














大家好,我是皮皮。
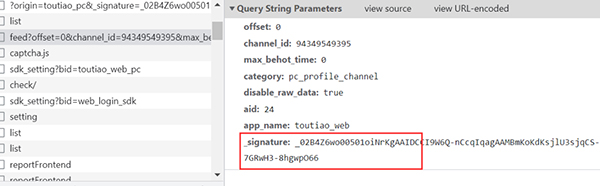
1、这里使用的网站是fec2bc913be604a5162540c03d45532c,MD5加密处理过的。
2、需要抓取首页相关信息,如下图所示。
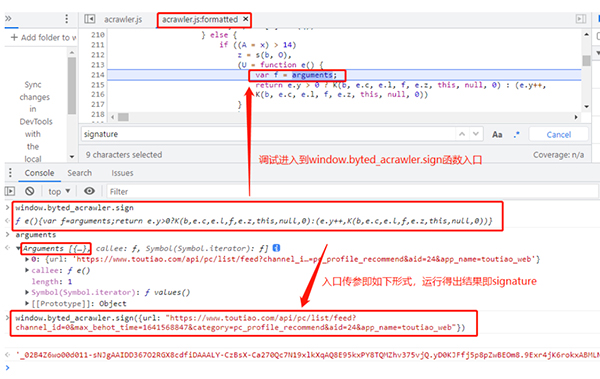
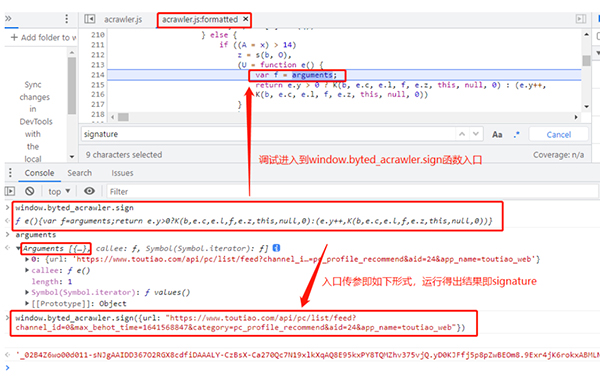
3、打开浏览器抓包,然后打断点调试,依次点击右边的Call Stack内的东西,直到找到加密函数,里边的值对应请求参数即可判定。仔细寻找,发现加密的函数在这里了。下图直接用的是十一姐的图,十一姐文章原文链接:
https://blog.csdn.net/weixin_43411585/article/details/123030973
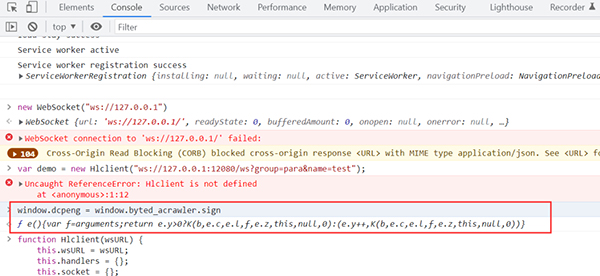
4、之后可以在控制台输入指令window.dcpeng = window.byted_acrawler.sign,其中window.byted_acrawler.sign为加密函数。注意:这个地方挺重要的,很多时候我们会写成ct.update(),这样会有问题!加了括号就是赋值结果,没加就是赋值整个函数!千差万别。
5、关闭网页debug模式。注意:这个地方挺重要的,很多时候如果不关闭,ws无法注入!
6、此时在本地双击编译好的文件win64-localhost.exe,启动服务。
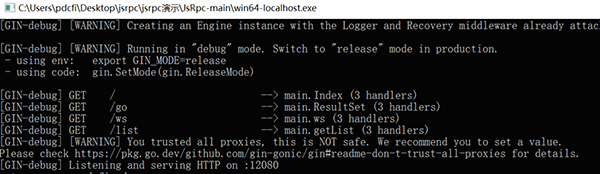
7、之后在控制台注入ws,即将JsEnv.js文件中的内容全部复制粘贴到控制台即可(注意有时要放开断点)。
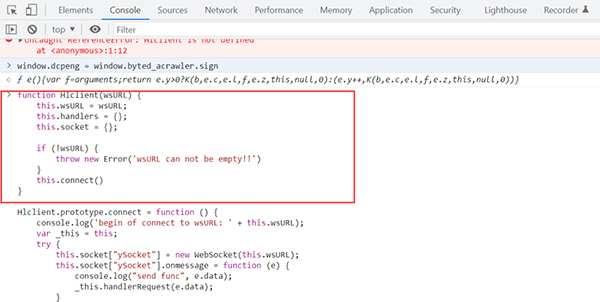
8、连接通信,在控制台输入命令var demo = new Hlclient("ws://127.0.0.1:12080/ws?group=para&name=test");
9、随后继续输入命令:
// 注册一个方法 第一个参数get_v为方法名,
// 第二个参数为函数,resolve里面的值是想要的值(发送到服务器的)
// param是可传参参数,可以忽略
demo.regAction("get_para", function (resolve, param) {
console.log(param);
var res = dcpeng(param, {"url":"https://www.toutiao.com/?wid=1641423780855"});
resolve(res);
})
这个地方要记得传参,不然你拿不到数据的。(这里排查了好久才出来)
10、之后就可以在浏览器中访问数据了,打开网址 http://127.0.0.1:12080/go?group={}&name={}&action={}¶m={} ,这是调用的接口 group和name填写上面注入时候的,action是注册的方法名,param是可选的参数,这里续用上面的例子,网页就是:http://127.0.0.1:12080/go?group=para&name=test&action=get_para

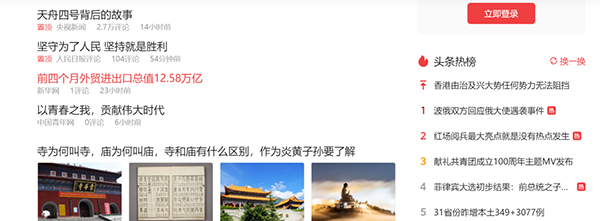
11、如上图所示,我们看到了那个变化的参数v的值,直接通过requests库可以发起get请求。
12、现在我们就可以模拟数据,进行请求发送了。
13、将拷贝的内容可以丢到这里进行粘贴:http://tool.yuanrenxue.com/curl
14、之后将右侧的代码复制到Pycharm中即可用,非常便利。
15、之后就可以构造请求了,加一个整体循环,然后即可获取翻页的内容,整体代码如下所示。
# coding:utf-8
# @Time : 2022/5/10 16:30
# @Author: 皮皮
# @公众号: Python共享之家
# @website : http://pdcfighting.com/
# @File : 头jsrpc.py
# @Software: PyCharm
import requests
import json
import urllib.parse
import time
param_url = "http://127.0.0.1:12080/go?group=para&name=test&action=get_para"
response = requests.get(url=param_url).text
response_json = json.loads(response)
sign = response_json["get_para"]
print(sign)
behot_time = int(time.time())
params = {
"offset": 0,
"channel_id": 0,
"max_behot_time": 1641416108,
"category": "pc_profile_recommend",
"aid": 24,
"app_name": "toutiao_web",
"disable_raw_data": "true",
"_signature": sign
}
url = f'https://www.toutiao.com/api/pc/list/feed'
response_detail = requests.get(url, params=params).json()
print(response_detail["data"])
运行结果如下图所示,和网页上呈现的数据一模一样。
16、至此,请求就已经完美的完成了,如果想获取全部网页,构造一个range循环翻页即可实现。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
















