












如今,许多数据库即服务(DBaaS)解决方案将计算层和存储层分开来,比如包括Amazon Aurora和Google BigQuery。由于数据存储和数据复制可以由现有服务来处理,DBaaS无需担心这种复杂性,这种解决方案很有吸引力。然而,这种设计的性能有时可能不如传统方式:使用本地磁盘作为存储。
本文将介绍如何认真选择弹性块存储(EBS)类型,辅以巧妙的优化,在EBS上部署DBaaS可以获得比在本地磁盘上更好的性能。
为什么要考虑EBS?
为了解释我们使用EBS的动机,先简单介绍一下TiDB。TiDB是一种与MySQL兼容的分布式数据库。TiDB Server是处理SQL请求的计算节点。Placement Driver(PD)则是TiDB的大脑,负责配置负载均衡,并提供元数据服务。TiKV是一种面向行的键值存储系统,处理事务查询。TiFlash是处理分析查询的列存储扩展。本文主要介绍TiKV。

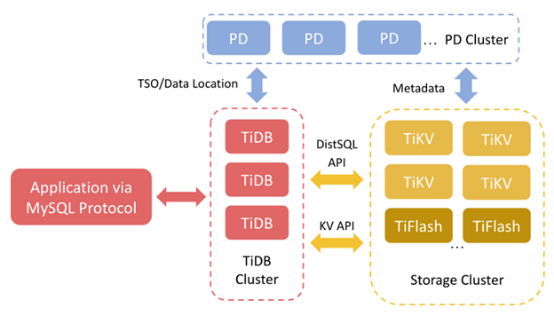
图1
TiKV提供分布式键值服务。首先它将数据拆分成几个Region,这是用于复制和负载均衡的最小数据单元。为了实现高可用性(HA),每个Region被复制三次,然后分布在不同的TiKV节点中。一个Region的副本构成一个Raft组。TiDB可以接受这种情形:失去一个节点,从而在一些Region中失去一个副本。但是,同时失去两个副本会导致问题,因为Raft组的大多数成员都失去了。因此Region不可用,无法再访问其数据。需要人为干预来解决这类问题。

图2
在部署TiDB Cloud时,我们有放置规则,保证一个Region的副本会分布在多个可用区(AZ)。失去一个可用区(AZ)不会对TiDB Cloud产生巨大影响。然而,如果出现AZ + 1故障(即一个可用区和另一个可用区中的至少一个节点同时出现故障),该Region将变得不可用。我们在生产环境中遇到过这样的故障,花了好大的精力才让TiDB集群恢复正常。为了避免再次遭遇这种痛苦的经历,EBS进入了我们的视线。
AWS Elastic Block Store(EBS)是AWS提供的一种块存储服务,可以附加到EC2实例上。然而,EBS上的数据独立于EC2实例,因此当EC2实例出现故障时,数据持续存在。当EC2实例出现故障时,可以使用Kubernetes,将EBS自动重新挂载到正常工作的EC2实例。此外,EBS卷是为关键任务系统设计的,因此它们可以在AZ内复制。这意味着EBS不太可能出故障,因此我们就放心了。
选择合适的EBS卷类型
基于SSD的EBS卷通常有四种类型:gp2、gp3、io1和io2。(我们在设计和实现TiDBCloud时,io2 Block Express还处于预览模式,所以我们没有考虑它。)下表总结了这些卷类型的特点。
卷类型 | 耐久性 (%) | 带宽 (MB/s) | IOPS (每GB) | 成本 | 说明 |
gp2 | 99.8-99.9 | 250 | 3,突发式 | 低 | 通用卷 |
gp3 | 99.8-99.9 | 125-1000 | 3000-16000 | 低 | 通用卷,有灵活的带宽 |
io1 | 99.8-99.9 | 多达1000 | 多达64000 | 高 | 高IOPS |
io2 | 99.999 | 多达1000 | 多达64000 | 高 | 高IOPS,性能最佳 |
这里可以进行对比。注意在下面图中,四种类型的EBS卷附加到了r5b实例,而本地磁盘上的一番测量是在i3实例上进行的。这是由于r5b实例只能使用EBS。我们使用i3作为相仿的替代选择。每个图显示了所有操作的平均延迟和第 99个百分位延迟。
我们从读写延迟开始横向比较。第一个工作负载很简单。它有1000 IOPS,每个I/O为4 KB。以下两张图显示了平均延迟和第99个百分位延迟。

