前言
在之前的文章中,我们提到车联网 TSP 平台拥有很多不同业务的主题,并介绍了 如何根据不同业务场景进行 MQTT 主题设计。车辆会持续不断产生海量的消息,每一条通过车联网上报的数据都是非常珍贵的,其背后蕴藏着巨大的业务价值。因此我们构建的车辆 TSP 平台也通常需要拥有千万级主题和百万级消息吞吐能力。
传统的互联网系统很难支撑百万量级的消息吞吐。在本文中,我们将主要介绍如何针对百万级消息吞吐这一需求进行新一代车联网平台架构设计。

车联网场景消息吞吐设计的关联因素
车联网的消息分为上行和下行。上行消息一般是传感器及车辆发出的告警等消息,把设备的信息发送给云端的消息平台。下行消息一般有远程控制指令集消息和消息推送,是由云端平台给车辆发送相应的指令。
在车联网消息吞吐设计中,我们需要重点考虑以下因素:
(1) 消息频率
车在行驶过程中,GPS、车载传感器等一直不停地在收集消息,为了收到实时的反馈信息,其上报接收的消息也是非常频繁的。上报频率一般在 100ms-30s 不等,所以当车辆数量达到百万量级时,平台就需要支持每秒百万级的消息吞吐。
(2) 消息包大小
消息是通过各种传感器来采集自身环境和状态信息(车联网场景常见的有新能源国标数据和企标数据)。整个消息包大小一般在 500B 到几十 KB 不等。当大量消息包同时上报时,需要车联网平台拥有更强的接收、发送大消息包的能力。
