












本文作者magiccao、littleorca,来自携程消息队列团队。目前主要从事消息中间件的开发与弹性架构演进工作,同时对网络/性能优化、应用监控与云原生等领域保持关注。
一、背景
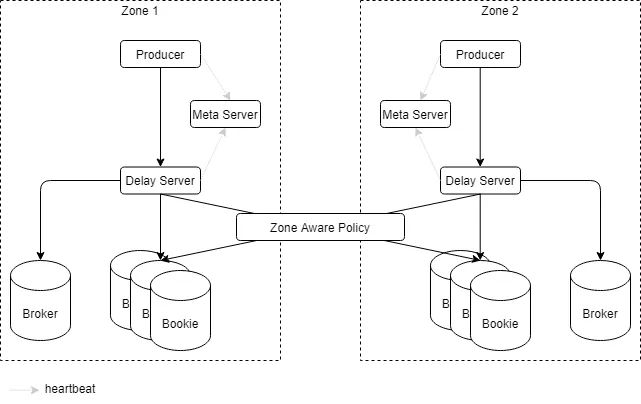
QMQ延迟消息是以服务形式独立存在的一套不局限于消息厂商实现的解决方案,其架构如下图所示。
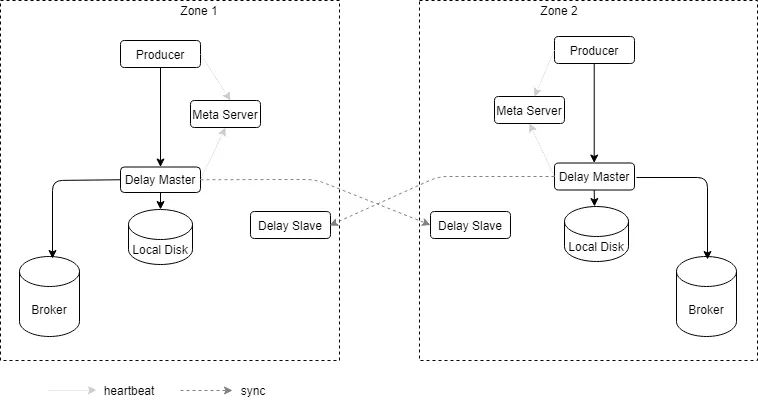
QMQ延迟消息服务架构
延迟消息从生产者投递至延迟服务后,堆积在服务器本地磁盘中。当延迟消息调度时间过期后,延迟服务转发至实时Broker供消费方消费。延迟服务采用主从架构,其中,Zone表示一个可用区(一般可以理解成一个IDC),为了保证单可用区故障后,历史投递的待调度消息正常调度,master和slave会跨可用区部署。
1.1 痛点
此架构主要存在如下几点问题:
- 服务具有状态,无法弹性扩缩容;
- 主节点故障后,需要主从切换(自动或手动);
- 缺少一致性协调器保障数据的一致性。
如果将消息的业务层和存储层分离出来,各自演进协同发展,各自专注在擅长的领域。这样,消息业务层可以做到无状态化,轻松完成容器化改造,具备弹性扩缩容能力;存储层引入分布式文件存储服务,由存储服务来保证高可用与数据一致性。
1.2 分布式文件存储选型
对于存储服务的选型,除了基本的高可用于数据一致性特点外,还有至关重要的一点:高容错与低运维成本特性。分布式系统最大的特点自然是对部分节点故障的容忍能力,毕竟任何硬件或软件故障是不可百分百避免的。因此,高容错与低运维成本将成为我们选型中最为看重的。
2016年由雅虎开源贡献给Apache的Pulsar,因其云原生、低延迟分布式消息队列与流式处理平台的标签,在开源社区引发轰动与追捧。在对其进行相关调研后,发现恰好Pulsar也是消息业务与存储分离的架构,而存储层则是另一个Apache开源基金会的BookKeeper。
二、BookKeeper
BookKeeper作为一款可伸缩、高容错、低延迟的分布式强一致存储服务已被部分公司应用于生产环境部署使用,最佳实践案例包括替代HDFS的namenode、Pulsar的消息存储与消费进度持久化以及对象存储。
