













哲学
最近看到了一句话:定乎内外之分 辩乎荣辱之境。
一个外国作家也说过:
我生命里的的最大突破之一,就是我不再为别人的看法而担忧。此后,我真的能自由的去做我认为对自己最好的事,只有在我们不需要外来的赞许时,才变得自由。
说的都很好。人就是要突破自己,就像许三多,不要在意别人的看法,做自己认为有意义的事,今天比昨天好,这不就是希望。
监控
思考完一波哲学,开始搞搞软件上的东西。这篇记录下监控配置相关的知识。
为什么需要监控系统:简单点说。随时掌握系统运行情况,保证在你预期内运行。
先不扯别的,看两张效果图:
1、监控Linux服务器的CPU,内存,磁盘等:
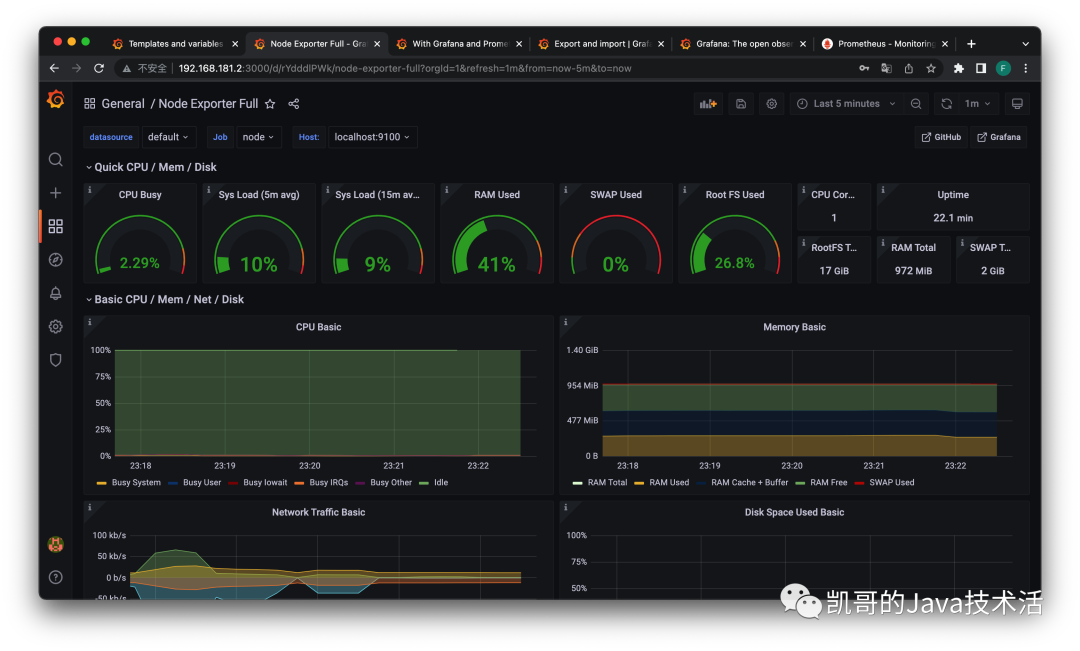
2、监控Tomcat和jvm:
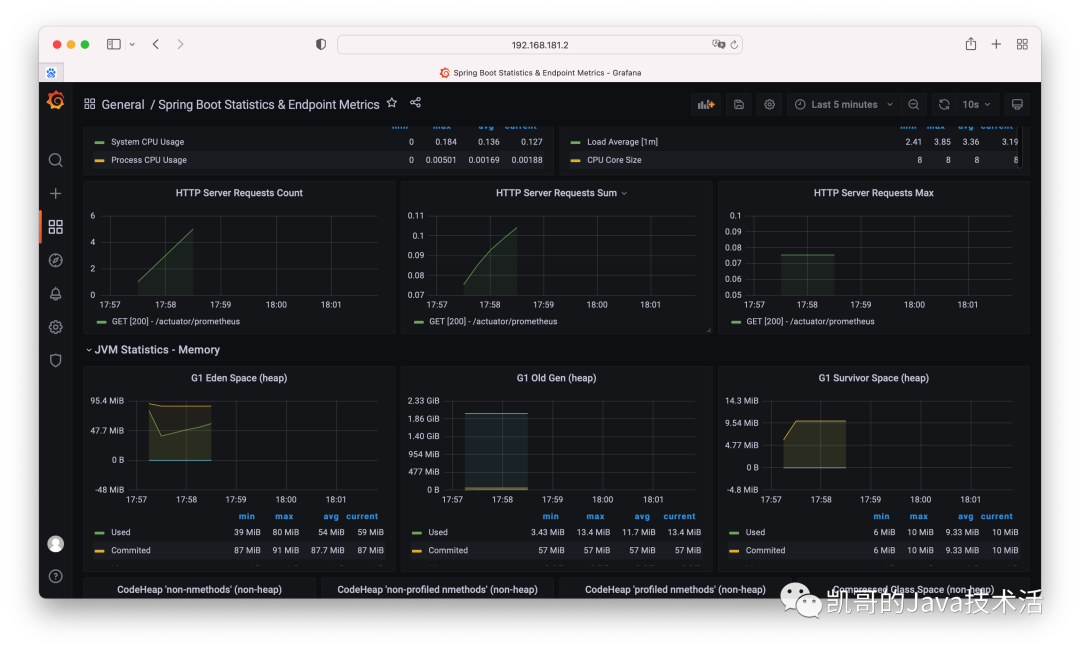
概念
1、Prometheus是什么,一款开源的优秀的时间序列数据库监控软件。收集各项指标,用于监控系统状态。提供强大的PromQL查询语句,满足各种个性化查询需求。
