一、阅读目的
目前不管是数仓、Lakehouse、数据湖都把开放数据湖中数据的分析作为当下的一个能力突破点。前面有看过论文“Data lake management: Challenges and opportunities”主要分析数据湖管理领域趋势和挑战,里面有提到google的Goods在元数据管理方面做了不错的工业实践。
二、解决的核心问题(场景/技术)
1、Goods在Google元数据体系的位置
从Google bigquery相关资料可以看出google有一套统一的Data catalog,Goods可以理解是基于这套Data catalog基础服务提供的面向数据湖场景元数据管理的完善能力。另外googole还有一篇论文“Big Metadata: When Metadata is Big Data”则是讲在large scale表的元数据及统计信息管理的创新,也是基于Data catalog的工作,这篇文章的解析可以参考本公众号的“Delta Lake&Hudi很火!Google更是Lakehouse的领跑者”文章。
2、Goods的场景定位
面向数据湖场景避免数据孤岛,需要对数据进行统一的管理,而统一管理的可落地方式就是把元数据统一管理起来。Goods的定位不只做统一元数据服务,而是在元数据服务之上解决元数据上下游的处理,并支持用户高效的从大量数据中找到自己需要的数据集。核心技术难点在于准确发现、大规模存储、提供元数据查询能力。
产生很多dataset的原因是为了快速的使用数据,来驱动他们的竞争优势,但是在存储数据的时候没有进行统一的元数据管理,这样就只能事后进行元数据的管理。不改变原有使用元数据的方式,goods后台执行并采集元数据,并记录和其他dataset之间的血缘关系,从而对外提供高效的元数据查询服务。
三、论文内幕
本文的特点是方向新颖、问题开放,因此行文逻辑和其他论文有一些不同,侧重在问题的定义。主要包括几方面:挑战、数据发现能力、后端存储计算服务、查询服务、相关工作及未来
1、挑战
下面是整体的架构,可以看到goods支持多种数据源的元数据发现、对外提供丰富的数据管理能力。挑战包括下面的:
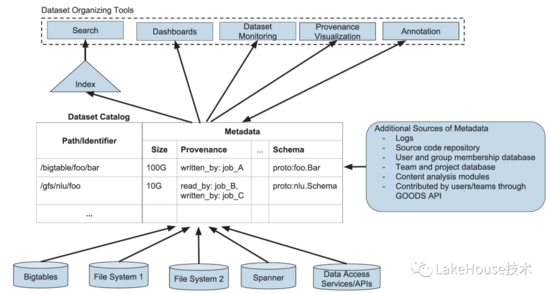
- 海量dataset的元数据发现:支持google所有依赖的26 billion datasets的发现,未来加速需要做dataset关联的元数据推断
- dataset多样性:不同的数据源有不同的类型系统,怎么做一套统一的元数据管理很有挑战。比如bigtable的表需要按照列簇进行表的拆分
- dataset的TTL能力:因为元数据会有版本,全部保留数据量很大,因此需要有TTL的能力
- 后置元数据发现具有一定不确定性:利用dataset自包含的content和dataset本身的隐藏关系
- 计算dataset的重要性:通过比如计算访问频率,主动推理dataset对用户的重要性
- 恢复dataset的语义:dataset的语义对于后续的查询、搜索、描述更有意义
2、Goods数据发现能力
存储的元数据包括从不同系统获取的,goods弥补自由度和统一视图之间的gap,同时具备对多个版本进行聚合处理的能力。
- 元数据
多种方式来爬取元数据并进行组装,获取的这些元数据不仅支持元数据恢复,同时能够满足数据的血缘和流动管理。goods支持构建一个图来描述元信息之间的关系。发现元数据的手段包括:结构化的元数据都是使用pb来存储、读取一部分的数据来识别schema、使用一种算法识别潜在的key关键字、通过注释来消除语义的歧义。
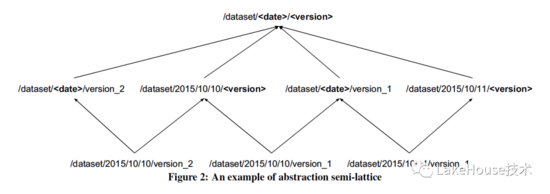
- 对数据进行聚集处理
按照逻辑集群级别进行聚集分类,分类后可以进行一些智能的schema推断和传播,从而减少schema推断的开销。
3、后端存储计算服务
- Catalog storage:有特点的是支持dataset添加描述、以及一些维度的标签信息
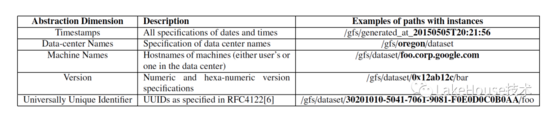
- 批处理作业性能及调度
后台有分析生成元数据的作业、schema识别可能会比较久,做了一些同质元数据比如分区的元数据发现的数据裁剪
- 容错:status的metadata里面存储作业的运行状态,做了执行作业的隔离
- 元数据的垃圾收集:这里主要是有一些TTL
4、查询服务
- Dataset profile pages:支持dataset添加profile级别的配置,为了防止通过压缩来减少使用空间。
- dataset 搜索:这里主要是一些索引相关
- 团队报表:可以监控dataset的属性的变化
5、相关工作
业界工作:Goods的特点是管理海量数据湖的元数据,不需要元数据再创建的时候就进行预处理。与现有比如hive管理元数据,核心的区别就在与数据湖场景,以及事后的元数据发现。
未来工作包括:
- 对dataset的重要性进行标记还没有完全做好
- 区分生产、测试、开发的datasets
- 整合更多的信息来做dataset的推理和管理
- 语义发现和识别
四、学习感悟
goods对于数据湖场景海量的数据集,进行元数据做事后的发现提取、收集、管理、查询。这个和笔者前面在阿里云云原生数据湖分析做的数据湖管理的元数据发现工作基本是一致的,这块工作对于数据湖场景有很大的价值,可以看出goods在数据集血缘、发现的规模、模糊数据集的准确性做了更加体系化的思考。