引言
一直以来,人们试图手工编写算法来理解人工生成的内容,但是成功率极低。例如,计算机很难“掌握”图像的语义内容。对于这类问题,AI科学家已经尝试通过分析汽车、猫、外套等低级像素来解决,但结果并不理想。尽管颜色直方图和特征检测器在一定程度上发挥了作用,但在大多数实际应用中它们的准确率仍然极低。
在过去十年中,大数据和深度学习的结合从根本上改变了我们处理计算机视觉、自然语言处理和其他机器学习(ML)应用程序的方式。例如,从垃圾邮件检测到真实的文本再到视频合成等任务都取得了惊人的进步,在这些具体应用中准确率指标已经达到了超人的水平。但是,这些改进伴随而来的一个显著的副作用是嵌入向量的使用增加,即通过在深度神经网络中获取中间结果而产生的模型组件。OpenAI相关的Web页面上提供了下面这样一段比较贴切的概述:
“嵌入是一种特殊的数据表示格式,无论机器学习模型还是相关算法都很容易使用它。嵌入是文本语义的信息密集表示。每个嵌入都可以表示为一个浮点数向量;因此,向量空间中两个嵌入之间的距离与原始格式中两个输入之间的语义相似性是相关的。例如,如果两个文本相似,那么它们的向量表示也应该相似。”
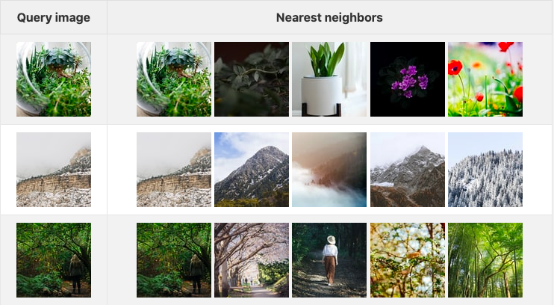
下表显示了三个查询图像以及它们在嵌入空间中对应的前五个图像。在此,我使用了Unsplash Lite网站提供的前1000个图像作为数据集。

训练嵌入任务的新模型
从理论上讲,训练一个新的ML模型并生成嵌入听起来很简单:采用最新的体系结构支持的预构建模型,并用一些数据对其进行训练。
从表面上看,使用最新的模型架构似乎很容易达到最先进的效果。然而,这与事实相距甚远。下面,不妨让我们先回顾一下与训练嵌入模型相关的一些常见陷阱(这些也适用于一般的机器学习模型):
1. 数据不足:在没有足够数据的情况下从头开始训练一个新的嵌入模型,这容易导致一种称为过度拟合的现象。事实上,只有最大的全球性组织才有足够的数据让训练从零开始成为一种新模型;其他公司或者个人则必须依靠反复微调。这种微调实际上对应一个过程;在这个过程中,一般都是基于一个已经训练过的包含大量数据的模型,并在此基础上使用一个较小的数据集进行不断的提取操作。
2. 超参数选择不当:超参数是用于控制训练过程的常数,例如模型学习的速度或单个批次中用于训练的数据量。在微调模型时,选择一组合适的超参数非常重要,因为对特定值的微小更改可能会导致截然不同的结果。近期研究表明,ImageNet-1k的精度提高了5%以上(这是很大的),这一成果是通过改进训练程序并从头开始训练同一模型实现的。
3. 高估自我监督模型:自我监督(self-supervision)一词指的是一种训练过程,其中输入数据的“基础”是通过利用数据本身而不是标签来学习的。一般来说,自监督方法非常适合预训练(在使用较小的标记数据集对模型进行微调之前,使用大量未标记数据以自监督方式训练模型),但直接使用自监督嵌入可能会导致次优性能。
4. 解决上述三个问题的一种常见方法是,在根据标记数据微调模型之前,使用大量数据训练自监督模型。这已经被证明对NLP非常有效,但对CV(计算机视觉)并不是很有效。

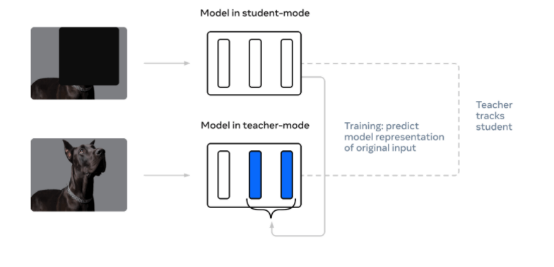
这里展示的是Meta公司的data2vec训练技术的例子。这是一种自我监督的方法,用于跨各种非结构化数据类型训练深层神经网络。(来源:元人工智能博客)
使用嵌入模型的缺陷
在训练嵌入模型的过程中经常出现一些相关的常见错误。常见的情况是,许多希望使用嵌入的开发人员会立即在学术类数据集上使用预先训练好的模型,例如ImageNet(用于图像分类)和SQuAD(用于问答)。然而,尽管目前存在大量经过预训练的模型可用,但要获得最大的嵌入性能,还是应该避免以下陷阱:
1. 训练和推理数据不匹配:使用由其他组织训练的现成模型已成为开发ML应用程序的一种流行方式,而无需再耗费数千个GPU/TPU小时去重复训练。理解特定嵌入模型的局限性,以及它如何影响应用程序性能,这一点是非常重要的;如果不了解模型的训练数据和方法,则很容易误解结果。例如,训练嵌入音乐的模型在应用于实际的语音应用程序时往往效果不佳;反之,亦然。
2. 层选择不当:当使用完全监督的神经网络作为嵌入模型时,特征通常取自激活的第二到最后一层(一般称为倒数第二层)。但是,这可能会导致性能不理想;当然,具体情形还要取决于实际的应用程序。例如,当使用经过图像分类训练的模型嵌入徽标和/或品牌的图像时,使用早期激活可能会提高性能。这是因为这种方案更好地保留了对那些并不是很复杂的图像分类至关重要的一些低级特征(边和角)。
3. 不相同的推理条件:为了从嵌入模型中提取最大性能,训练和推理条件必须相同。实际上,情况往往并非如此。例如,在使用TorchVision的标准resnet50模型的过程中,当使用双三次插值和最近邻插值进行下采样(downsample)时,会生成两个完全不同的结果(见下文)。
