
三、InfiniBand 网络架构的奥秘
从InfiniBand解决方案的全景图中,我们会看到有网卡、交换机、线缆、网络端到端的硬件设备,还有DPU、网关设备,从而不仅构建了完备的数据中心的网络设备,而且还打通了与广域网同城应用的节点,实现了硬件完备的网络传输解决方案,有两点值得一提:

一是盒式交换机,我们提供的是1U 40口的200G交换机,相比同级别竞争对手提升了20%的交换能力。而且针对像Meta这样的大型客户,单独提供了业界唯一20U超大型的柜式交换机,实现高达800个端口的超大规模的交换。
二是InfiniBand提供了业界新概念的DPU网卡,实现在业务负载上的卸载和隔离,做到了端到端的网络管理与维护,最大化兼容老旧设备,可以让设备无缝连接到高性能的InfiniBand的网络。而这些硬件的基础之上,我们还开创性的构建了网络计算这一新兴概念,实现在交换机上做计算,同时结合SHIELD、SHARP、GPU RDMADirect等功能之后,使得我们的网络更加的智能和高效。
四、InfiniBand 是如何实现加速计算的?
讲到计算,不太了解RDMA的应用的人们可能会疑惑,一个负责传输的网络是如何实现对计算的加速呢?问题就在于真实的数据传输不仅仅是网络设备的事情,以我们熟知的TCP报文转发为例,大量的数据、协议报文处理都需要CPU的深度介入,类似像报文的封装、转发、上下文切换,都需要大量的CPU的开销才能实现。在这样的机制下,10G带宽以下的数据流量不大的情况下,CPU的资源占用不太明显。但是在流量上升到100G以上的时候,我们就会发现整个CPU的开销就会显著增加。在某些场景下,CPU的消耗会达到20多个核,来实现100G的数据传输。因此,在普遍服务器进入到100G传输的背景下,消耗掉传输的CPU的资源的代价就是在帮助计算加速。
RDMA就是这样一种技术,在通信两端的服务器内实现数据的直接传输,整个数据的操作CPU是完全不会介入,不仅降低了CPU的开销,而且也使得CPU不会成为数据传输的瓶颈,使得我们的数据传输可以向200G、400G乃至1TB的数据的演进。
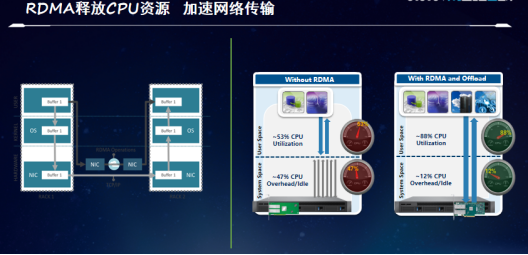
从图上我们可以看出,对于一个普通的服务器当没有使用RDMA技术的时候,由于CPU要负责大量的协议的开销处理,使得有47%的资源工作在Kernel态下,而只有大概50%的资源用于程序的计算,限制了整个服务器的应用扩展。当如果我们使用RDMA技术之后,使得大量的消耗CPU资源的数据面完全被卸载在网卡上,我们就可以能够控制在Kernel的资源在CPU的12%,将用户态的CPU资源实现翻倍。这样不仅将整个传输的性能提高,同时腾出来的CPU的资源又可以能够部署更多的计算的负载,实现了整个带宽的提升的同时,又增加了业务的部署,提高了整个服务器的利用效率。
另外,如何对GPU实现加速呢?
