本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
5月20日消息,阿里巴巴达摩院XR实验室提出新的三维定位地图压缩算法,在保证视觉定位精度的前提下将地图压缩250多倍,使之可存储于手机等端侧设备。相关论文被计算机视觉顶会CVPR 2022收录。据悉,该实验室持续优化自研三维算法,在建图、定位等核心技术模块屡有创新,多个论文成果先后被国际顶会收录。
3D视觉定位是沉浸式互联网的核心技术之一。标准的3D视觉定位方法需提前构建特定场景的3D地图,使之可与相机拍摄的2D图片进行特征点匹配,以计算用户的位置和姿态。但3D地图体量巨大,对存储空间需求较高,无法部署在内存和带宽有限的手机等移动设备。
业界对3D地图的轻量化做了诸多探索,在前人工作基础上,达摩院XR实验室提出新方法SceneSqueezer,将3D地图压缩250倍以上,并使精度损失控制在较小范围,实现模型大小和定位精度的平衡。
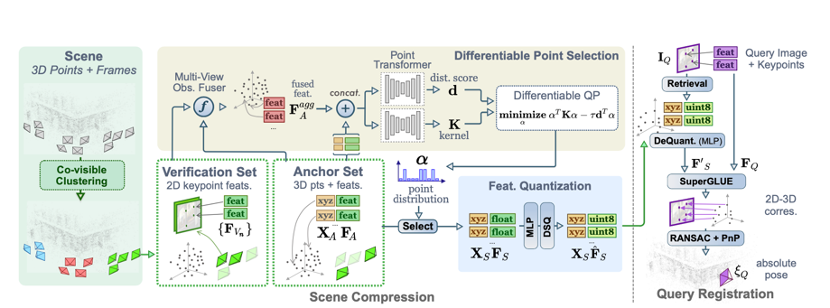
SceneSqueezer采用分层策略对3D地图进行压缩
根据论文SceneSqueezer: Learning to Compress Scene for Camera Relocalization,达摩院团队采用分层策略对3D地图进行压缩,首先利用成对的共可见性信息对数据库图像进行聚类,将场景划分为多个集群分别压缩;其次,基于最终的位姿估计精度,学习选择每个图片的特征点;最后通过特征量化方法压缩特征点的描述。该算法在Cambridge Landmarks、Aachen Day-Night等室外场景数据集上取得了优于既有方法的表现。
达摩院XR实验室高级算法专家董子龙介绍,XR团队自研三维算法体系,在建图、定位等核心技术模块屡有突破,今年已有多篇论文入选顶会。如Quadtree Attention for Vision Transformer提出四叉树注意力机制,提升了基于视觉任务的Transformer模型的性能,入选深度学习顶会ICLR 2022;Neural Window Fully-connected CRFs for Monocular Depth Estimation提出单相机深度估计算法,利用消费级全景相机就可完成深度估计任务,大大降低三维建图成本,文章被CVPR 2022录用。

达摩院XR实验室在杭州文三街开发的“AR打卡”项目
XR实验室是达摩院新近成立的实验室,致力于研究下一代互联网技术,该团队研发的AR、VR技术已落地跨境电商、数字城区等多个场景,如为杭州文三数字生活街区建造1:1还原的三维“数字孪生体”,为杭州奥体中心10万平米地下停车场开发AR导航服务等。