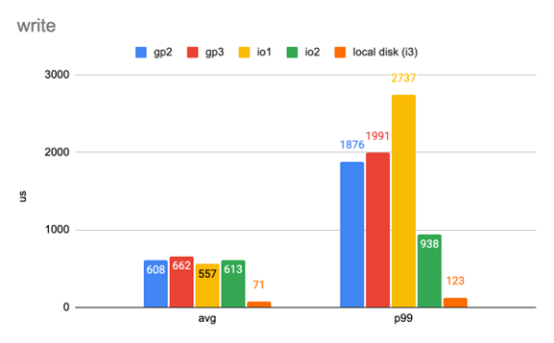
图3
只有一个线程的简单工作负载的写延迟。(数字越小越好)

图4
只有一个线程的简单工作负载的读延迟。(数字越小越好)
我们使用类似的设置设计了类似的工作负载。这次我们使用8个线程为磁盘提供总共3000个IOPS,每个I/O仍然是4 KB。同样,我们概述了平均延迟和第99个百分比延迟,并绘制成以下两图。

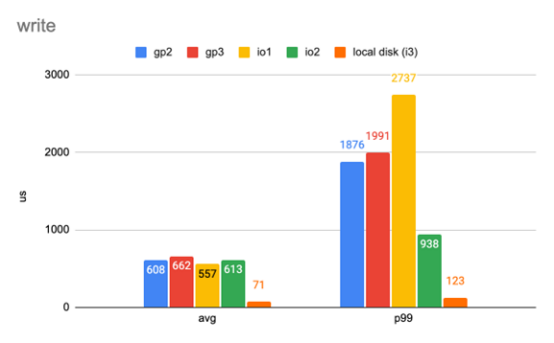
图5
有八个线程的简单工作负载的写延迟。(数字越小越好)

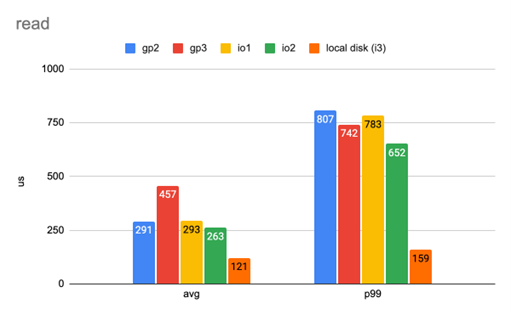
图6
有八个线程的简单工作负载的读延迟。(数字越小越好)
从前面两个实验来看,本地磁盘似乎更胜一筹。真是这样吗?这是另一个基准测试,显示的情况略有不同。我们设计了混合工作负载来模拟TiKV IO的使用:有小的顺序写入来模拟前台预写式日志(WAL)写入,还有大量的顺序写入来模拟压缩写入。回想一下,TiDB使用RocksDB作为存储引擎。RocksDB基于日志结构化合并树(LSM 树),它定期压缩最近写入的数据。我们也有小的随机读取来模拟前台读取。
我们发现,当后台I/O变得更密集时,前台延迟增加,本地磁盘和EBS之间的延迟差距会变小,见下图。

