作者 | 杜嘉平

为什么要探讨这个话题
探讨这个话题的本质原因是来源于为客户提供数据战略咨询服务时的思考,很多客户的痛点与诉求看似可以用机器学习解决,但实际上却充满风险,所以究竟机器学习什么时候该用,什么时候不该用,便成为了思考的对象。
机器学习起源于学术界,但再也不会是一件学术上的事情了。我们会在日常生活中听到大量机器学习的应用,很多商业产品与业务流程中也纷纷开始了机器学习的应用。尽管机器学习一直在被广泛的使用,但是并不是任何看起来像是机器学习能解决的事情,都能够被机器学习所解决,或者说在很多情况下,机器学习并不是最优解。
一旦在解决问题的一开始就选择了错误的解决方案,那么之后对于机器学习解决方案进行持续运营的MLOps也就变得毫无意义。在开始一项机器学习项目之前,我们必须反复对业务价值、业务流程、数据可行性、数据完备性等几个维度进行研究,以确定使用机器学习的必要性。因为但凡公司决定使用机器学习,那么其前期没有回报的投资成本将会是非常巨大的,投资回报率将是极小。
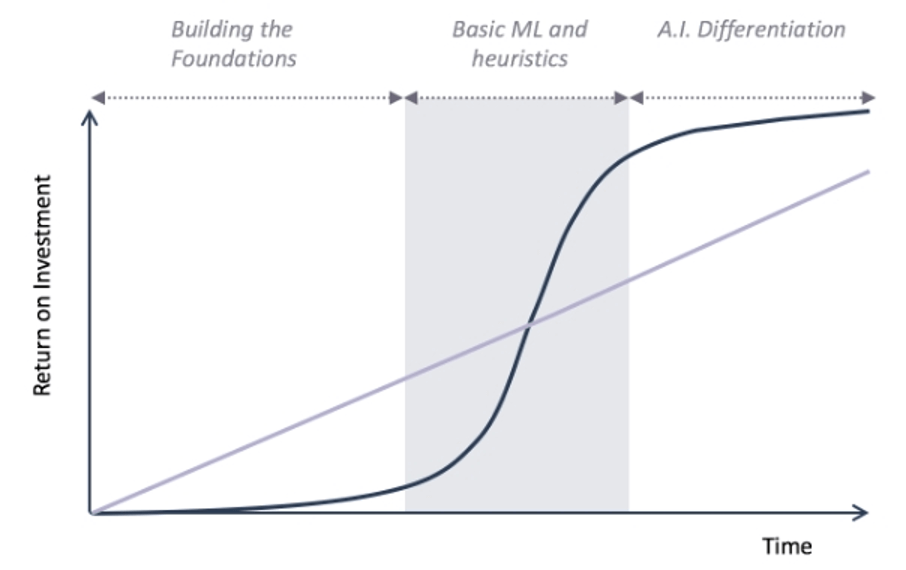
图片来源:https://venturebeat.com/2018/11/24/before-you-launch-your-machine-learning-model-start-with-an-mvp/
什么时候该使用机器学习?
机器学习的目的:更精准地替代经验以及更大面积复用人工。在这个文章中,要回答什么时候该用机器学习,我们需要回答一个更为本质的问题,什么是机器学习?