(3) 消息延时
车辆在行驶过程中,消息数据只能通过无线网络来进行传输。在大部分车联网场景下,对车辆的时延要求是 ms 级别。平台在满足百万级吞吐条件下,还需要保持低延时的消息传输。
(4) Topic 数量和层级
在考虑百万级消息吞吐场景时,还需要针对消息 Topic 数量和 Topic 树层级进行规范设计。
(5) Payload 编解码
当消息包比较大的时候,需要重点考虑消息体的封装。单纯的 JSON 封装在消息解析时不够高效,可以考虑采用 Avro、Protobuf 等编码格式进行 Payload 格式化封装。
对于百万级消息吞吐场景,基于 MQTT 客户端共享订阅消息或通过规则引擎实时写入关系型数据库的传统架构显然无法满足。目前主流的架构选型有两种:一种是消息接入产品/服务+消息队列(Kafka、Pulsar、RabbitMQ、RocketMQ 等),另外一种是消息接入产品/服务+时序数据库(InfluxDB、TDengine、Lindorm等)来实现。
接下来我们将基于上述的关联因素和客户案例的最佳实践,以云原生分布式物联网消息服务器 EMQX 作为消息接入层,分别介绍这两种架构的实现方式。
EMQX+Kafka 构建百万级吞吐车联网平台
架构设计