2、什么是Metrics,Metrics就是监控指标,在外行术语中,指标是数字度量,时间序列意味着随着时间的推移记录变化。用户想要测量的内容因应用程序而异。对于web服务器来说,它可能是请求时间,对于数据库,它可能是活动连接数或活动查询数等。简单理解,就是你想监控的东西,不必过分深究。
3、Grafana又是什么?简单来说就是图形化展示工具,和Prometheus天作之合。
安装配置
1、下载prometheus:
wget https://github.com/prometheus/prometheus/releases/download/v2.35.0/prometheus-2.35.0.linux-amd64.tar.gz
tar xvfz prometheus-*.tar.gz
cd prometheus-*
2、配置prometheus:
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'codelab-monitor'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
# 这里这个就是自带的监控,监控preometheus自己
- targets: ['localhost:9090']
以上就完成了prometheus的下载和配置,非常的简单。
访问host:9090就可以看到如下界面:
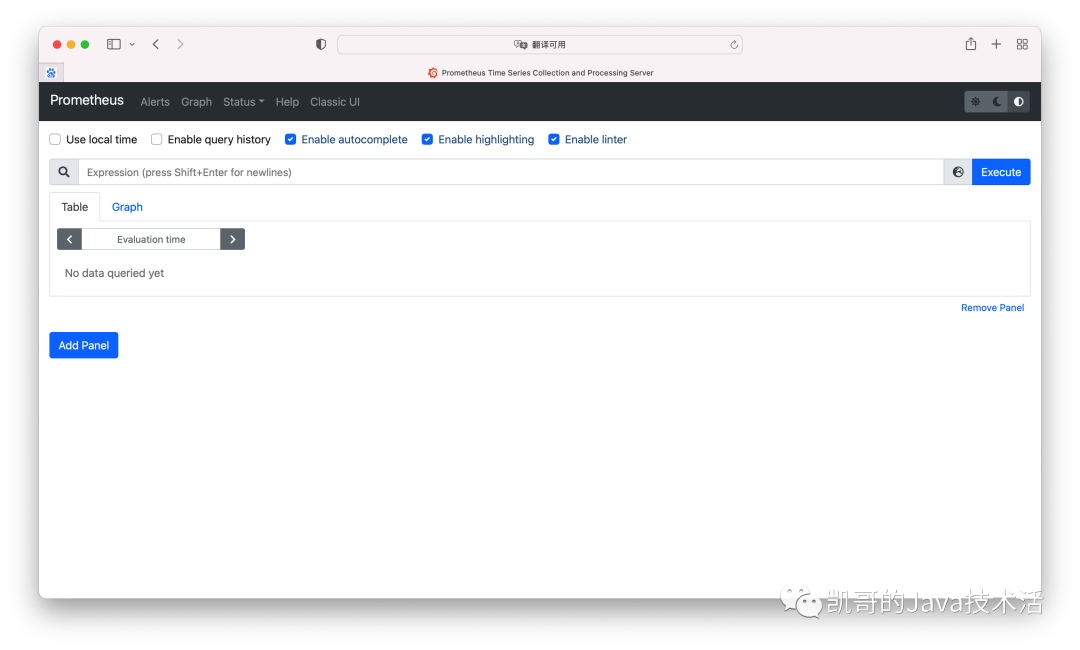
这就是prometheus的管理页面。不够酷炫,接下来下载grafana。
3、下载grafana
sudo yum install grafana
sudo systemctl start grafana-server
这就完事了。验证下,默认的管理端是运行在3000端口,也就是http://ip:3000,就可以打开如下页面,账号密码默认都是admin。
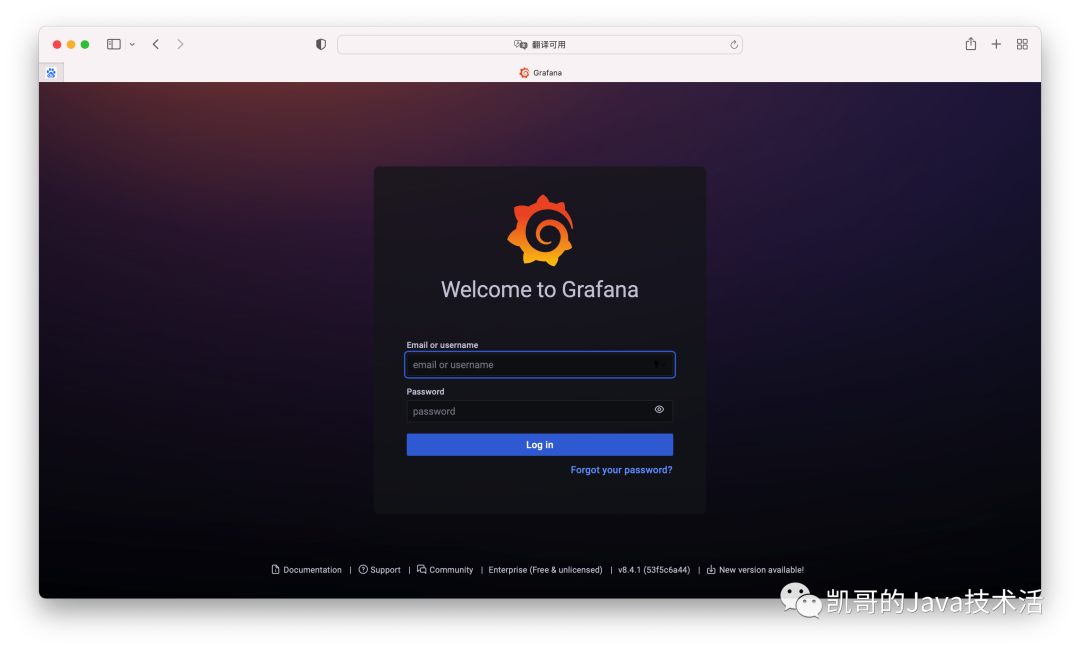
我们现在有了prometheus和grafana,接下来将grafana连上prometheus。
1、添加数据源。
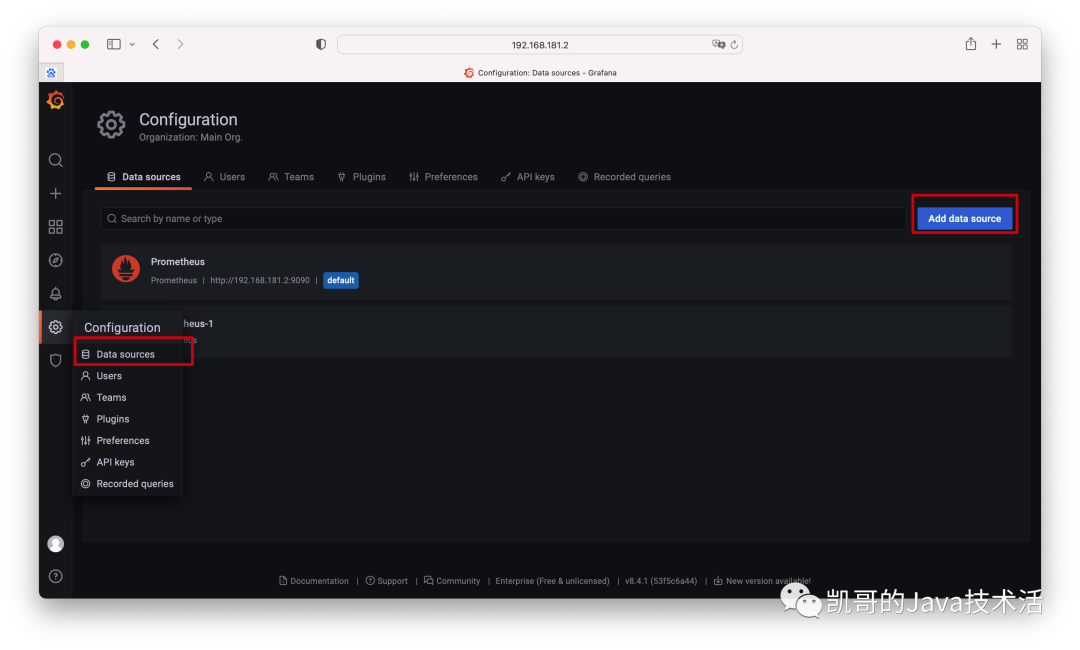