这里我将这个答案拆分成由几个要素组成的一句话:
通过(1)重复(2)学习(3)复杂(4)历史数据的(5)规律特征,将学习成果(6)规模化地应用于(7)未来数据中以得到(8)预测结果,来倒推所有要素的满足条件,所有要素都满足条件,那么才是真正该用机器学习的时候。
1. 重复:相对大量的训练集数据
如果教一个没有见过猫狗的小朋友区别猫狗,我想只需要给他10张左右的猫猫和狗狗的照片之后,他就能很好的识别出猫和狗的特征以区分猫狗了。但是如果只给机器学习模型提供10张图片进行学习,那学习效果一定是很差的。所以我们需要利用拥有同样特征规律的重复性的数据,对模型进行训练,所以机器学习的使用,一定是要在大量训练集数据的前提下进行的。如果我们存在的历史数据不能够满足模型的学习效果,那么我们可能需要再等等,积攒更多的数据了。

图片来源:https://ypw.io/dogs-vs-cats/
2. 学习:机器学习应该有足够能力去学习
在我的一些咨询项目中,很多业务人员都会使用Excel通过对于一列或两列数据的规则计算得到第三列数据(前提不是时间序列数据)。这是一个很常见的Excel应用场景,因为在整个过程中不存在很强“学习”的过程。当他们提出希望,能够通过机器学习智能化地得到结果这种需求,我一定不会建议客户上机器学习,因为这点小事,机器学习不够学。
对于机器学习的学习过程而言,首先必须要有足够的知识让模型去学习,这个知识就是数据。通过对于大量数据学习,产生相应的结果是机器学习的普遍过程,例如在预测Airbnb租价,模型需要学习大量房屋特征、房屋地理属性、以及历史租价等数据对于“数据->结果”这一关系进行学习,在新数据喂进模型时,才能够通过学习成果预测出相应的租价。
当然,模型和学生一样,有好学生和坏学生,如何评判学得好还是学得差,就是需要用一个objective function来判别的,举个简单的例子:MAE(Mean Absolute Error)。这个function在验证(validation)的时候就会写入验证方法,以对于模型的学习效果产生最终的客观评价。
总而言之,对于机器学习不要大材小用,所应用的场景应该是有能力去学习、有潜力去学习、有数据去学习,那才能够满足“学习”这个元素的要求。
3. 复杂:数据的规律特征要复杂
A,B,C
1,1,2;
2,2,4;
2,3,5;
给你上面一组数据,你是否能看出其中的规律特征?大胆地说,只要你上过小学2年级,就一定能够一眼看出这是C=1A+1B的简单规律。这样的数据可以使用机器学习进行学习吗?可以,就是个最简单不过的线性回归模型(Liner regression model)。但应该使用机器学习模型吗?当然不应该。再比如通过邮箱编码来识别所在地区或是通过身份证号识别你的户口所在地这些简单应用,也是简单规律,规则引擎就可以实现这样的预测。
但是通过学习房屋特征(地板材质、墙面材质、面积大小、房屋年龄、房屋建造结构)以及地理属性(是否临街、所在区域、是否存在地铁、周围配套情况)以及历史二手房交易价格,得到的二手房交易价格预测模型,就是一个很典型的机器学习应用场景。因为尽管我们知道房屋特征、地理属性这些多维度的变量与二手房交易价格之间存在规律特征,但这种规律特征足够复杂,以至于有必要借助机器学习对于规律特征进行探索。
4. 历史数据:必须存在可以采集的历史数据
之所以要强调这一点,是因为在以往对于某些500强企业的数字化战略咨询中,有一些很常见的需求就是领导希望预测一些目标值,并且预测的场景也确实足够具有业务价值,但问题是历史数据全部靠手工采集,通过Excel每天进行手动记录,客户希望我们通过智能模型来满足领导对于目标值预测的需求。
接到这种需求和问题,我会自动将其识别为“数字化需求”而不是“智能化”需求,解决方案也是会帮助客户梳理业务流程与系统触点,帮助其采集模型所需要的数据形成数据资产。只有对于数据的数字化采集才能形成大量历史数据,并且能够在未来MLOps中,提供相应的运营依据与模型优化条件。
所以在这一点,历史数据存在并且可采集,才是满足机器学习应用在“历史数据”这一要素的满足条件。
5. 规律特征:规律特征是可学习的
机器学习模型的应用必须要在有规律可以学习的情况下产生作用的。一个智商正常的人肯定不会投资大量金钱来建立一个用来预测骰子投掷结果的机器学习系统,因为掷骰子结果的产生方式是没有规律的。