BICUBIC INTERPOLATION | NEAREST INTERPOLATION | |
预测类 | coucal | robin, American robin, Turdus migratorius |
概率 | 27.28% | 47.65% |
嵌入向量 | [0.1392, 0.3572, 0.1988, ..., 0.2888, 0.6611, 0.2909] | [0.3463, 0.2558, 0.5562, ..., 0.6487, 0.8155, 0.3422] |
部署嵌入模型
一旦你顺利通过前面的训练并克服与验证模型相关的所有障碍,那么,接下来的一个关键步骤就是扩展和部署程序。但嵌入模型部署说起来容易,做起来却非易事。MLOps是与DevOps相关的一个领域,专门用于实现这一目的。
1. 选择合适的硬件:嵌入模型与大多数其他ML模型类似,可以在各种类型的硬件上运行,从标准的日常CPU到可编程逻辑(FPGA)。几乎所有的网站上发布的研究论文都集中在分析成本与效率之间的权衡,并强调大多数组织在解决这方面问题时所面临的困难。
2. 模型部署方面已经有许多现成的MLOP和分布式计算平台(包括许多开源平台)可用。不过,弄清楚这些内容的工作逻辑并搞清它们如何适合您的应用程序本身就是一个挑战。
3. 嵌入向量的存储方案:随着应用程序的扩展,您需要为嵌入向量找到一个可扩展且更持久的存储解决方案。这正是矢量数据库出现的原因。
一切由我自己来做!
如果真是这样,请记住几件至关重要的事情:
首先,ML与软件工程非常不同:传统的机器学习起源于统计学,这是一个与软件工程非常不同的数学分支。正则化和特征选择等重要的机器学习概念在数学中有很强的基础。虽然用于训练和推理的现代库使得训练和生成嵌入模型变得非常容易,但了解不同的超参数和训练方法如何影响嵌入模型的性能仍然至关重要。
其次,学习使用PyTorch或Tensorflow等框架可能并不简单。的确,这些库大大加快了现代ML模型的训练、验证和部署;而且,另一方面,对于经验丰富的ML开发人员或熟悉HDL的程序员来说,构建新模型或实现现有模型也是很直观的。但是,尽管如此,对于大多数软件开发人员来说,此领域涉及的基本概念本身可能就很难掌握。当然,还有一个问题就是选择哪个框架的问题,因为这两个框架使用的执行引擎存在很多不同(我推荐你使用PyTorch)。
最后,找到一个适合你的代码库的MLOps平台也需要时间。总之,有数百种不同的选择可供你选择。当然,仅仅评估每种选择方案的利弊本身就可能是一个长达数年的研究项目。
说到这里,我不建议你学习ML和MLOps;因为这是一个相对漫长而乏味的过程,可能会从你手头最重要的事情上争夺时间。
用Towhee加速数据科学应用开发
Towhee是一个开源项目,旨在帮助软件工程师开发和部署只需几行代码就可以利用嵌入模型的应用程序。Towhee项目为软件开发人员提供了构建其ML应用程序的自由和灵活性,而无需深入嵌入模型和机器学习。
一个简单的例子
一个管道(Pipeline)是由多个子任务(在Towhee中也称为操作符)组成的单个嵌入生成任务。通过在管道中抽象整个任务,Towhee可以帮助用户避免上面提到的许多嵌入生成时遇到的许多陷阱。
>>> from towhee import pipeline
>>> embedding_pipeline = pipeline('image-embedding-resnet50')
>>> embedding = embedding_pipeline('https://docs.towhee.io/img/logo.png')
在上面的例子中,图像解码、图像变换、特征提取和嵌入规范化是编译到单个管道中的四个子步骤——开发人员无需担心模型和推理细节。此外,Towhee还为各种任务提供预构建的嵌入管道,包括音频/音乐嵌入、图像嵌入、面部嵌入等。
方法链式API调用
Towhee还提供了一个名为DataCollection的Python非结构化数据处理框架。简而言之,DataCollection是一种方法链接式API,它允许开发人员在真实数据上快速原型化嵌入和其他ML模型。在下面的示例中,我们使用resnet50嵌入模型来使用DataCollection计算嵌入。
在本例中,我们将构建一个简易应用程序。此程序中,我们可以使用1位数字3来过滤素数:
>>> from towhee.functional import DataCollection
>>> def is_prime(x):
... if x <= 1:
... return False
... for i in range(2, int(x/2)+1):
... if not x % i:
... return False
... return True
...