2、连接上prometheus。
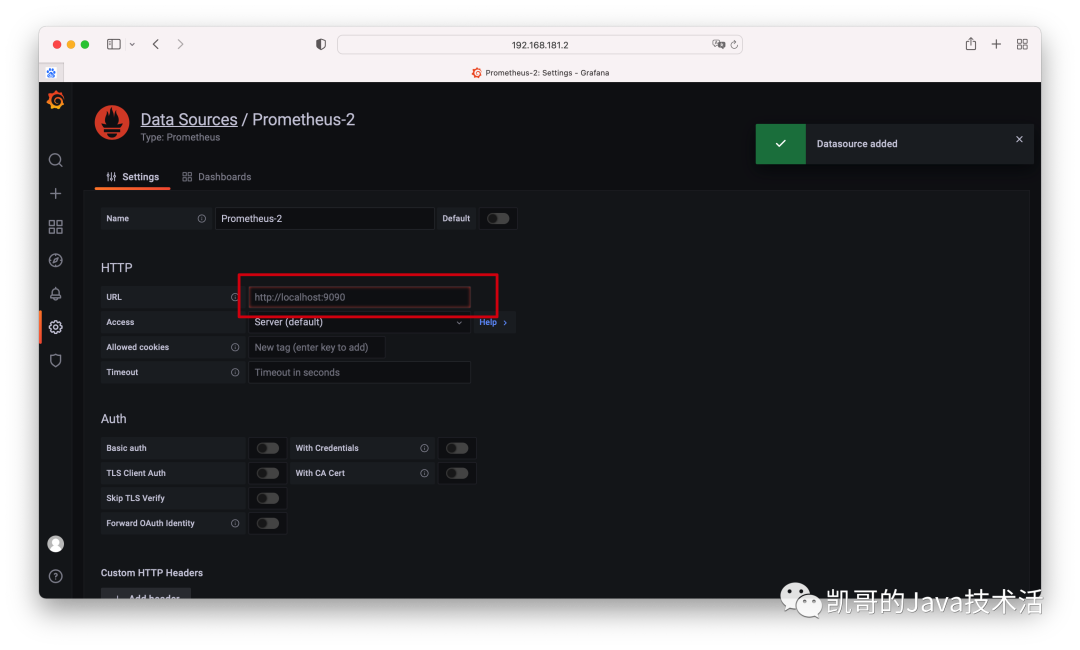
3、测试是否连接成功。
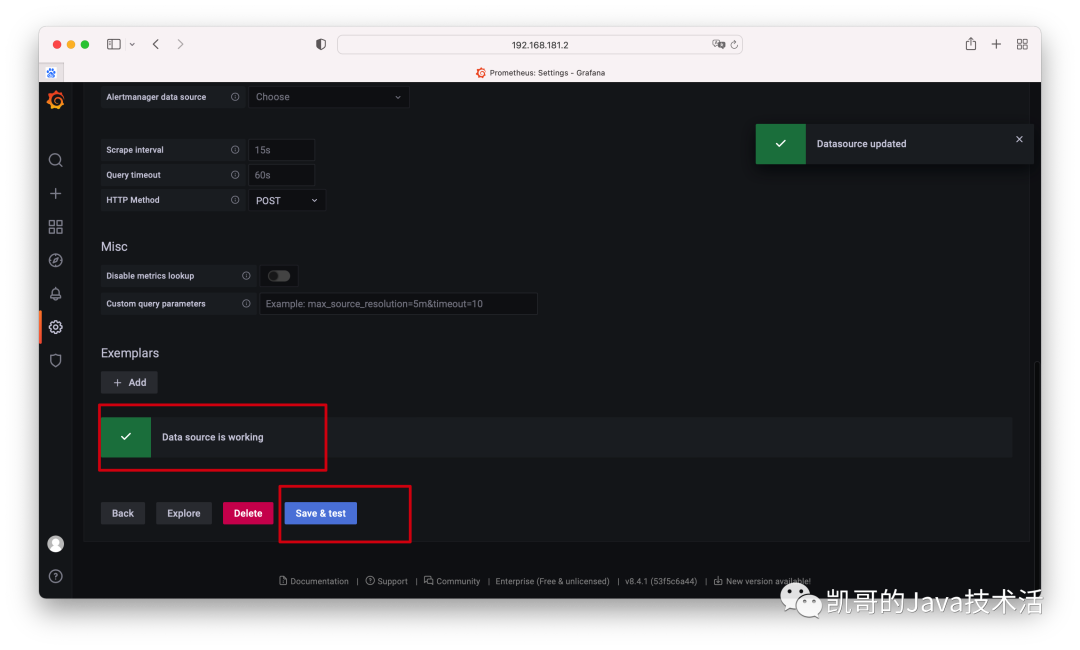
这就完成了。截止到现在,最基本prometheus和grafna下载和安装的操作就完毕了。
exporter
接下来,来监控linux的状态。这个也是极其的简单。
首先下载node_exporter,然后启动
wget https://github.com/prometheus/node_exporter/releases/download/v*/node_exporter-*.*-amd64.tar.gz
tar xvfz node_exporter-*.*-amd64.tar.gz
cd node_exporter-*.*-amd64
./node_exporter
再去prometheus修改下配置文件prometheus.yaml,仿照之前的,加上下面的配置。然后重启prometheus。
- job_name: node