当然,规律特征是否存在,有些时候确实不是那么明显,所以这就需要引入ML MVP的概念,通过经验无法判断是否存在规律特征的项目,我们需要进行快速验证,通过模型的结果来得到一个更加理性客观的结果,以判断规律特征是否存在,是否可学习。
6. 可以规模化使用
在我建模在后,策略先行这篇文章中,提到机器学习的两大作用,1)超越人类经验,2)重复利用替代人工。所以一个机器学习的重复利用能力是非常重要的。投资人投入金钱建立模型,不会就想模型利用一两次然后就废掉。所以一个可以将机器学习重复利用的应用场景是非常重要的。
7. 未来数据:未来数据的特征和模型训练数据特征相符
机器学习的核心是经验的复用。所以只有未来数据的特征与训练模型时训练集数据的特征相符时,机器学习模型才能够把经验复用,否则将派不上任何用场。如果用2010年的房产数据训练的二手房成交价预测模型来预测2021那年的二手房成交价,很显然模型将不会准确预测出结果,因为整个描述房屋与价格的训练集数据应该算是今非昔比。
这也更加说明了机器学习模型更新的重要性,因为数据会逐步迭代,所以模型的训练也要进行逐步迭代以保证保质期的延长。
但是这存在一个问题,你怎么知道你的未来数据能够与模型训练时的数据特征相符?好问题,我们没办法知道,所以需要进行假设,我们一般认为如果不发生业务上的大变化,只要时间跨度不长,那么新老数据就是特征相符的。当然,这一点大可不必过多担心,以为MLOps的数据监控与模型监控能够很好的对于数据特征变化进行识别,一旦出现识别出数据特征的变化,整个体系会立即触发Pipeline Trigger对于模型启动重新训练机制。关于pipeline trigger内容可以参考之前写过的文章:不要让机器学习模型成为孤儿。
8. 预测:解决的问题是一个预测类的问题
机器学习算法就是用来进行预测的,所以机器学习所能够解决的问题,就是一个预测性的问题。回归算法预测数值、分类算法预测分类值、聚类算法预测聚类组,虽然所预测的结果维度不一样,但是他们最终得到的结果都是一个我们在使用模型前想要去得到的预测结果。
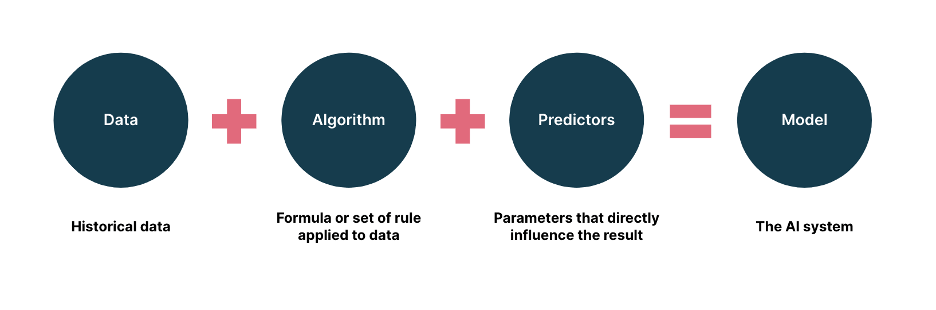
什么时候不该使用机器学习?
首先,上面说的8条一旦无法满足,那么就要警惕是否要进行机器机器学习了。除此之外还有哪些?我以快速回答的方式进行阐述:
1. 不相信机器学习(没有信仰)
如果你的客户老板,领导,机器学习使用方是不信任机器学习的,就算机器学习能够发挥再大的价值,也是很难进行推动落地的。
2. 解决简单的问题
如果需要的解决的问题非常简单,通过一些规则其实也能够达到预测的效果,那么不要用,可以使用性价比更高的“规则引擎”来替代机器学习。
3. 一个微不足道的预测错误会引来很大的灾难
机器学习模型虽然整体上的质量在部署使用前会经过保证,但是这不代表它能够对于每一个个体产生相同的预测效果,所以在一些单独个体的预测上可能会存在着较大的错误。如果这个错误会导致巨大的损失和灾难性的后果,那么不要用。
4. 性价比不高
机器学习的建立以及后期的运营都是需要成本的,如果这件事情的投入无法获得相应的投入,那么就慎用机器学习模型。
5. 业务流程中人工经验过多
我提到机器学习模型策略建立的本质,是通过预测量化的人工经验,以取代经验判断变成模型判断。但是如果人工的一个判断需要非常多维度的经验才能够去做出,那么这就不是一个很好的应用的场景。因为就算我们通过机器学习模型给出了一个经验判断的预测值,那么最终的决定还是会经过其他多个人工经验的权衡。
最理想的结果就是,这个预测值给到你,你就可以直接落地一个行为,这是一个1对1的结果,即1个经验或1个指标决定1个行为,而不是多对1 。就算机器学习解决了“多”里面的1个或2个经验的预测,那么还有很多的人工经验影响最终决定最后的行为策略。所以如果人工经验过多,机器学习恐怕就算给出了其中一条经验的预测结果,也是无法直接落地让业务使用并做出相应判断的。
写在最后
以上是通过调研与个人总结后对于使用机器学习条件的小小归纳。在开始考虑使用机器学习之前请先从这些方面去仔细思考机器学习的必要性。如果在不合适的场景下使用了机器学习,那么后面要面临的风险还是非常多的。