>>> dc = (
... DataCollection.range(100)
... .filter(is_prime) #第一阶段:查找素数
... .filter(lambda x: x%10 == 3) #第二阶段:查找以3结尾的素数
... .map(str) #第二阶段:转换成字符串
... )
...
>>> dc.to_list()
借助DataCollection,你可以使用仅仅一行代码来开发整个应用程序。例如,下面内容中将向你展示如何开发一个反向图像搜索应用程序。
Towhee训练
如上所述,完全或自我监督的训练模型通常擅长用于完成一般性任务。然而,有时你会想要创建一个嵌入模型,它擅长于某些特定的东西,例如区分猫和狗。为此,Towhee专门提供了一个训练/微调框架:
>>> from towhee.trainer.training_config import TrainingConfig
>>> training_config = TrainingConfig(
... batch_size=2,
... epoch_num=2,
... output_dir='quick_start_output'
... )
您还需要指定一个要训练的数据集:
>>> train_data = dataset('train', size=20, transform=my_data_transformer)
>>> eval_data = dataset('eval', size=10, transform=my_data_transformer)一切就绪后,从现有操作符训练一个新的嵌入模型就是小菜一碟了:
>>> op.train(
... training_config,
... train_dataset=train_data,
... eval_dataset=eval_data
... )
一旦完成上面代码后,您可以在应用程序中使用相同的运算符,而无需更改其余代码。


上图中显示的是一幅嵌入模型试图编码的图像核心区域的注意力热图。在Towhee的未来版本中,我们会直接将注意力热图和其他可视化工具集成到我们的微调框架中。
示例应用程序:反向图像搜索
为了演示如何使用Towhee,让我们快速构建一个小型反向图像搜索应用程序。反向图像搜索是众所周知的。所以,我们不再赘述有关细节,而是直接切入主题:
>>> import towhee
>>> from towhee.functional import DataCollection
我们将使用一个小数据集和10个查询图像。程序中,我们使用DataCollection实现加载数据集和查询图像:
>>> dataset = DataCollection.from_glob('./image_dataset/dataset/*.JPEG').unstream()
>>> query = DataCollection.from_glob('./image_dataset/query/*.JPEG').unstream()下一步是在整个数据集集合上计算嵌入:
>>> dc_data = (
... dataset.image_decode.cv2()
... .image_embedding.timm(model_name='resnet50')
... )
...
这一步创建了一组局部的嵌入向量——每个向量对应于数据集中的一个图像。现在阶段,我们就可以查询最近的邻居数据了:
>>> result = (
... query.image_decode.cv2() #解码查询集中的所有图像
... .image_embedding.timm(model_name='resnet50') #使用'resnet50'嵌入模型计算嵌入
... .towhee.search_vectors(data=dc_data, cal='L2', topk=5) #搜索数据集
... .map(lambda x: x.ids) #获取类似结果的ID(文件路径)
... .select_from(dataset) #获取结果图像
... )
...
此外,我们还提供了一种使用Ray框架部署应用程序的方法。为此,你只需要调用一下命令query.set_engine('ray'),其他一切就好办了!
总结
最后,我们不认为Towhee项目是一个成熟的端到端模型服务或MLOps平台,而且这也不是我们打算实现的目标。相反,我们的目标是加速需要嵌入和其他ML任务的应用程序的开发。不过,借助Towhee开源项目,我们希望能够在本地机器(Pipeline+Trainer)上实现嵌入模型和管道的快速原型化,特别是只需几行代码就可以开发以ML为中心的应用程序(数据收集),并允许轻松快速地部署到集群(通过Ray框架)上。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
原文标题:Making Machine Learning More Accessible for Application Developers,作者:Frank Liu
链接:https://dzone.com/articles/making-machine-learning-more-accessible-for-applic-1