












人工智能近些年的快速发展主要归功于神经网络模型,但随着模型越做越大、越来越复杂,研究人员渐渐也无法完全理解模型究竟是如何做出预测的,「黑匣子」也就变得越来越黑。
能否理解黑盒模型的运行机制对于模型部署来说至关重要,关乎模型的可靠性和易用性,所以也有研究人员正在开发模型的可解释方法。

为了尝试理解模型,之前大多采用测试样例的方法来描述和解释模型的决策过程,比如在情感分析任务中,对电影评论数据高亮显示模型认为正向还是负向的关键词,也叫「局部解释」。
但对于复杂一些的任务,人类可能就没办法轻易理解了,甚至可能会产生误解,那这种解释方法就毫无用处。
最近,麻省理工学院的研究人员提出了一个全新的数学框架ExSum,可以形式化地量化和评估机器学习模型的可解释性的可理解度,论文已被NAACL 2022接收。


论文链接:https://arxiv.org/pdf/2205.00130.pdf
说得通俗点,就是看你「解释模型的规则」适不适用于更多的数据。
局部解释的一大弊端就是没法判断规则是不是可以扩展到其他测试样例上,比如高亮了「精彩」作为电影评论的正向词,那是不是意味着「不」之类的否定词就对测试没影响了?
使用ExSum,用户可以用三个指标来查看规则是否成立:覆盖率、有效性和清晰度。
覆盖率衡量规则在整个数据集中的适用范围;有效性则显示有多少样例使得规则成立;清晰度描述了规则的精确程度:一个有效的规则可能也很通用,但对于理解模型来说则没有用处。
文章的第一作者Yilun Zhou是麻省理工学院电子工程和计算机科学系(EECS)的五年级博士生,导师为Julie Shah教授。目前的研究方向是帮助人类更好地理解那些在世界上做出重要决策的模型,主要问题包括如何确保一个黑盒模型的正确工作?如何对预期的和更重要的非预期的模型行为有一个全面的理解?人类对这种复杂推理过程的理解有什么局限性?
为了回答这些问题,他开发了可解释机器学习的模型、算法和评估,并将其应用于不同的领域,包括计算机视觉(CV)、自然语言处理(NLP)和机器人学。