static_configs:
- targets: ['localhost:9100']
这样已经有了监控linux运行情况的能力了,只是目前还没有展示出来而已。
接下来加上酷炫的页面。官网有配置好的,甚至不用自己配置。地址是:
https://grafana.com/grafana/dashboards/。
打开如下,搜索node,选中第一个。
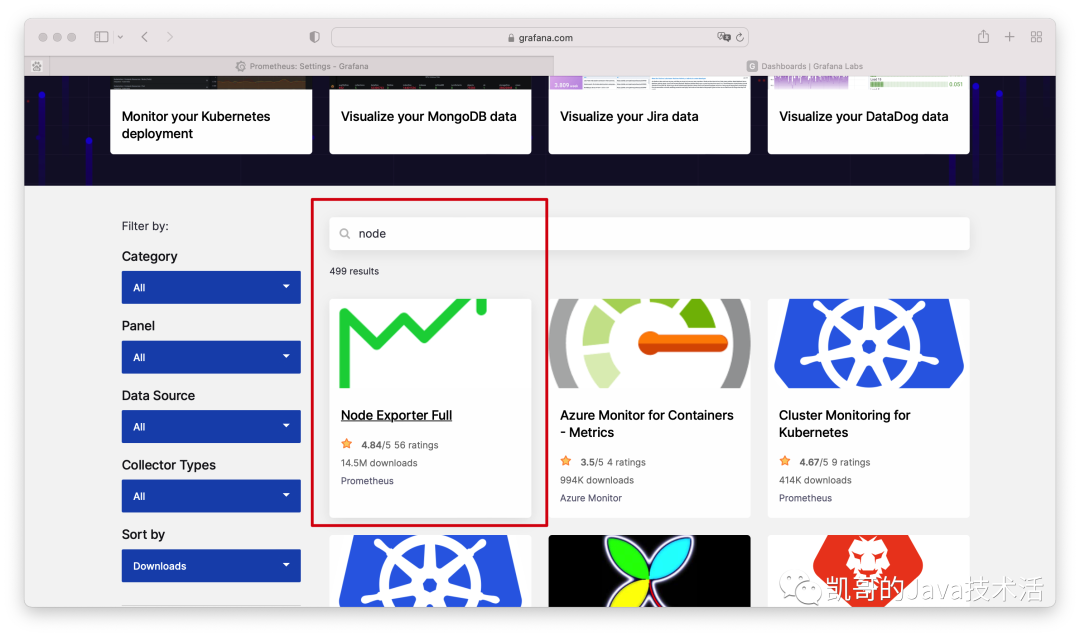
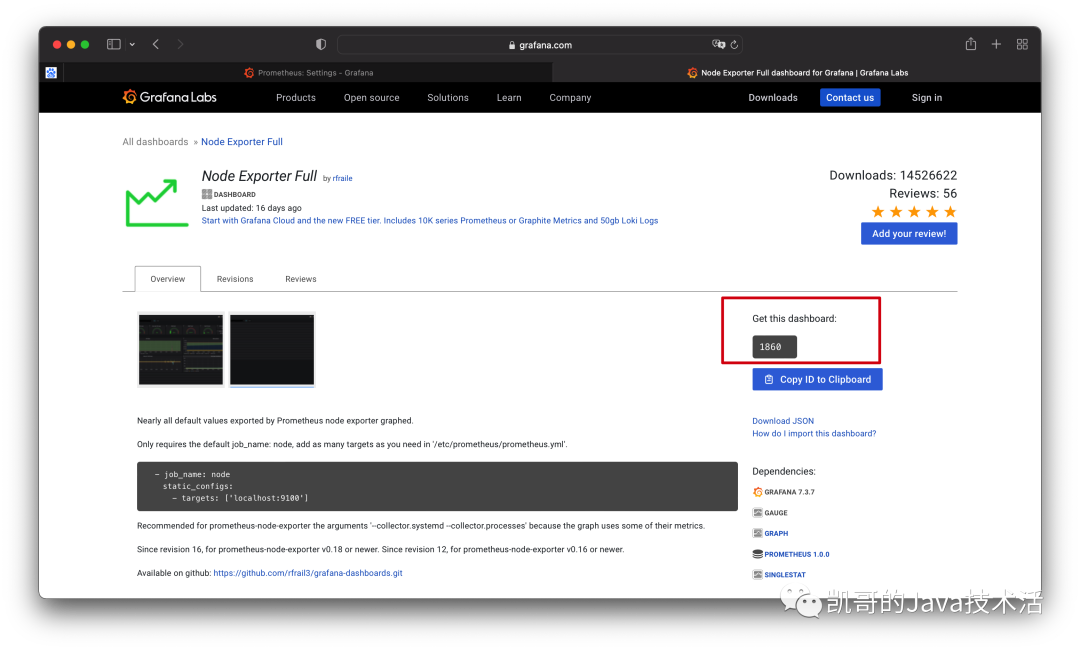
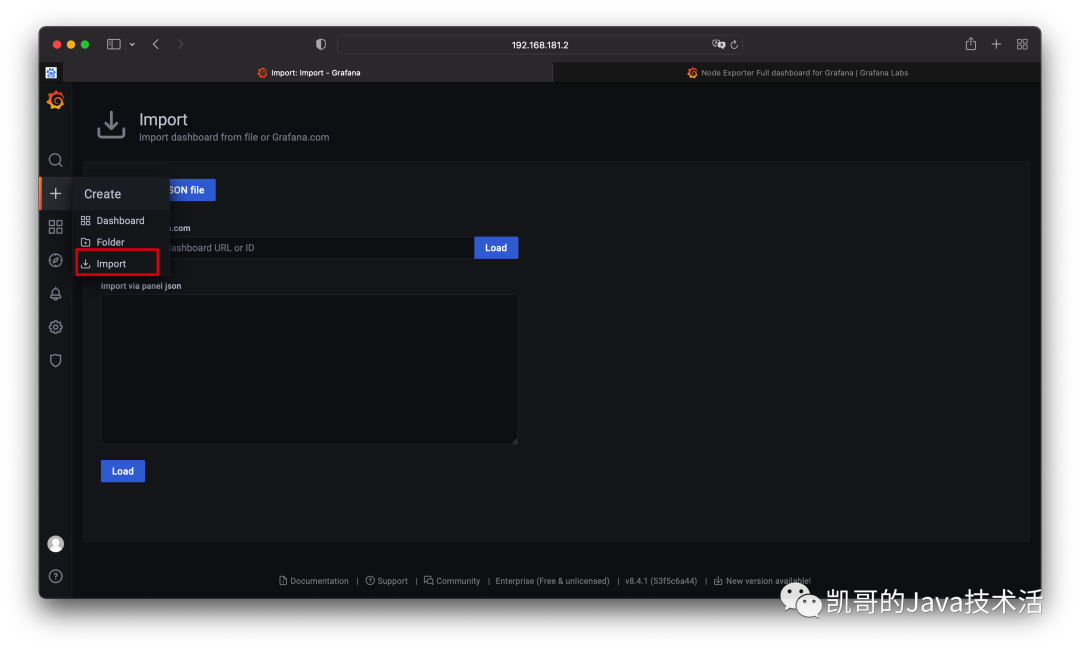
复制官方提供的模板ID。然后去grafana导入一下即可。
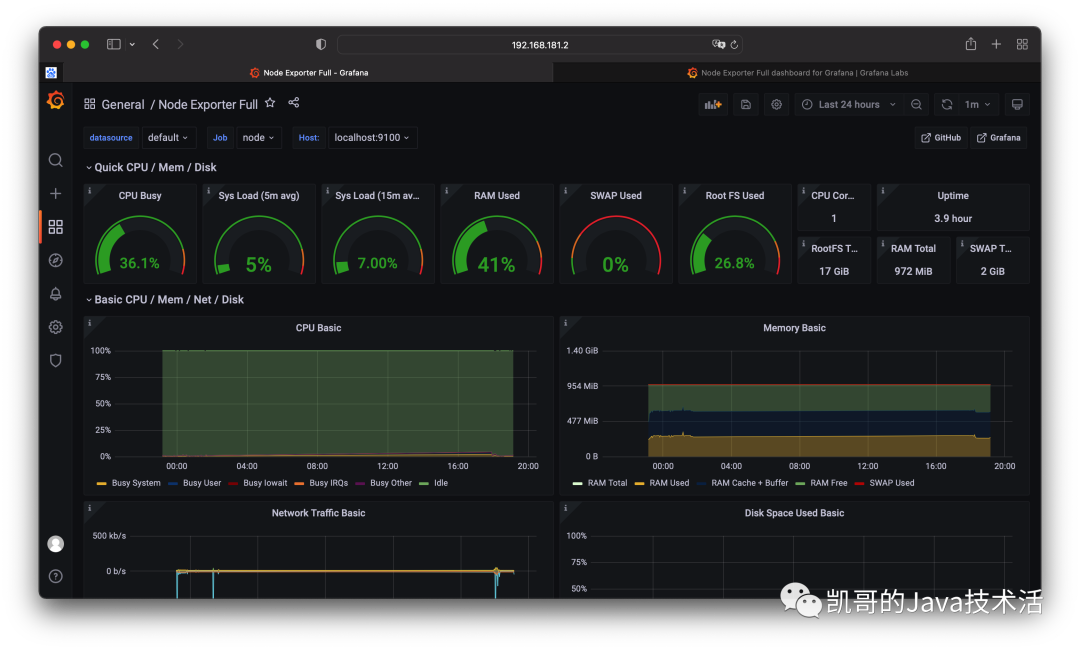
大功告成了,如下图所示。
jvm的也是类似的操作,自己可以试验。
自定义监控指标
以上都是官方提供的exporter。监控机器或者jvm的,如果我们想监控自己的业务呢?例如想监控当前有多少请求?每个请求的性能如何?或者其他一些自定义的监控项?
