Sentinel 结构

在 redis3.0 以前的版本要实现集群一般是借助哨兵 sentinel 工具来监控 master 节点的状态,如果 master 节点异常,则会做主从切换,将某一台 slave 作为 master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般,特别是在主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持很高的并发,且单个主节点内存也不宜设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率。
Sentinel 初始化
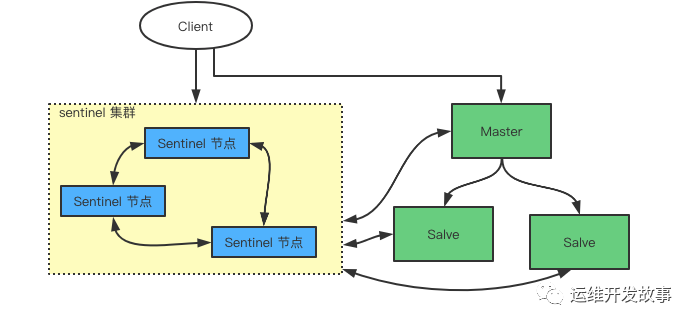
Sentinel(哨兵)是 Redis 高可用(high availability) 解决方案,由一个或者多个 Sentinel 实例(instance)组成的 Sentinel 系统(system)可以监视一个或者多个 Redis 主服务器和其跟随的从服务器,并且在被监视的主服务进入下线状态时,自动进行将当前主服务器的从服务器其中一个升级为主服务器,然后将下线的主服务器设置为新主服务器的从节点。
Sentinel 本身我们可以理解为一个特殊的 Redis 服务器, 它也可以通过 redis-server xxx.conf --sentinel启动。
下面是我们实验环境的一个 Sentinel 服务器和 Redis 服务器列表(由于实验都在本机进行,我们采用端口的方式来区分多个服务),服务和端口大致如下:
IP | 端口 | 集群 |
127.0.0.1 | 6379 | Master |
127.0.0.1 | 6380 | Slave |
127.0.0.1 | 6381 | Slave |
127.0.0.1 | 26379 | Sentinel |
127.0.0.1 | 26380 | Sentinel |
127.0.0.1 | 26381 | Sentinel |
首先我们找到 Redis 的配置文件目录,修改 redis-sentinel.conf文件中的以下参数:
# sentinel 端口
port 26381
# 后台运行
daemonize yes
# 监控主服务器和有一个 slave 节点
sentinel monitor mymaster 127.0.0.1 6379 2
Sentinel 启动命令如下:
redis-server redis-sentinel-26379.conf --sentinel
redis-server redis-sentinel-26380.conf --sentinel
redis-server redis-sentinel-26381.conf --sentinel
登录到 Sentinel 节点, 查询集群状态, 使用 info命令即可。

sentinel 服务和其他 redis 服务节点启动区别,就是在启动的过程中,不会加载 RDB 或者 AOF 来还原数据。
Sentinel 和 Redis 服务之间的通讯
- _命令连接_,建立一个链接接收主/从服务器的回复 (默认 10 秒一次发送请求 info 信息获取节点状态,故障转移的时候会变为 1 秒一次。并且每一秒向服务器节点发一个 PING 命令判断服务是否在线)。

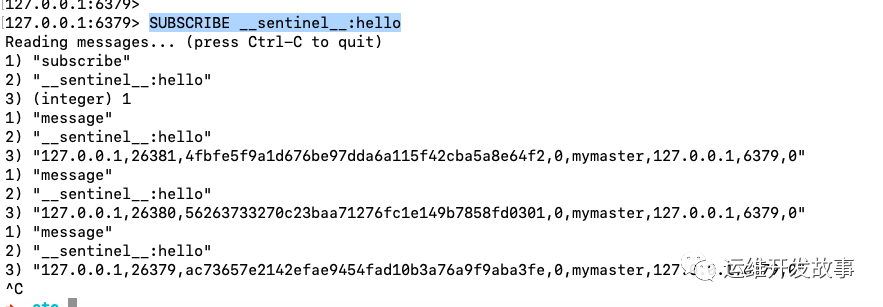
- 订阅链接,用于订阅主服务器的 __sentinel__:hello 频道。
我们先验证一下在主节点上查询,执行 SUBSCRIBE __sentinel__:hello。
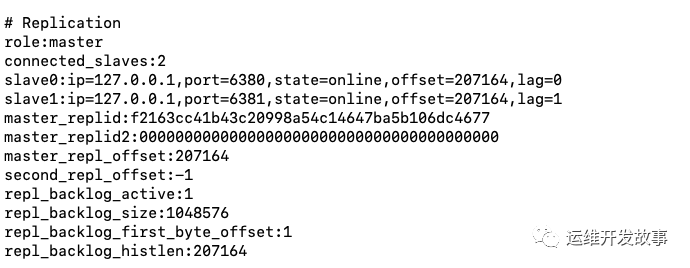
主节点服务上的同步信息,我们可以通过 INFO 命令来查询。