Kafka 作为主流消息队列之一,具有持久化数据存储能力,可进行持久化操作,同时可通过将数据持久化到硬盘以及 replication 防止数据丢失。后端 TSP 平台或者大数据平台可以批量订阅想要的消息。
由于 Kafka 拥有订阅发布的能力,既可以从南向接收,把上报消息缓存起来;又可以通过北向的连接,把需要发送的指令通过接口传输给前端,用作指令下发。
我们以 Kafka 为例,构建 EMQX+Kafka 百万级吞吐车联网平台:
- 前端车机的连接与消息可通过公有云商提供的负载均衡产品用作域名转发,如果采用了 TLS/DTLS 的安全认证,可在云上建立四台 HAProxy/Nginx 服务器作为证书卸载和负载均衡使用。
- 采用 10 台 EMQX 组成一个大集群,把一百万的消息吞吐平均分到每个节点十万消息吞吐,同时满足高可用场景需求。
- 如有离线离线/消息缓存需求,可选用 Redis 作为存储数据库。
- Kafka 作为总体消息队列,EMQX 把全量消息通过规则引擎,转发给后端 Kafka 集群中。
- 后端 TSP 平台/OTA 等应用通过订阅 Kafka 的主题接收相应的消息,业务平台的控制指令和推送消息可通过 Kafka/API 的方式下发到 EMQX。
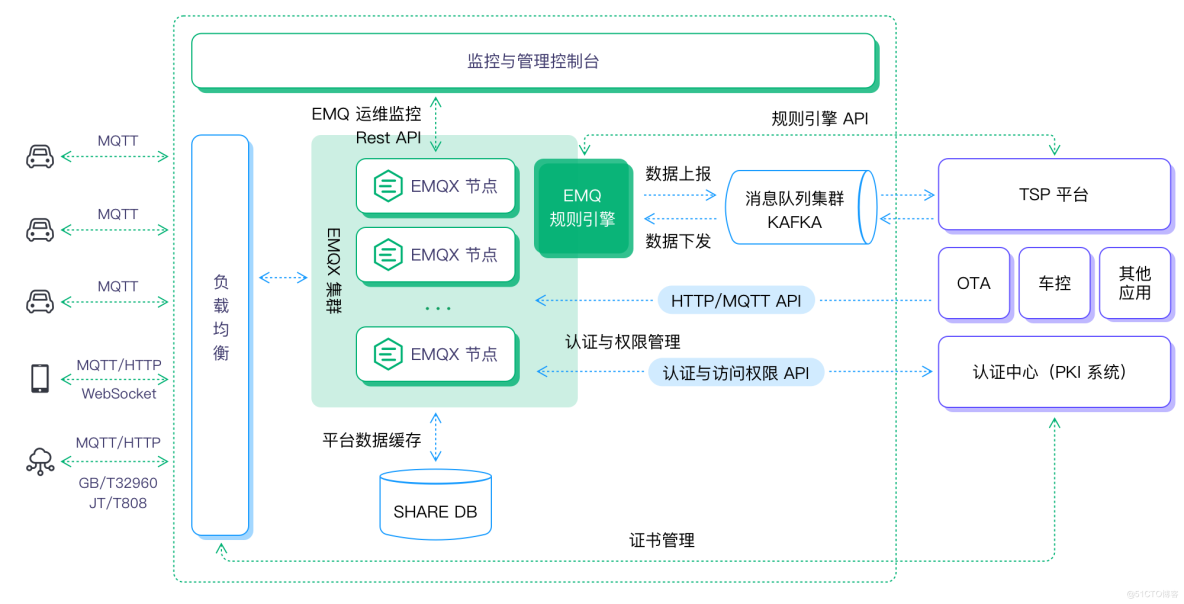
总体架构图
在这一方案架构中,EMQX 作为消息中间件具有如下优势,可满足该场景下的需求:
- 支持千万级车辆连接、百万级消息吞吐能力。
- 分布式集群架构,稳定可靠,支持动态水平扩展。
- 强大的规则引擎和数据桥接、持久化能力,支持百万级消息吞吐处理。
- 拥有丰富 API 与认证等系统能顺利对接。
百万吞吐场景验证
为了验证上述架构的吞吐能力,在条件允许的情况下,我们可以通过以下配置搭建百万级消息吞吐测试场景。压测工具可以选用 Benchmark Tools、JMeter 或 XMeter 测试平台。共模拟 100 万设备,每个设备分别都有自己的主题,每个设备每秒发送一次消息,持续压测 12 小时。
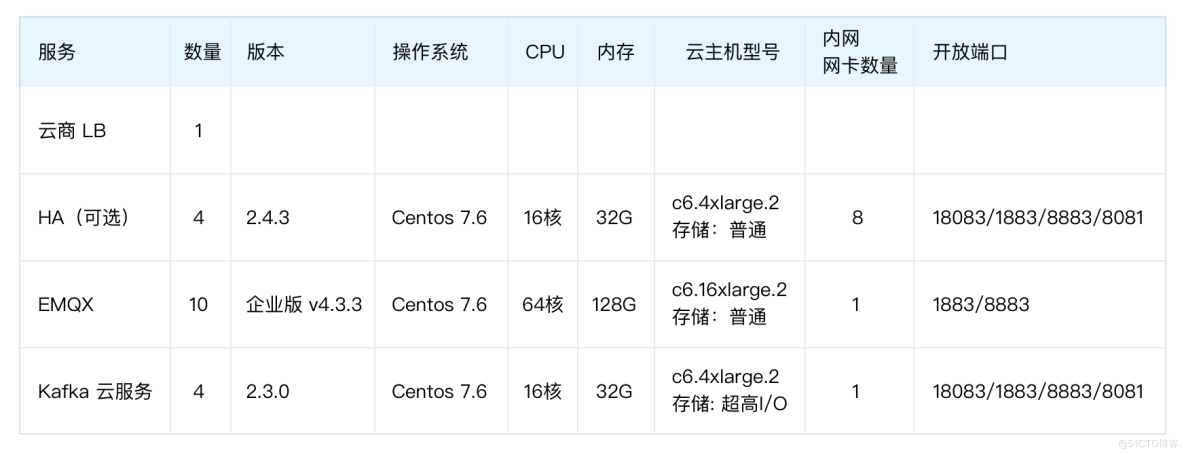
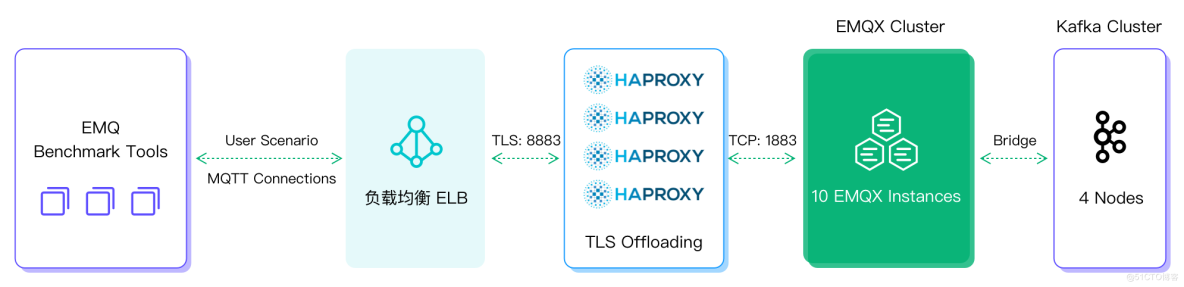
压测架构图如下:
性能测试部分结果呈现:

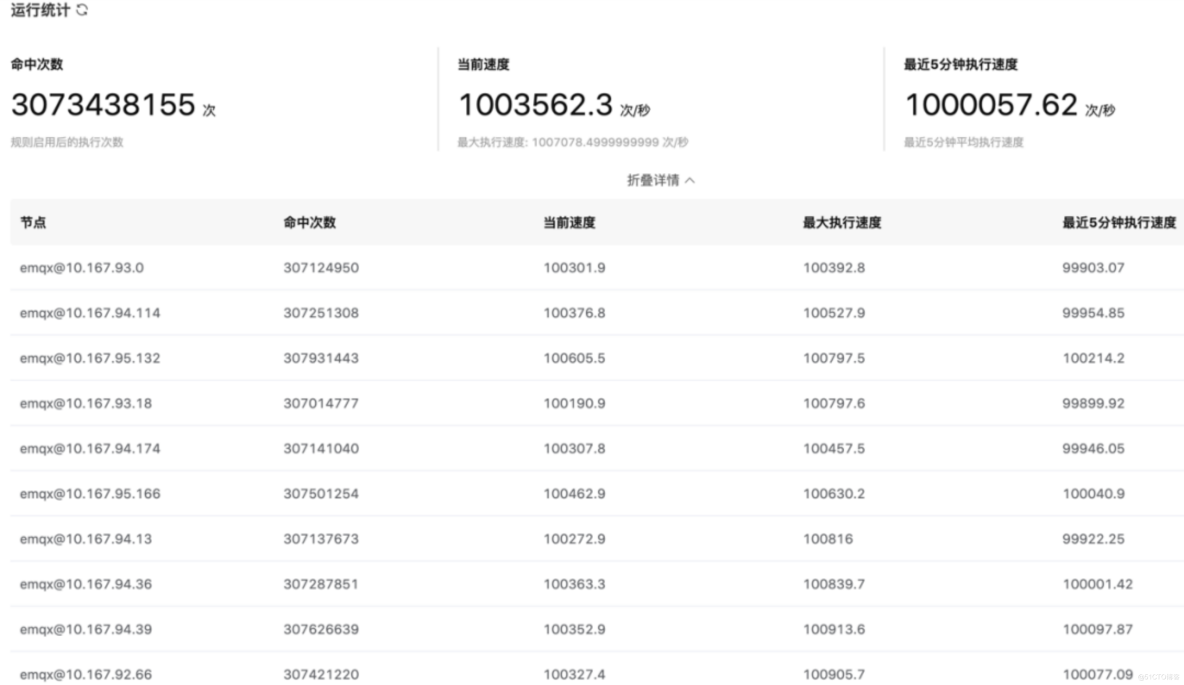
(1) EMQX 集群 Dashboard 统计
EMQX 规则引擎中可以看到每个节点速度为 10 万/秒的处理速度,10 个节点总共 100 万/秒的速度进行。
(2) EMQX 规则引擎统计
在 Kafka 中可以看到每秒 100 万的写入速度,并且一直持续存储。

Kafka 管理界面统计
EMQX+InfluxDB 构建百万级吞吐车联网平台