在写代码之前,认识几个概念:prometheus中的四种指标类型。Counter(计数器):Counter类型用于增加的值,例如请求计数或错误计数。最重要的是,绝对不能将计数器用于可能减小的值。只增不减。
Gauges(仪表板(我自己的翻译)):仪表类型可用于向下和向上的值,例如当前内存使用量或队列中的项目数,可增可减。
histogram(直方图):这个概念比较难以理解。暂时我们认为他就是统计分位树的就好。例如你这个接口99%请求的耗时,TP99。
summaries:本篇不讲,感兴趣自行查看官网。
这四种类型,都什么时候使用呢?Counter:
1、你想记录一个只上升的值。
2、希望以后能够查询该值的增长速度(即增长率)。
Guage:
1、想要记录一个可以上升或下降的值。
2、你不需要查询它的增长率。
histogram:分桶计算,分位计算,计算TP99等。
OK,接下来写代码。
监控Spring Boot应用
用java,一般用Spring Boot项目开发,这个很容易实现,全部都是封装好的。
从一个最基本的项目入手,只需要如下的依赖即可。注意到这里除了web模块,还加了两个监控模块。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
然后写一个简单的controller。
package com.test.promethusmetrics;
import io.prometheus.client.CollectorRegistry;
import io.prometheus.client.Counter;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 测试Counter
*
* @author fengkai
*/
@RestController
public class CounterController {
private final Counter requestCount;