2.1 基本架构
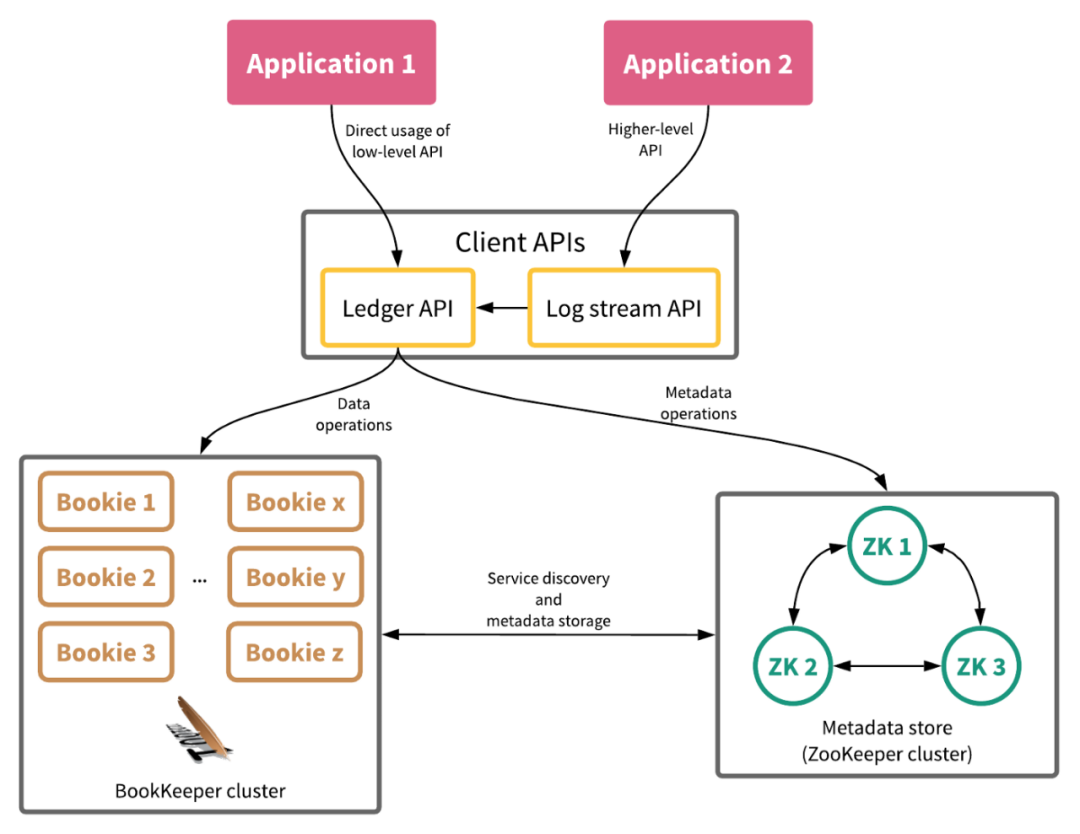
BookKeeper基本架构
- Zookeeper集群用于存储节点发现与元信息存储,提供强一致性保证;
- Bookie存储节点,提供数据的存储服务。写入和读取过程中,Bookie节点间彼此无须通信。Bookie启动时将自身注册到Zookeeper集群,暴露服务;
- Client属于胖客户端类型,负责与Zookeeper集群和BookKeeper集群直接通信,且根据元信息完成多副本的写入,保证数据可重复读。
2.2 基本特性
a)基本概念
- Entry:数据载体的基本单元
- Ledger:entry集合的抽象,类似文件
- Bookie:ledger集合的抽象,物理存储节点
- Ensemble:ledger的bookie集合
b)数据读写
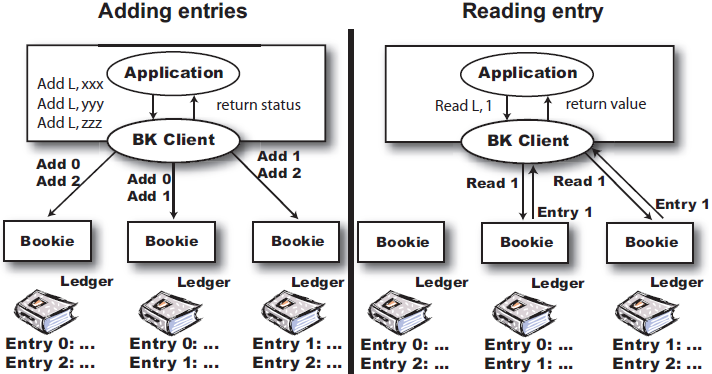
BookKeeper数据读写
bookie客户端通过创建而持有一个ledger后便可以进行entry写入操作,entry以带状方式分布在enemble的bookie中。entry在客户端进行编号,每条entry会根据设置的副本数(Qw)要求判定写入成功与否;
bookie客户端通过打开一个已创建的ledger进行entry读取操作,entry的读取顺序与写入保持一致,默认从第一个副本中读取,读取失败后顺序从下一个副本重试。
c)数据一致性
持有可写ledger的bookie客户端称为Writer,通过分布式锁机制确保一个ledger全局只有一个Writer,Writer的唯一性保证了数据写入一致性。Writer内存中维护一个LAC(Last Add Confirmed),当满足Qw要求后,更新LAC。LAC随下一次请求或定时持久化在bookie副本中,当ledger关闭时,持久化在Metadata Store(zookeeper或etcd)中;
持有可读ledger的bookie客户端称为Reader,一个ledger可以有任意多个Reader。LAC的强一致性保证了不同Reader看到统一的数据视图,亦可重复读,从而保证了数据读取一致性。