架构设计
采用 EMQX+ 时序数据库的架构,同样可以构建百万级消息吞吐平台。在本文我们以 InfluxDB 时序数据库为例。
InfluxDB 是一个高性能的时序数据库,被广泛应用于存储系统的监控数据、IoT 行业的实时数据等场景。它从时间维度去记录消息,具备很强写入和存储性能,适用于大数据和数据分析。分析完的数据可以提供给后台应用系统进行数据支撑。
此架构中通过 EMQX 规则引擎进行消息转发,InfluxDB 进行消息存储,对接后端大数据和分析平台,可以更方便地服务于时序分析。
- 前端设备的消息通过云上云厂商的负载均衡产品用作域名转发和负载均衡。
- 本次采用 1 台 EMQX 作为测试,后续需要时可以采用多节点的方式,组成相应的集群方案(测试 100 万可以部署 10 台 EMQX 集群)。
- 如有离线离线/消息缓存需求,可选用 Redis 作为存储数据库。
- EMQX 把全量消息通过规则引擎转发给后端InfluxDB进行数据持久化存储。
- 后端大数据平台通过 InfluxDB 接收相应的消息,对其进行大数据分析,分析后再通过 API 的方式把想要的信息传输到 EMQX。
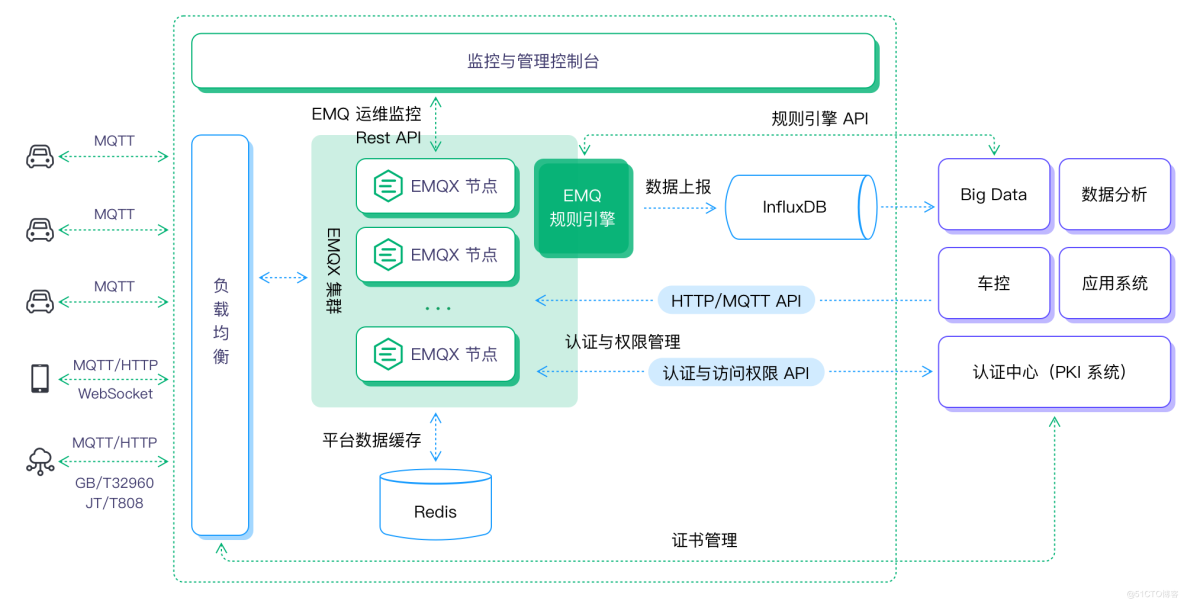
总体架构图
场景验证