public CounterController(CollectorRegistry collectorRegistry) {
requestCount = Counter.build()
.name("request_count")
.help("Number of hello requests.")
.register(collectorRegistry);
}
@GetMapping(value = "/hello")
public String hello() {
requestCount.inc();
return "Hi!";
}
}
注意到这里用了counter。这就完成了counter计数的代码部分。
代码完成后,还需要让prometheus去拉取我们Spring Boot的监控指标,配置和之前很相似。
添加如下配置,然后重启prometheus。
- job_name: "spring"
metrics_path: /actuator/prometheus
static_configs:
- targets: ["192.168.181.1:8080"]
我们在浏览器上多请求几次。然后我们去grafana上配置监控面板,首先添加。
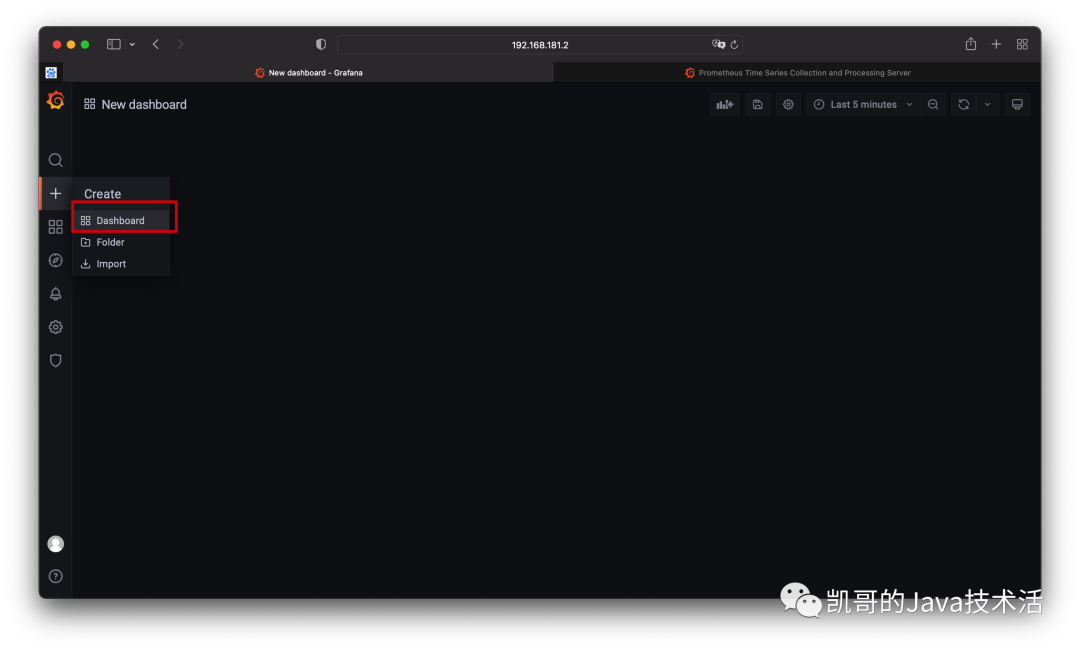
然后配置指标。
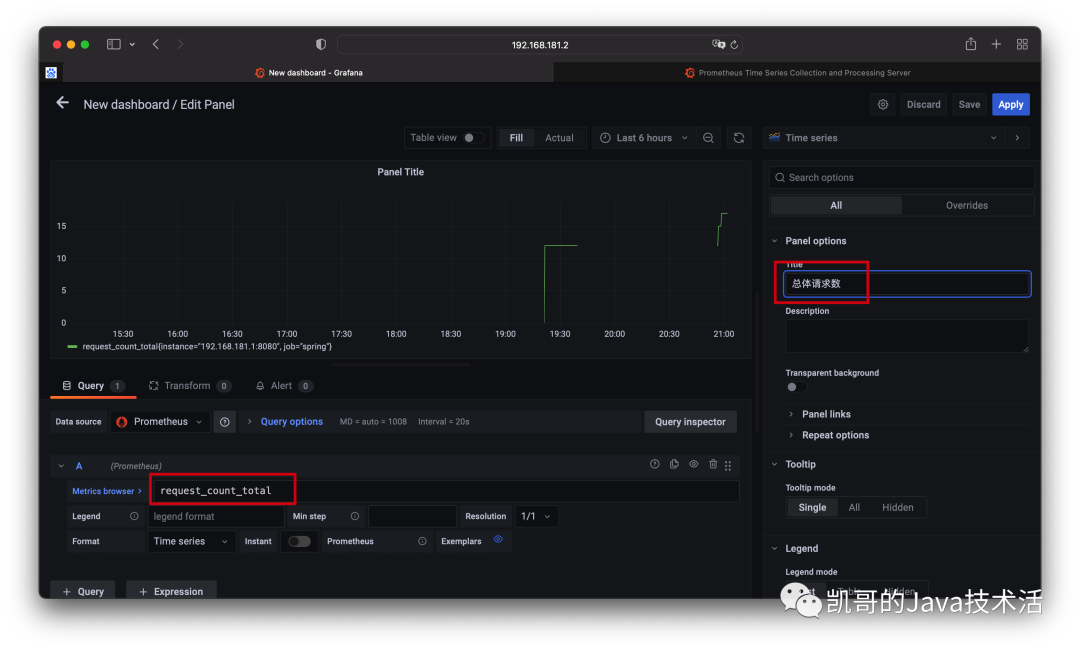
效果图如下。
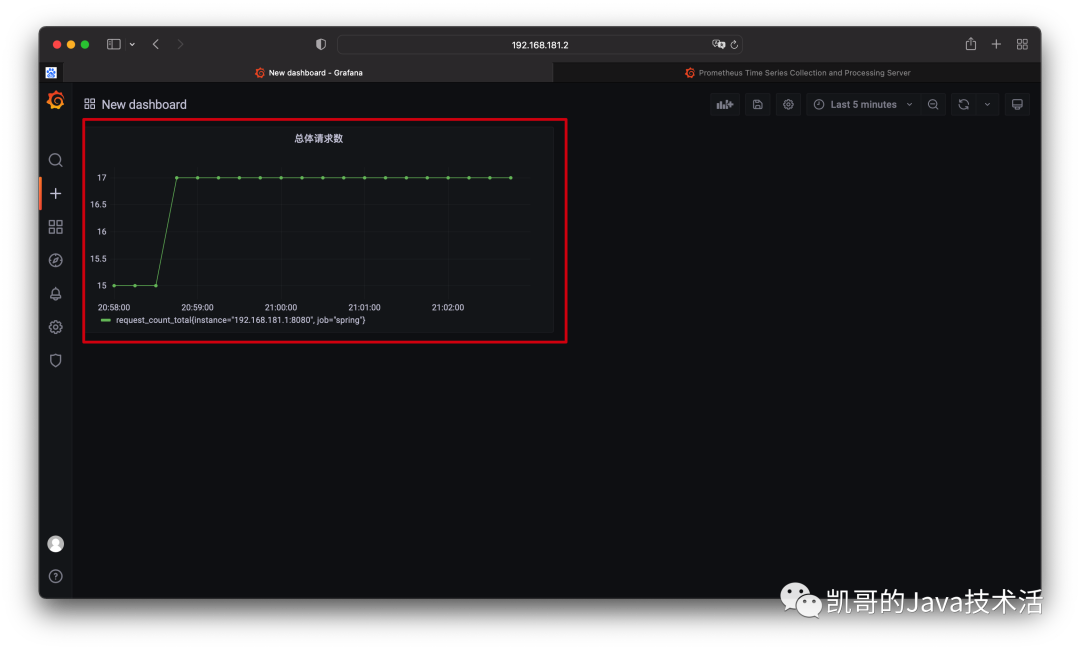
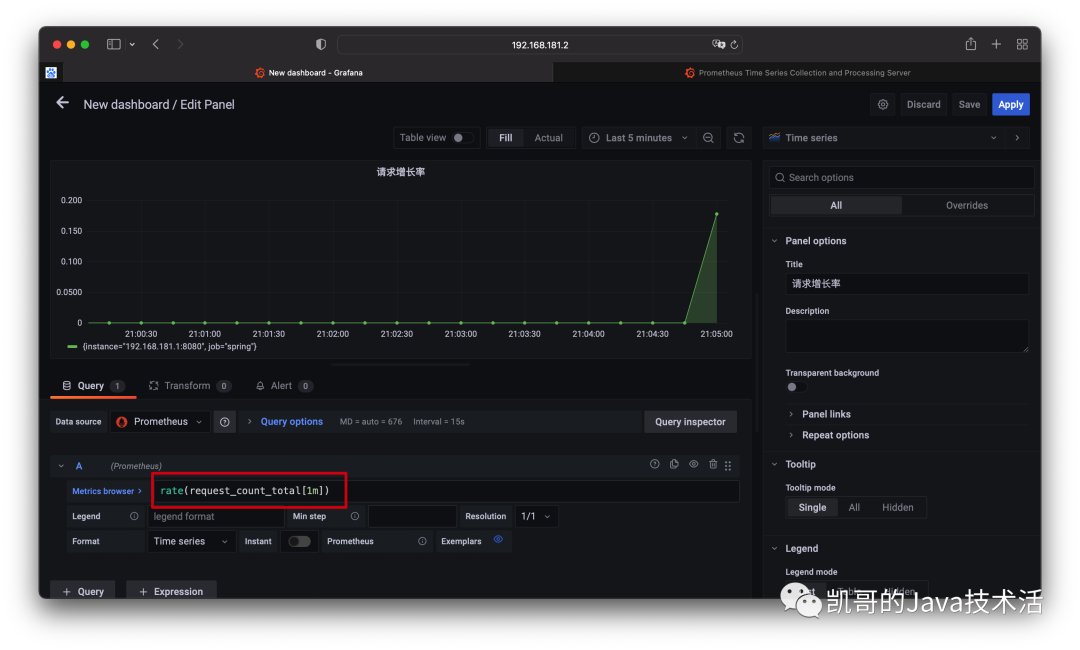
以上只是单纯的计数,实际用途不是很大,其实更关心的应该是增长率。这又该如何统计呢?
只需要在外层包裹rate函数就可以了,具体的原理可以后续再解释,这里先用起来。
接下来再试一下使用histogram,统计下Spring Boot服务的请求的耗时情况如何?