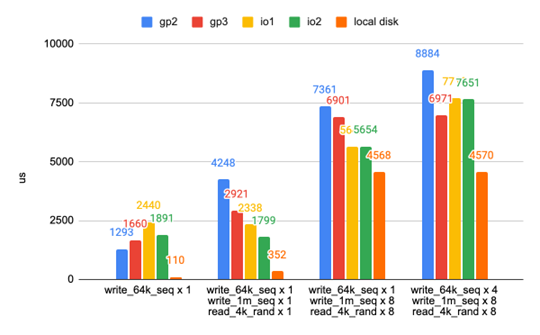
图7. 一些综合工作负载的平均操作延迟。(数字越小越好)
我们针对TiDB运行TPC-C工作负载(这是更全面的基准测试)后,EBS 和本地磁盘之间的性能差距变得更小了。下图显示了结果。使用的TiDB版本是v5.0.0。我们在EBS卷类型不一的r5b.2xlarge实例上或使用本地nvme磁盘的i3.2xlarge实例上部署了三个TiKV节点。TiDB 节点、Placement Driver(PD)和TPC-C客户端部署在c5.4xlarge实例上。我们在实验环境中使用了5000个仓库(大约350 GB数据),分别有50个、200个和800个客户端。结果显示在以下三个图中。第一个图显示了TPC-C工作负载中的每分钟事务数(TPMC)。第二个图显示了事务的平均延迟,以毫秒为单位。第三个图显示了第99个百分位延迟,以毫秒为单位。

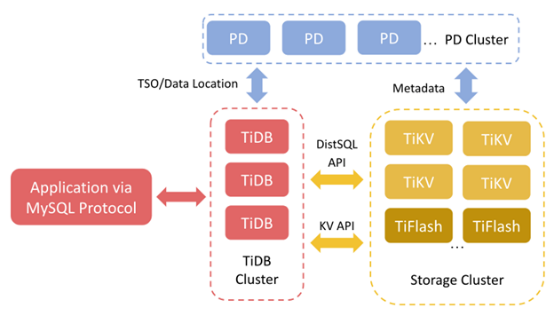
图8. TPC-C工作负载中的每分钟事务(TPMC)。(数字越大越好)

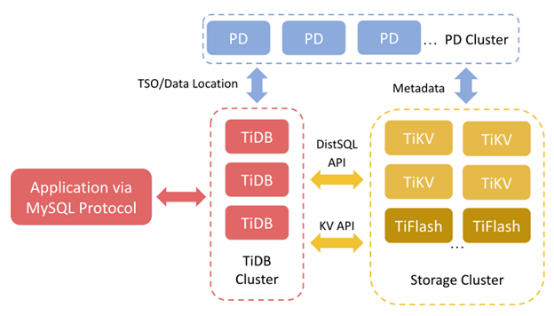
图9. TPC-C 工作负载中的平均操作延迟(ms)。(数字越小越好)

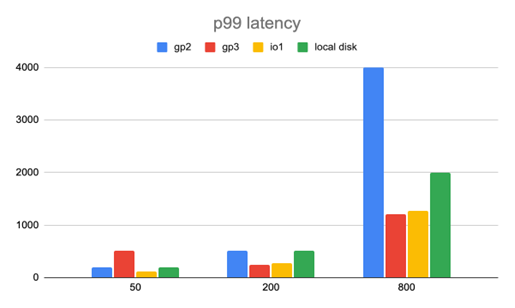
图10. TPC-C 工作负载中的第99个百分位操作延迟(ms)。(数字越小越好)
通常来说,我们可以看到使用EBS的实例可以达到与使用本地磁盘的实例相仿的性能,有时甚至更好。这是由于TiKV在这个工作负载中是CPU受限的,在我们尝试过的其他许多基准测试中也是如此。I/O性能不是瓶颈。由于带EBS的实例类型是r5b,它的CPU比带本地磁盘的实例类型i3更好,性能结果看起来相仿,甚至更好。
此外,在第三个图中(TPC-C工作负载中的第99个百分位操作延迟),有800个线程时,EBS卷类型gp2的第99个百分位延迟飙升。这是由于就gp2而言,带宽达到了极限。
最后,我们选择gp3作为EBS类型。EBS卷io2并不在我们的考虑范围之内,因为在当初设计和实现TiDB Cloud时,r5b实例无法使用它。此外,当时io2 block express仍处于预览模式。EBS卷io1的延迟整体上与gp2相当,io1提供了更高的带宽IOPS限制。然而,io1有基于预置IOPS的额外成本。EBS卷gp2的带宽和IOPS有限,而且无法配置。这给TiDB带来了额外的限制。因而,我们选择了gp3。
原文标题:Improve Performance and Data Availability with Elastic Block Store (EBS),作者:Bokang Zhang
链接:















