本章概述
随着互联网的不断发展,企业的业务系统变得越来越复杂,原本单一的单体应用系统已经无法满足企业业务发展的需要。于是,很多企业开始了对项目的分布式与微服务改造,新项目也在开始的时候就会采用分布式与微服务的架构模式。
一个系统采用分布式与微服务架构后,会被拆分成许多服务模块,这些服务模块之间的调用关系错综复杂,对于客户端请求的分析与处理就会显得异常复杂。此时,就需要一种技术来解决这些问题,而这种技术就是分布式链路追踪技术。
分布式链路追踪
随着互联网业务快速扩展,企业的业务系统变得越来越复杂,不少企业开始向分布式、微服务方向发展,将原本的单体应用拆分成分布式、微服务。这也使得当客户端请求系统的接口时,原本在同一个系统内部的请求逻辑变成了需要在多个微服务之间流转的请求。
单体架构中可以使用AOP在调用具体的业务逻辑前后分别打印一下时间即可计算出整体的调用时间,使用 AOP捕获异常也可知道是哪里的调用导致的异常。
但是在分布式微服务场景下,使用AOP技术是无法追踪到各个微服务的调用情况的,也就无法知道系统中处理一次请求的整体调用链路。
另外,在分布式与微服务场景下,我们需要解决如下问题:
- 如何快速发现并定位到分布式系统中的问题。
- 如何尽可能精确的判断故障对系统的影响范围与影响程度。
- 如何尽可能精确的梳理出服务之间的依赖关系,并判断出服务之间的依赖关系是否合理。
- 如何尽可能精确的分析整个系统调用链路的性能与瓶颈点。
- 如何尽可能精确的分析系统的存储瓶颈与容量规划。
- 如何实时观测系统的整体调用链路情况。
上述问题就是分布式链路追踪技术要解决的问题。所谓的分布式链路追踪,就是将对分布式系统的一次请求转化成一个完整的调用链路。这个完整的调用链路从请求进入分布式系统的入口开始,直到整个请求返回为止。并在请求调用微服务的过程中,记录相应的调用日志,监控系统调用的性能,并且可以按照某种方式显示请求调用的情况。
在分布式链路追踪中,可以统计调用每个微服务的耗时,请求会经过哪些微服务的流转,每个微服务的运行状况等信息。
核心原理
假定三个微服务调用的链路如下图所示:Service 1 调用 Service 2,Service 2 调用 Service 3 和 Service 4。
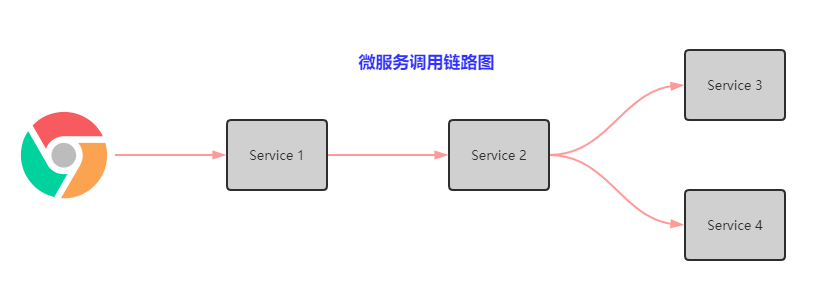
那么链路追踪会在每个服务调用的时候加上 Trace ID 和 Span ID。如下图所示:
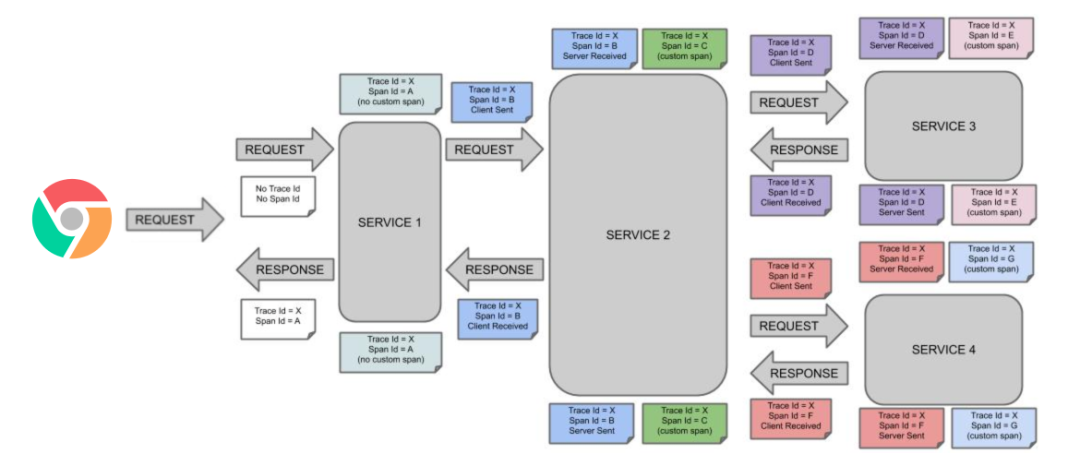
小伙伴注意上面的颜色,相同颜色的代表是同一个 Span ID,说明是链路追踪中的一个节点。
- 第一步:用户端调用 Service 1,生成一个 Request,Trace ID 和 Span ID 为空,那个时候请求还没有到 Service 1。
- 第二步:请求到达 Service 1,记录了 Trace ID = X,Span ID 等于 A。
- 第三步:Service 1 发送请求给 Service 2,Span ID 等于 B,被称作 Client Sent,即用户端发送一个请求。
- 第四步:请求到达 Service 2,Span ID 等于 B,Trace ID 不会改变,被称作 Server Received,即服务端取得请求并准备开始解决它。
- 第五步:Service 2 开始解决这个请求,解决完之后,Trace ID 不变,Span ID = C。
- 第六步:Service 2 开始发送这个请求给 Service 3,Trace ID 不变,Span ID = D,被称作 Client Sent,即用户端发送一个请求。
- 第七步:Service 3 接收到这个请求,Span ID = D,被称作 Server Received。
- 第八步:Service 3 开始解决这个请求,解决完之后,Span ID = E。
- 第九步:Service 3 开始发送响应给 Service 2,Span ID = D,被称作 Server Sent,即服务端发送响应。
- 第十步:Service 3 收到 Service 2 的响应,Span ID = D,被称作 Client Received,即用户端接收响应。
- 第十一步:Service 2 开始返回 响应给 Service 1,Span ID = B,和第三步的 Span ID 相同,被称作 Client Received,即用户端接收响应。
- 第十二步:Service 1 解决完响应,Span ID = A,和第二步的 Span ID 相同。
- 第十三步:Service 1 开始向用户端返回响应,Span ID = A、
- Service 3 向 Service 4 发送请求和 Service 3 相似,对应的 Span ID 是 F 和 G。可以参照上面前面的第六步到第十步。
把以上的相同颜色的步骤简化为下面的链路追踪图:
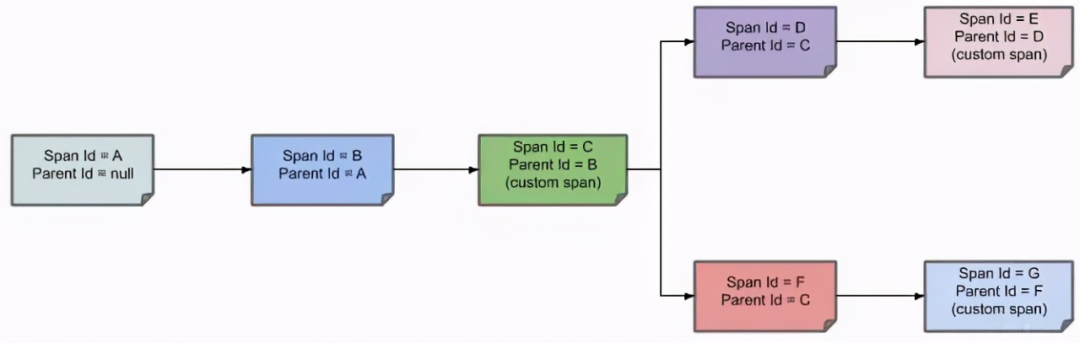
- 第一个节点:Span ID = A,Parent ID = null,Service 1 接收到请求。
- 第二个节点:Span ID = B,Parent ID= A,Service 1 发送请求到 Service 2 返回响应给Service 1 的过程。
- 第三个节点:Span ID = C,Parent ID= B,Service 2 的 中间解决过程。
- 第四个节点:Span ID = D,Parent ID= C,Service 2 发送请求到 Service 3 返回响应给Service 2 的过程。
- 第五个节点:Span ID = E,Parent ID= D,Service 3 的中间解决过程。
- 第六个节点:Span ID = F,Parent ID= C,Service 3 发送请求到 Service 4 返回响应给 Service 3 的过程。
- 第七个节点:Span ID = G,Parent ID= F,Service 4 的中间解决过程。
通过 Parent ID 就可找到父节点,整个链路即可以进行跟踪追溯了。
备注:核心原理部分内容来源:cnblogs.com/jackson0714/p/sleuth_zipkin.html
解决方案
目前,行业内比较成熟的分布式链路追踪技术解决方案如下所示。
技术 | 说明 |
Cat | 由大众点评开源,基于Java开发的实时应用监控平台,包括实时应用监控,业务监控 。集成方案是通过代码埋点的方式来实现监控,比如:拦截器,过滤器等。对代码的侵入性很大,集成成本较高。风险较大。 |
ZipKin | 由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。结合spring-cloud-sleuth使用较为简单, 集成方便, 但是功能较简单。 |
Pinpoint | Pinpoint是一款开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件, UI功能强大,接入端无代码侵入。 |
Skywalking | SkyWalking是国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件, UI功能较强,接入端无代码侵入。 |
Sleuth | Sleuth是SpringCloud中的一个组件,为Spring Cloud实现了分布式跟踪解决方案。 |