用数学描述经验
在训练文本分类模型时,对模型进行解释通常会怎么做?
先给模型输入一个句子,然后模型给文本预测一个标签。如果预测正确,就分析一下句子中每个词在预测中的重要度。
比如下图中的例句,在情感分类任务中的标签为正向,使用SHAP解释方法可以对文本中的每个词测量贡献度,比如「memorable」和「great」的评分更高,在情感分类时预测重要度更高;而停用词「for」得分只有-0.02,基本就是忽略掉了,对预测结果没有影响。
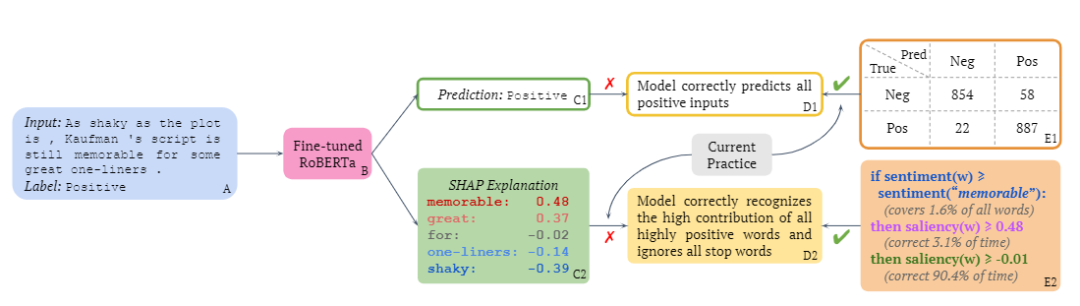
这么一验证,再加上模型的分类性能特别好,你可能会得出结论:模型能够正确地识别所有正向词、忽视停用词。
但事实果真如此吗?
孤证不立,模型在其他数据上是否能满足这个结论,还是个未知数;并且用人来观察这种方式也不够自动化。
ExSum框架的做法就是将这条规则「数学化」,在进行模型解释时,每个单词的每个特征都称之为一个基本的解释单元(fundamental explanation unit, FEU),在这个例子里,用到的特征就是SHAP评分。
然后生成一条规则,比如句子的情感评分(0.638)比「memorable」的评分更高,然后以0.479的评分作为正向词的基准,判断在其他句子上该条规则的正确率(3.1%)。
这种方法可以自动地测量规则的覆盖度、有效性和清晰度,能够帮助开发者更深入地理解模型的行为。
上手指南
随文章一同发布的还有ExSum框架程序,只需要通过pip install exsum即可开始「模型解释」之旅。
ExSum主要用于检查和修改针对文本二分类模型的ExSum规则,包含Exsum规则和规则集合的类定义,基于Flask的服务器,还可以对规则和规则集合进行交互式可视化展示。
代码链接:https://github.com/YilunZhou/ExSum
教程链接:https://yilunzhou.github.io/exsum/documentation.html
运行ExSum GUI后可以看到程序主要分为5个面板。
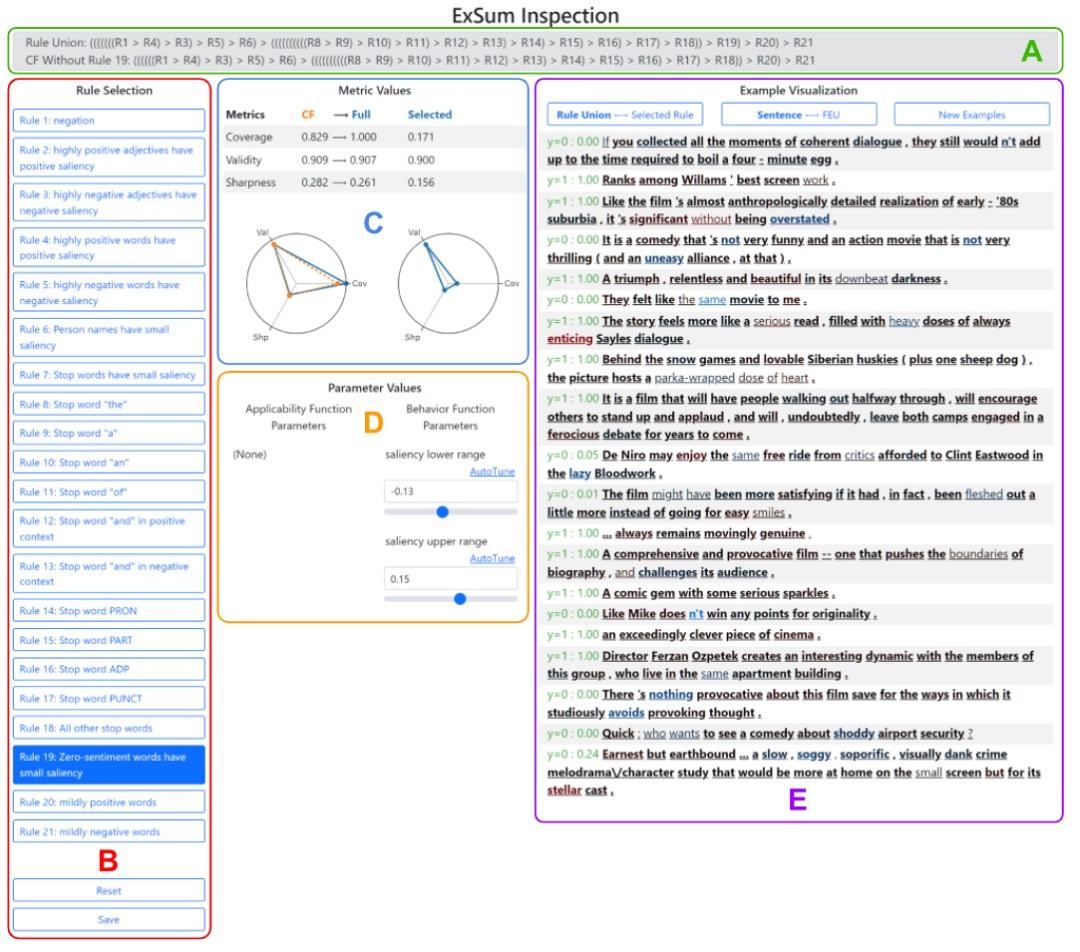
面板A显示规则的组成结构,并非所有的规则都被选中,比如A表示不使用规则2和7,但每个规则最多只能使用一次。