如测试架构图中所示,XMeter 压力机模拟 10 万 MQTT 客户端向 EMQX 发起连接,新增连接速率为每秒 10000,客户端心跳间隔(Keep Alive)300 秒。所有连接成功后每个客户端每秒发送一条 QoS 为 1、Payload 为 200B 的消息,所有消息通过 HTTP InfluxDB 规则引擎桥过滤筛选并持久化发至 InfluxDB 数据库。
测试结果呈现如下:

EMQX Dashboard 统计:
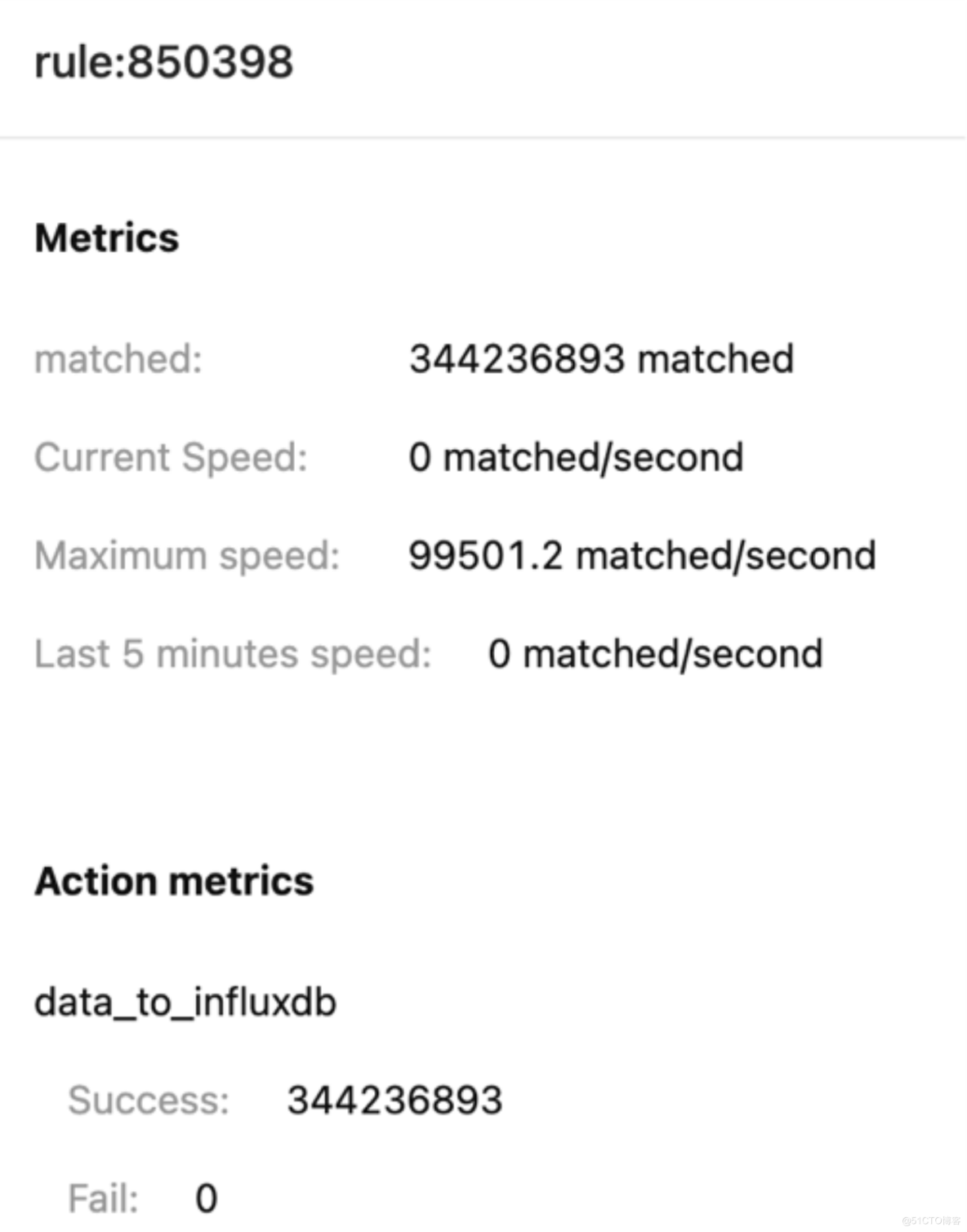
EMQX 规则引擎统计:
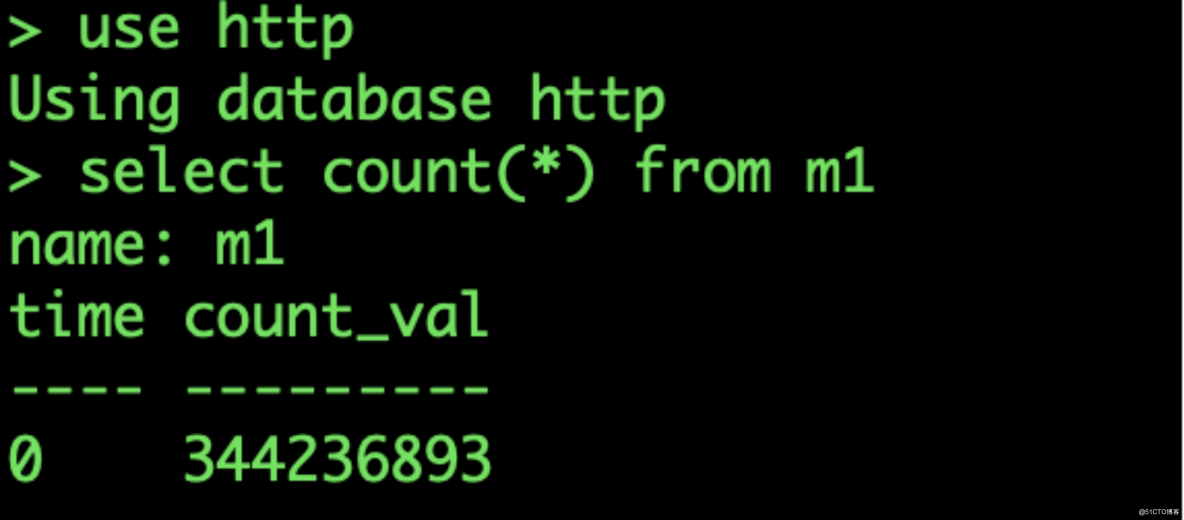
InfluxDB 数据库收到数据:
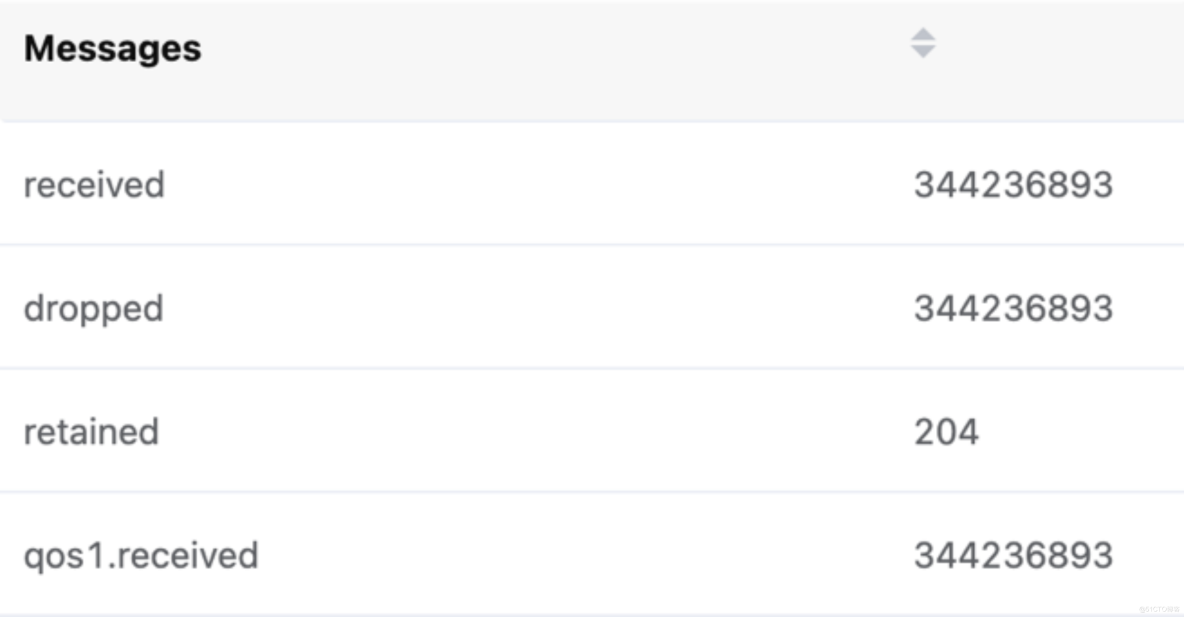
EMQX Dashboard 消息数统计
单台 EMQX 服务器实现了单台服务器 10 万 TPS 的消息吞吐持久化到 InfluxDB 能力。参考 EMQX+Kafka 架构的测试场景,将 EMQX 的集群节点扩展到 10 台,就可以支持 100 万的 TPS 消息吞吐能力。
结语
通过本文,我们介绍了车联网场景消息吞吐设计需要考虑的因素,同时提供了两种较为主流的百万级吞吐平台架构设计方案。面对车联网场景下日益增加的数据量,希望本文能够为相关团队和开发者在车联网平台设计与开发过程中提供参考。