代码部分:
package com.test.promethusmetrics;
import io.prometheus.client.CollectorRegistry;
import io.prometheus.client.Histogram;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import static java.lang.Thread.sleep;
@RestController
public class HistogramController {
private final Histogram requestDuration;
public HistogramController(CollectorRegistry collectorRegistry) {
requestDuration = Histogram.build()
.name("test_wait")
.help("Time for HTTP request.")
.register(collectorRegistry);
}
@GetMapping(value = "/wait")
public String makeMeWait() throws InterruptedException {
Histogram.Timer timer = requestDuration.startTimer();
long sleepDuration = Double.valueOf(Math.floor(Math.random() * 10 * 1000)).longValue();
sleep(sleepDuration);
timer.observeDuration();
return String.format("I kept you waiting for %s ms!", sleepDuration);
}
}
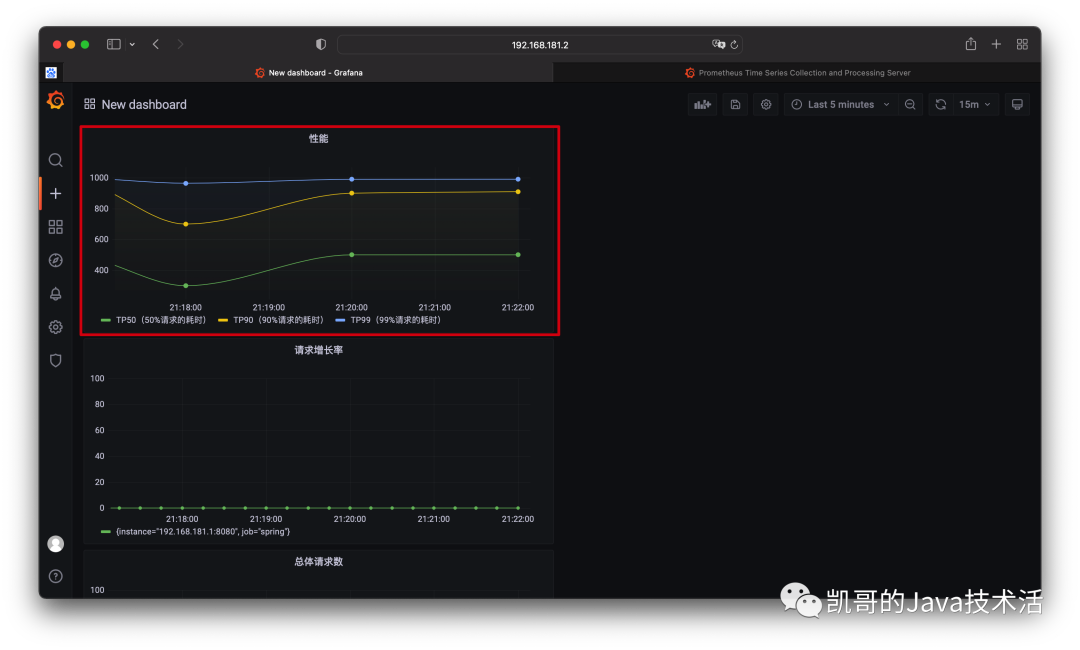
多访问几次:localhost:8080/wait然后grafana配置,这里用的是直方图histogram,计算的性能。QL的语法本篇不讲解,可以参考官网。
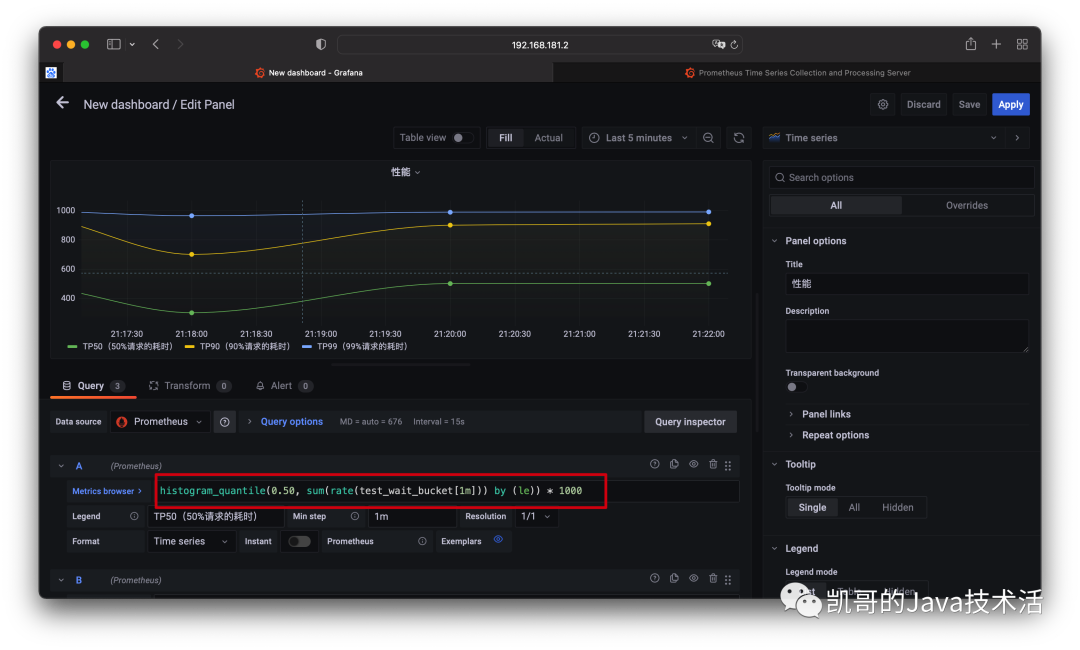
效果图如下:
总结
现在,我们应该清楚地了解prometheus中可以使用的不同监控指标类型,以及何时使用它们,如何查询它们。并且能够用grafna配置酷炫的监控图标。有了这些知识,可以更有效地发布应用程序中的监控,并确保它始终按预期运行。
