当选择一条规则时,将自动计算一个没有该规则的反事实(counterfactual, CF)规则联合,以便用户直观地了解其边际贡献,第二行则显示了CF规则集合的结构。
面板B将所有规则转为按钮,用户可以通过单击规则来更详细地检查规则,底部是重置和保存按钮。重置按钮用来放弃对规则(面板D)中的参数值所做的所有更改,保存按钮则将当前规则集合的副本保存到某个指定目录中。
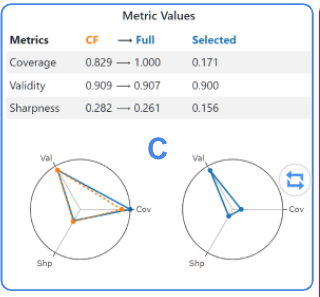
面板C以数字和图形形式显示为完整规则集合、CF规则集合和选定规则计算的度量值。对规则所做的任何更改都会自动触发对这些值的重新计算和更新。
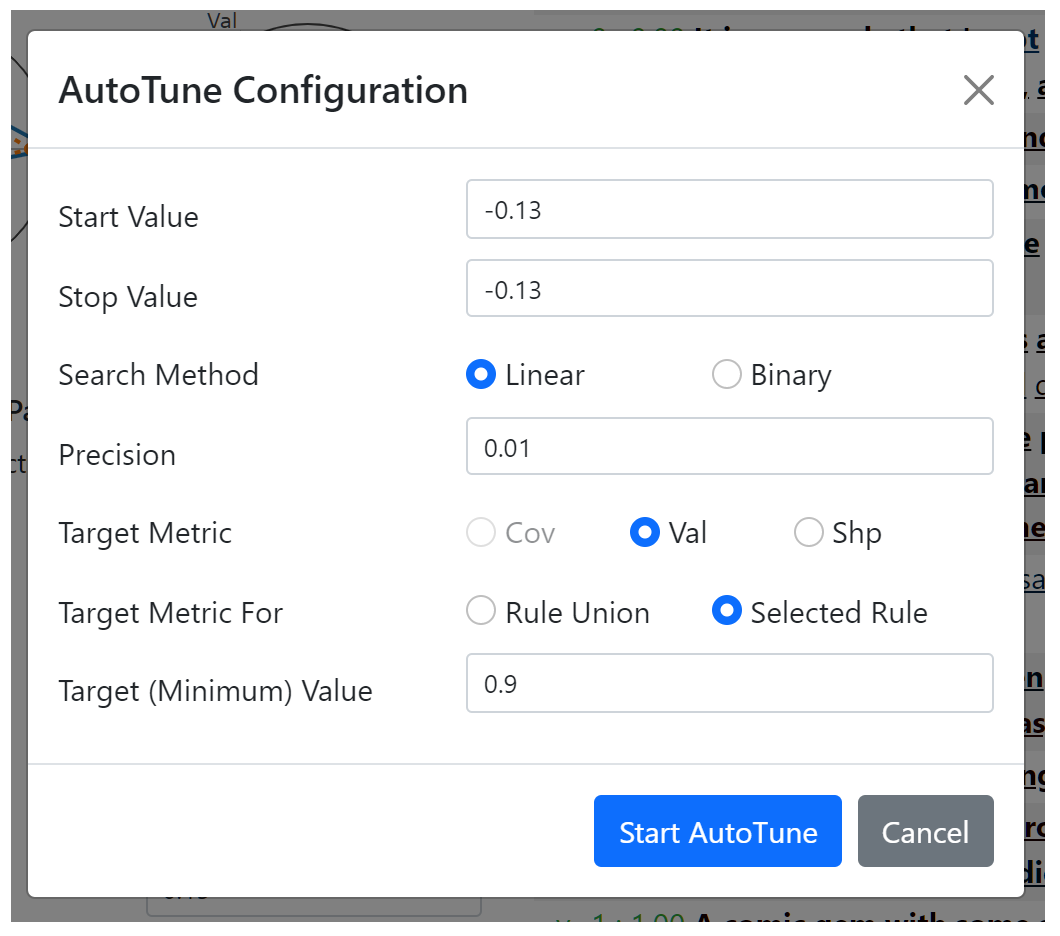
面板D列出所选规则的参数,可以通过输入或使用滑块手动更改。

此外,还可以使用AutoTune工具箱自动调整参数。
面板E显示特定数据实例上的规则和规则集合,包括三个控制按钮,分别用来在切换显示整个规则集合和仅显示选定规则、切换显示整个句子或仅显示句子中的一个FEU、重随机数据并显示新的一批实例。

当预测正确时(使用0.5作为阈值),文本为绿色,否则为红色。
单词的下划线表示它被所选规则或规则集合覆盖,对于覆盖词,粗体表示根据行为函数是有效的。
将鼠标悬停在每个单词上会显示一个工具提示,显示数字属性值和覆盖该单词的规则(如果有)。下图显示了一个例子(在这种情况下,规则19对「严重」一词无效,因为该词不是粗体字)。


