d)容错性
典型故障场景:Writer crash或restart、Bookie crash。
Writer故障,ledger可能未关闭,导致LAC未知。通过ledger recover机制,关闭ledger,修复LAC;
Bookie故障,entry写入失败。通过ensemble replace机制,更新一条新的entry路由信息到Metadata Store中,保障了新数据能及时成功写入。历史数据,通过bookie recover机制,满足Qw副本要求,夯实了历史数据读取的可靠性。至于副本所在的所有bookie节点全部故障场景,只能等待修复。
e)负载均衡
新扩容进集群的bookie,当创建新的ledger时,便自动均衡流量。
2.3 同城多中心容灾
上海区域(region)存在多个可用区(az,available zone),各可用两两间网络延迟低于2ms,此种网络架构下,多副本分散在不同的az间是一个可接受的高可用方案。BookKeeper基于Zone感知的ensemble替换策略便是应对此种场景的解决方案。
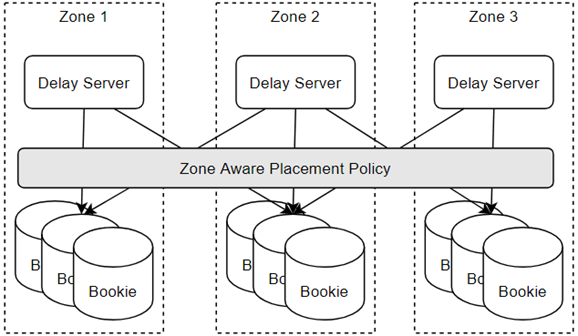
基于Zone感知策略的同城多中心容灾
开启Zone感知策略有两个限制条件:a)E % Qw == 0;b)Qw > minNumOfZones。其中E表示ensemble大小,Qw表示副本数,minNumOfZones表示ensemble中的最小zone数目。
譬如下面的例子:
minNumOfZones = 2
desiredNumZones = 3
E = 6
Qw = 3
[z1, z2, z3, z1, z2, z3]
故障前,每条数据具有三副本,且分布在三个可用区中;当z1故障后,将以满足minNumOfZones限制生成新的ensemble:[z1, z2, z3, z1, z2, z3] -> [z3, z2, z3, z3, z2, z3]。显然对于三副本的每条数据仍将分布在两个可用区中,仍能容忍一个可用区故障。
DNSResolver
客户端在挑选bookie组成ensemble时,需要通过ip反解出对应的zone信息,需要用户实现解析器。考虑到zone与zone间网段是认为规划且不重合的,因此,我们落地时,简单的实现了一个可动态配置生效的子网解析器。示例给出的是ip精确匹配的实现方式。
public class ConfigurableDNSToSwitchMapping extends AbstractDNSToSwitchMapping {
private final Map<String, String> mappings = Maps.newHashMap();
public ConfigurableDNSToSwitchMapping() {
super();
mappings.put("192.168.0.1", "/z1/192.168.0.1"); // /zone/upgrade domain
mappings.put("192.168.1.1", "/z2/192.168.1.1");
mappings.put("192.168.2.1", "/z3/192.168.2.1");
}
@Override
public boolean useHostName() {
return false;
}
@Override
public List<String> resolve(List<String> names) {
List<String> rNames = Lists.newArrayList();
names.forEach(name -> {
String rName = mappings.getOrDefault(name, "/default-zone/default-upgradedomain");
rNames.add(rName);
});
return rNames;
}
}
可配置化DNS解析器示例
数据副本分布在单zone
当某些原因(譬如可用区故障演练)导致只有一个可用区可用时,新写入的数据的全部副本都将落在单可用区,当故障可用区恢复后,仍然有部分历史数据只存在于单可用区,不满足多可用区容灾的高可用需求。
AutoRecovery机制中有一个PlacementPolicy检测机制,但缺少恢复机制。于是我们打了个patch,支持动态机制开启和关闭此功能。这样,当可用区故障恢复后可以自动发现和修复数据全部副本分布在单可用区从而影响数据可用性的问题。
三、弹性架构落地
引入BookKeeper后,延迟消息服务的架构相对漂亮不少。消息业务层面和存储层面完全分离,延迟消息服务本身无状态化,可以轻易伸缩。当可用区故障后,不再需要主从切换。
延迟消息服务新架构
3.1 无状态化改造
存储层分离出去后,业务层实现无状态化成为可能。要达成这一目标,还需解决一些问题。我们先看看BookKeeper使用上的一些约束:
- BookKeeper不支持共享写入的,也即业务层多个节点如果都写数据,则各自写的必然是不同的ledger;
- 虽然BookKeeper允许多读,但多个应用节点各自读取的话,进度是相互独立的,应用必须自行解决进度协调问题。
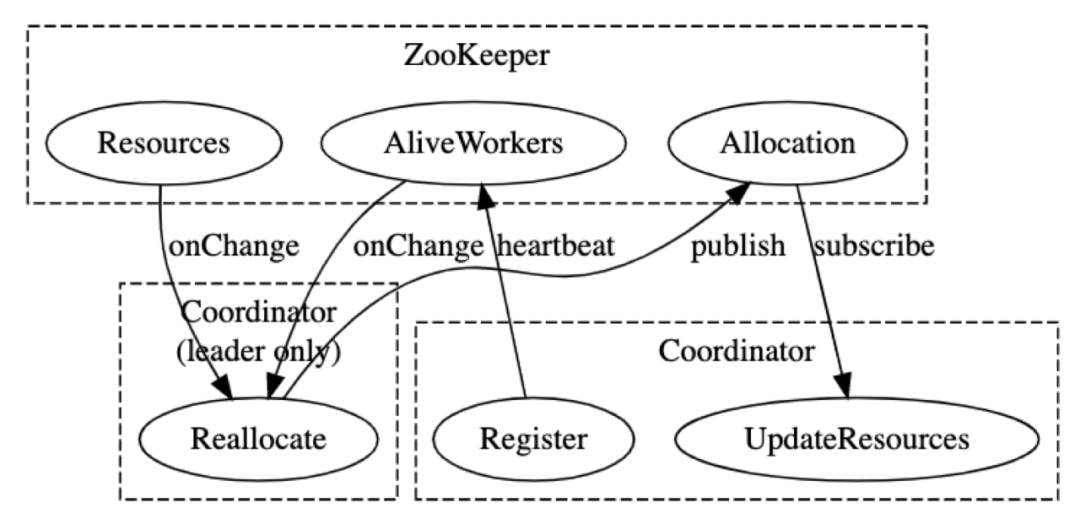
上述两个主要问题,决定我们实现无状态和弹性扩缩容时,必需自行解决读写资源分配的问题。为此,我们引入了任务协调器。
我们首先将存储资源进行分片管理,每个分片上都支持读写操作,但同一时刻只能有一个业务层节点来读写。如果我们把分片看作资源,把业务层节点看作工作者,那么任务协调器的主要职责为:
- 在尽可能平均的前提下以粘滞优先的方式把资源分配给工作者;
- 监视资源和工作者的变化,如有增减,重新执行职责1;
- 在资源不够用时,根据具体策略配置,添加初始化新的资源。
由于是分布式环境,协调器自身完成上述职责时需要保证分布式一致性,当然还要满足可用性要求。我们选择了基于ZooKeeper进行选主的一主多从式架构。
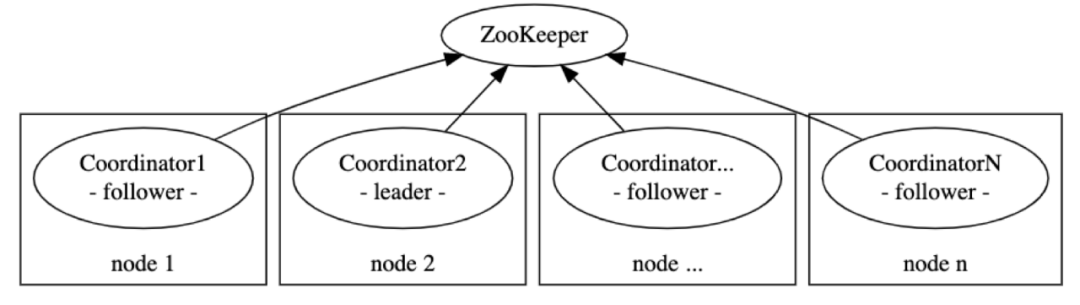
如图所示,协调器对等部署在业务层应用节点中。运行时,协调器通过基于ZooKeeper的leader竞选机制决出leader节点,并由leader节点负责前述任务分配工作。
协调器选举的实现参考ZooKeeper官方文档,这里不再赘述。
3.2 持久化数据
原有架构将延迟消息根据调度时间按每10分钟桶存储在本地,时间临近的桶加载到内存中,使用HashedWheelTimer来调度。该设计存在两个弊端:
- 分桶较多(我们支持2年范围的延迟,理论分桶数量达10万多);