现在随着AI技术的快速普及,GPU的应用也变得越来越重要,而且在GPU上由于有成千上万的核要做计算,对数据传输的需求就会更大。在CPU服务器正在普遍向100G过渡的时候,GPU的服务器200G的网络已经成为标配,并且我们正在向400G乃至800G的网络过渡。因此GPU对网络传输的需求会更为迫切。
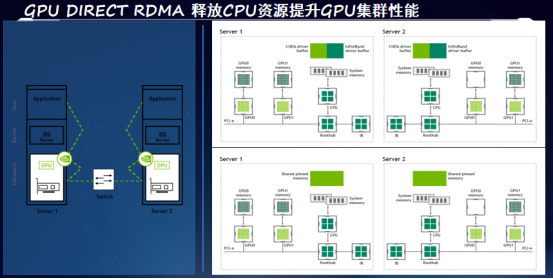
解决方案除了需要像RDMA这样的技术之外,还需要进一步扩展在网络数据面上的制约,让GPU全速运行。在标准的GPU服务器的架构上,我们知道GPU是以PCIe的方式和CPU进行互联的,在这种架构下就决定了GPU在服务器数据传输时,所有的数据都要经过CPU。
从上图能够了解到,如果是这样的这种传输方式,跨服务器之间的GPU的数据传输需要实现五步的数据拷贝。首先,服务器内部的GPU的显存要把自己的数据通过PCIe总线传输到本地的CPU的内存上,然后再由本地的CPU内存实现数据拷贝,拷贝到专门的RDMA传输的管道的内存上。然后再通过RDMA的技术,使得这个数据从本台服务器的内存传输到另外一台服务器的内存,之后再由另一台服务器的内存实现拷贝,拷贝到和本地GPU显存交互的内存上。最后再由这部分的数据拷贝到GPU的显存上。五步的数据拷贝,我们会看到这个操作会变得非常的复杂,而且中间的CPU内存等等都会成为数据转发的瓶颈。
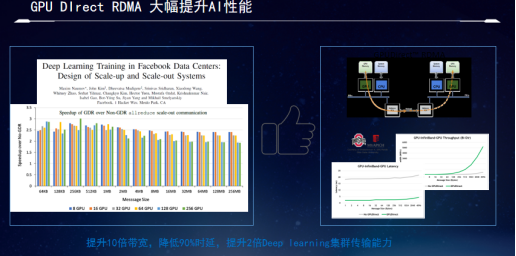
要解决这个问题,需要GPU Direct RDMA的技术,该技术可以实现让GPU和网卡直接bypass掉CPU,实现网卡和GPU之间的数据直连。这样只需要一步的数据拷贝,就可以让处于发送端GPU的数据从它的显存中直接一步跳到目的端的GPU的显存内,实现数据的快速拷贝。简化了流程,降低了时延,实现对GPU应用的加速的效果。
使用了GPU Direct RDMA技术之后,其对AI集群可以实现90%的时延的节省,4K以上报文大小的message传输的I/O带宽实现了十倍的性能的提升。同时在这样网络性能大幅提升的前提下,对AI集群的并行计算的任务实现了一倍以上的性能改进的效果,大幅提高了AI集群的效能,改善了投入产出比。也正是这个原因,导致了Meta在元宇宙时代坚定地要使用InfiniBand的网络作为业界最大规模AI集群的网络方案,从而证实了InfiniBand的网络加速GPU计算的效果。
以上我们从网卡的角度上阐述了InfiniBand如何机遇性的加速CPU和GPU计算,当然,那作为网络中最为关键的交换机,InfiniBand是如何加速网络计算的?这里需要提到InfiniBand的应用SHARP了。
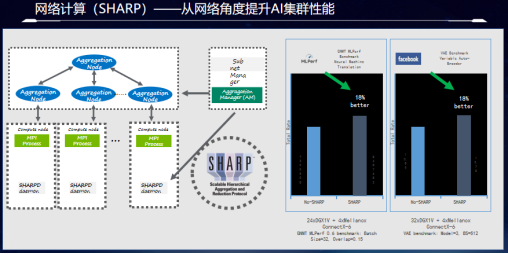
我们知道AI训练过程中有着大量的AllReduce的操作,直白地讲,就是负责分布式计算的GPU要同时更新自己的数据到不同的计算GPU上,这样的话在这种框架下就决定了数据要反复地进行网络,保持数据在各个GPU上的同步。并且AllReduce的计算类型无非是求和异或求最值等简单但是计算频繁的操作。我们知道了这样的计算模式之后,就可以设想把交换机变成一个计算节点,将所有的GPU的数据统一汇集到交换机上进行计算,并且统一分发到各个GPU上。这样由于交换机的转发带宽远大于服务器,如此的架构不仅没有数据传输的瓶颈,而且在数据网络中的流转只需要一次就可以完成所有的计算过程,大大简化了计算过程,降低了时延,消除了瓶颈。
从上面的图例可以看出,在几十台DGX的服务器集群规模上使用了网络计算功能之后,整体集群完成训练的任务的性能提升了18%,这就意味着当使用了InfiniBand网络的集群的时候,交换机不仅完成了高性能的数据传输,同时还完成了近两成的计算任务,为客户提高了性能的同时,节省了大量的服务器投入成本。
五、InfiniBand 是如何实现加速存储的?
众所周知,计算和存储是任何集群中最重要的两个组成部分。虽然在一个集群的物理形态下,存储服务器的数量明显少于计算服务器,但从本质上看,从事于存储的服务器其实只是负责数据存储的一小部分。而在广义上的存储,其实遍布了集群中的每一个角落。
在这里,我们按照以下四个维度对这几种常见的存储器件进行归类和排布。
1.数据存储的带宽
2.数据访问的时延
3.存储器件的容量
4.单位容量下存储的成本
不难看出IRAM内存SSD资源池、硬盘资源池和磁带资源池,刚好能够按照对角线进行排布。这就意味着在这样的组成的集群内存储的性价比是最高,配置最为合理的存储方案。
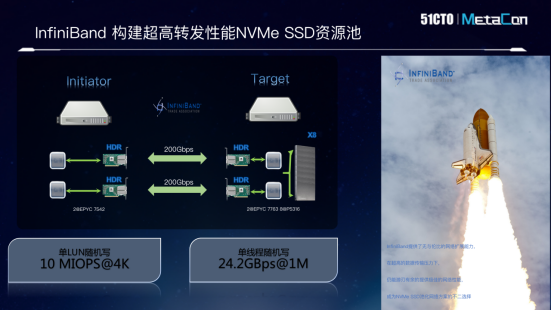
但是如果机械硬盘、固态硬盘以单个器件存在,那存储方案就不能实现对角线的排布。原因其实很简单,以机械硬盘为例,受限于存储带宽的限制,单个硬盘不能够提供更高的I/O、更大的容量,所以分布式存储兴起的时候,通过池化方案,完美地解决了这个问题,使得硬盘落盘的带宽大幅提升,同时容量也变得更大。而今天固态硬盘的兴起,虽然带宽有了一两个数量级的提升,但是相对于内存来说,仍然不够快,同时存储的容量也不够大。所以通过网络方案池化,将成为固态硬盘必然的一个趋势,而此时对网络承担数百G的流量压力。
因此,对于存储,InfiniBand的加速本质上就是通过存储器件的并行之后的池化,实现了数据性能的提升,而实现加速效果的。
通过InfiniBand的网络重新解构集群,将计算单元、存储单元立化成池,用InfiniBand作为整个集群的背板总线,高效地将其互联起来,为软件定义集群奠定了硬件的基础。这样,高性能集群就变成了一台超高性能的服务器,可以根据各种任务的负载特性的不同,灵活配置计算与存储资源,最大限度地满足效率的同时,还能有更高的性能表现。并且在未来集群扩容时,可以根据真实的情况需要,定向扩容所需的资源,提高集群的弹性。而这一切,都需要建立在高可靠、高带宽、低延时的网络上。
要想了解更多元宇宙网络及运算相关内容信息,可查看MetaCon元宇宙技术大会官网,地址:https://metacon.51cto.com/
