从节点服务器上通过 INFO 命令查询同步信息。

Sentinel 之间通讯
- 对于监视同一个主/从服务器的多个 Sentinel 节点,他们会以每两秒一次的频率,向被监视的服务器的 __sentinel__:hello 频道发送消息来宣告自己存在。
- Sentinel 之间不会创建订阅链接,通过命令通讯。因为已经可以通过主/从服务器获取未知的 Sentinel 服务节点。
Sentinel 获取 Redis 节点列表
** Sentinel 会默认 10 秒一次向主服务器信息,通过发送 info 命令**,的回复来获取当前主服务器的信息。
# Server
run_id:5e4d6e3ee147ff231d540ae2add485e906944f2a
...
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=2712947,lag=0
slave1:ip=127.0.0.1,port=6380,state=online,offset=2712947,lag=0
master_replid:f2163cc41b43c20998a54c14647ba5b106dc4677
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2713213
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1664638
repl_backlog_histlen:1048576
....
通过分析主服务器的 info 命令可以获取到以下两方面的信息:
- 关于服务器本身的信息,包括 run_id 记录服务器运行的 id, 以及服务器 role 角色等。
- 另外一方面就是获取主服务器下面的所有从服务器信息,比如:slave0:ip=127.0.0.1,port=6381,state=online,offset=2712947,lag=0这样就不需要我们在 conf 文件中配置从服务器的信息,Sentinel 可以自动发现。
当 Sentinel 从主服务器获取到从服务器信息过后,也会 10 秒钟向从服务器发送 INFO 命令来获取从服务器信息 我们可以执行命令 redis-cli -h 127.0.0.1 -p 6380 info 得到以下信息:
# Server
run_id:7ef635af0d3e0b1d60d2776eba0a15883db06245
...
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:2779874
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:f2163cc41b43c20998a54c14647ba5b106dc4677
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2779874
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1731299
repl_backlog_histlen:1048576
...
我们从结果中可以得到以下信息:
- 服务器的运行 Id run_id。
- 服务器的角色 role。
- 主服务器的信息 master_host, master_port。
- 主从服务器的连接状态 master_link_status。
- 从服务器的优先级 slave_priority。
- 从服务器的复制偏移量 slave_repl_offset。
服务下线
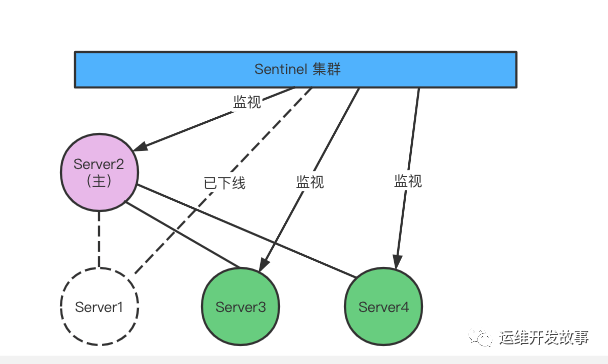
主观下线:一台 sentinel 判断下线 客观下线:主观下线后会询问其他的 sentinel 节点判断是否该主节点下线,如果是真的下线了,那么就是客观下线。
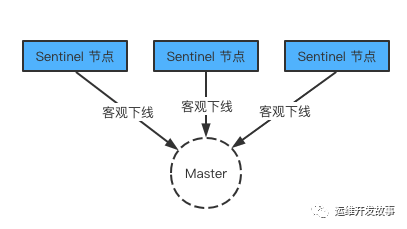
判断下线的方式
sentinel 配置文件中 down-after-millseconds 选项制定了 sentinel 实例进入主观下线所需的时间;如果一个实例在 down-after-millseconds毫秒内,连续向 Sentinel 返回无效回复,那么 Sentinel 会修改这个实例所对应的实例结构,在结构的 flags 属性中打开 SIR_S_DOWN 标示,来表示这个实例主观下线。当超过一半的哨兵节监测到一个redis 节点下线后此刻在该集群中该节点才算真正被判断为下线,也叫客观下线。
选举领头 sentinel
当发生 master 节点客观下线后,会进行 sentinel 选举,进行选举出领头 sentinel 对 redis sentinel 集群做故障转移。领头 sentinel 选举规则:
- 所有在线的 sentinel 都具有选举资格。
- 每次选举后,不管是否选举成功,sentinel 配置纪元(configuration epoch)都会自增一次。
- 每个配置纪元里面都有一次将某个 sentinel 设置为局部领头 sentinel 的机会,且局部领头 sentinel 一旦设置当前配置纪元里面不可修改。
- 每个发现主服务器客观下线的 sentinel 都会要求其他的 sentinel 将自己设置为局部的 领头 sentinel
- sentinel 局部领头 sentinel 的规则是先到先的,最先向目标 sentinel 发送设置要求的 sentinel 先设置成功,之后的都会被拒绝。
- 如果某个 sentinel 被半数以上的 sentinel 设置成了局部领头 sentinel ,那么这个 sentinel 就成为领头 sentinel。
- 因为领头 sentinel 产生需要半数的 sentinel 的支持,并且每个配置纪元里面只能设置一次 领头 sentinel ,所以只会出现一个领头 sentinel。
- 如果在指定的时间内没有产生领头 sentinel 那么就会进行再次选举,直到选出领头 sentinel 为止。
故障转移
故障转移分为三个步骤:
- 在已经下线的主服务器下的所有服务器里中,选择一个从服务器,将器作为主服务器。
- 让已经下线的主服务器下的所有从服务器复制新的主服务器。
- 将已经下线的主服务器设置为新主服务器的从服务器,当这个旧的主服务器重新上线后它就会成为新的主服务器的从服务器。
选择新主服务器
- 对从服务器进行过滤。
- 删除处于下线的从服务器,保证都是正常在线的。
- 删除列表中所有 5 秒没有回复过 sentinle leader 的 info 命令的服务器,可以保证列表中剩余的从服务器通讯正常。
- 保证从服务器的数据是最新的,主要是删除与主服务器断开链接超过 down-after-millseconds * 10 毫秒的服务器。保证没有过早的断开链接。
- 最后按照上面的筛选过后,进行排序,选择其中优先级最高的。
1) 如果存在多个相同优先级的,考虑偏移量(slave_repl_offset)最大的从服务器,因为偏移量最大说明保存的数据是最新的。
2) 如果还是存在相同的偏移量的从服务器,那么就选择运行 id(run_id)最小的从服务器。
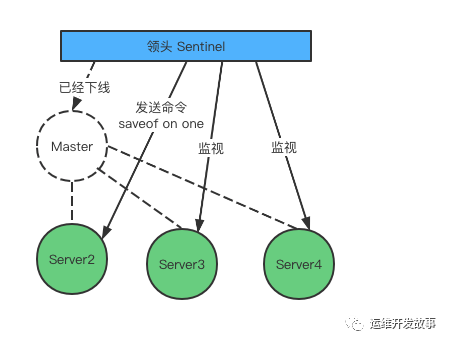
发生故障转移后 Server2 升级为主服务器
修改从服务器的复制目标
当新的主服务器出现后 ,领头的 Sentinel 会让其他的服务器节点,去复制新的主节点的数据可以通过向从服务器发送 saveof 命令来实现。
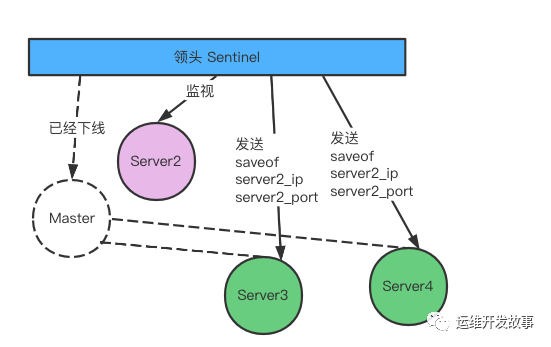
将旧的主服务器变成从服务器
故障转移的最后操作,就是将已经下线的的主服务器设置为新的主服务的从服务器。