- 单个桶的数据(10分钟)如不能全部加载到内存,则由于桶内未按调度时间排序,可能出现未加载的部分包含了调度时间较早的数据,等它被加载时已经滞后了。
弊端1的话,单机本地10万+文件还不算多大问题,但改造后这些桶信息以元信息的方式存储在ZooKeeper上,我们的实现方案决定了每个桶至少占用3个ZooKeeper节点。假设我们要部署5个集群,平均每个集群有10个分片,每个分片有10万个桶,那使用的ZooKeeper节点数量就是1500万起,这个量级是ZooKeeper难以承受的。
弊端2则无论新老架构,都是个潜在问题。一旦某个10分钟消息量多一些,就可能导致消息延迟。往内存加载时,应该有更细的颗粒度才好。
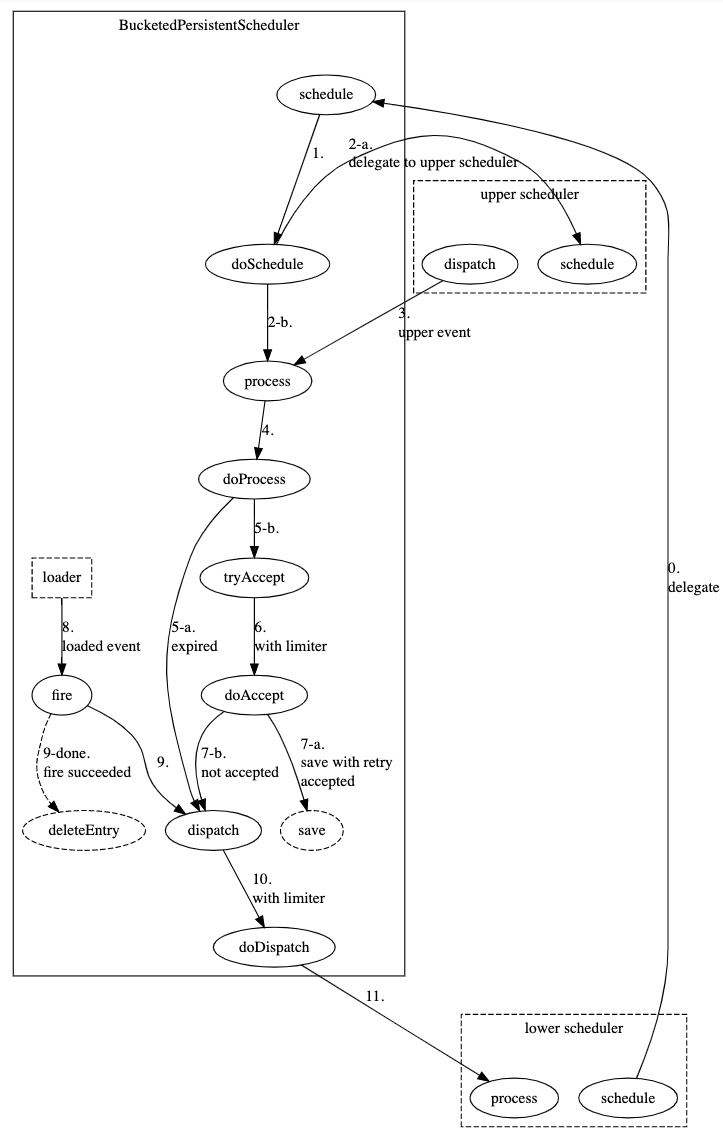
基于以上问题分析,我们参考多级时间轮调度的思路,略加变化,设计了一套基于滑动时间分桶的多级调度方案。
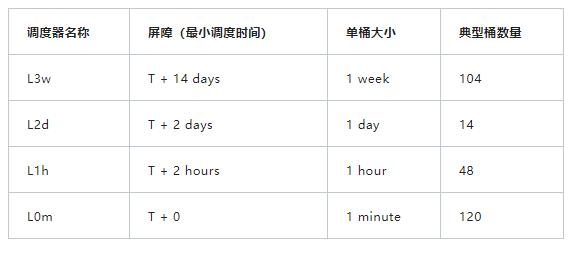
如上表所示,最大的桶是1周,其次是1天,1小时,1分钟。每个级别覆盖不同的时间范围,组合起来覆盖2年的时间范围理论上只需286个桶,相比原来的10万多个桶有了质的缩减。
同时,只有L0m这一级调度器需要加载数据到HashedWheelTimer,故而加载粒度细化到了1分钟,大大减少了因不能完整加载一个桶而导致的调度延迟。
多级调度器以类似串联的方式协同工作。
每一级调度器收到写入请求时,首先尝试委托给其上级(颗粒度更大)调度器处理。如果上级接受,则只需将上级的处理结果向下返回;如果上级不接受,再判断是否归属本级,是的话写入桶中,否则打回给下级。
每一级调度器都会将时间临近的桶打开并发送其中的数据到下一级调度器。比如L1h发现最小的桶到了预加载时间,则把该桶的数据读出并发送给L0m调度器,最终该小时的数据被转移到L0m并展开为(最多)60个分钟级的桶。
四、未来规划
目前bookie集群部署在物理机上,集群新建、扩缩容相对比较麻烦,未来将考虑融入k8s体系;bookie的治理与平台化也是需要考虑的;我们目前只具备同城多中心容灾能力,跨region容灾以及公/私混合云容灾等高可用架构也需要进一步补强。



























