














译者 | 陈峻
公司在选择他们的在线特征存储之前,通常会执行全面的基准测试,以比较哪一种架构是最高效且具有成本效益的。本文将和您讨论四种成功部署了实时 AI/ML 用例的开源与商业化的特征存储架构和基准。
如今,随着欺诈预防和个性化推荐等实际商业用例的广泛使用,特征存储(Feature Stores)在将AI/ML技术实时、成功地部署到生产环境的过程中,发挥着关键性的作用。
目前最流行的开源特征存储平台之一当属Feast。用户在其Slack社区(https://slack.feast.dev/)中提及最多的便是Feast的可扩展性与性能。毕竟,对于实时的AI/ML特征存储而言,最重要的指标便是被用于在线预测或评分的ML模型的特征服务速度。
通常,成功的特征存储应当满足如下严格的要求:
- 低延迟(以毫秒为单位)
- 一致性(以99%的情况结果来衡量)
- 成规模(每秒高达十万、甚至百万的查询量,以及千兆、甚至TB字节的数据集)
- 较低的总体拥有成本和高精确度
公司在选择他们的在线特征存储之前,通常会执行全面的基准测试,以比较哪一种架构是最高效且具有成本效益的。下面,我们将和您一起讨论四种成功部署了实时AI/ML用例的开源与商业化的特征存储架构和基准。
1.开源的Feast
我们先来看看Feast(https://feast.dev/)开源特征存储的基准数据、及其数据架构。在其最近的一个基准测试中,Feast比较了使用不同的在线存储(即Redis、Google Cloud DataStore和AWS DynamoDB)时特征服务的延迟,并比较了使用不同机制的提取特征(如Java gRPC服务器、Python HTTP服务器、以及lambda函数等)时的速度。您可以从链接—https://feast.dev/blog/feast-benchmarks/,了解完整的基准测试设置及其结果。其中,Feast发现在使用Java gRPC服务器与Redis组合作为在线存储时,性能最高。
来源:https://www.applyconf.com/agenda/using-feast-in-a-ranking-syst
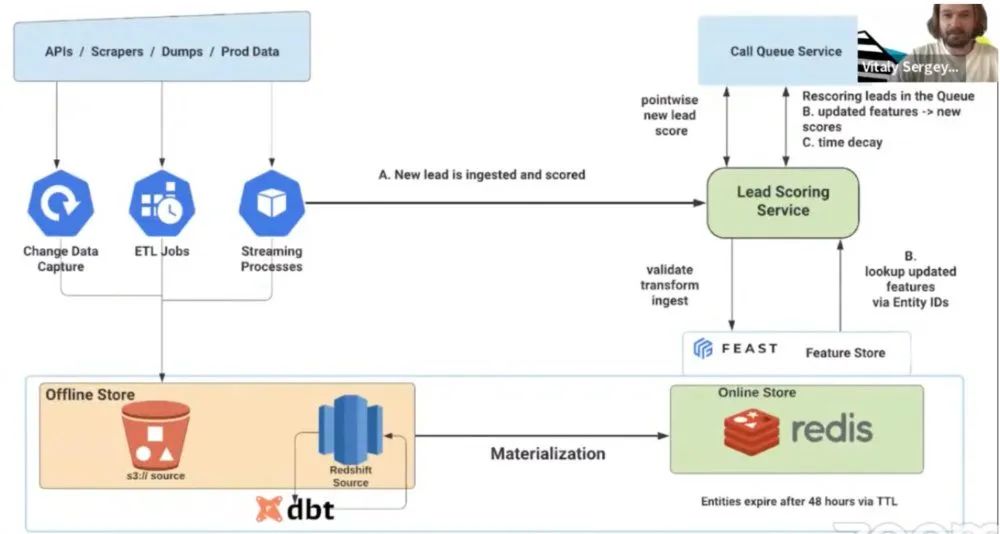
在上图中,您可以看到知名的在线抵押贷款公司Better.com是如何使用开源的Feast特征存储,来构建对其潜在客户的评分排名系统。Better.com的高级软件工程师Vitaly Sergey介绍了从离线存储(S3、Snowflake和Redshift)到在线存储(Redis)的过程。同时,他们也将特征从流媒体源(Kafka的各个主题)摄取到了在线存储。Feast最近也添加了对于流式数据源(除了批处理数据源)的支持,不过目前仅支持Redis。
由于此类用例需要依赖实时数据,因此支持流式数据源对于实时的AI/ML用例是非常重要的。例如,在该评分用例中,新的潜在客户数据被实时地摄取到。只要有一个新的潜在客户被发现,它就会被模型摄取并予以评分,同时它会被摄取到在线存储中,以便我们在后续对其进行重新排名。同时,Better.com会让潜在客户在48小时后过期。这是在Redis在线存储中实现的。他们只需将TTL(生存时间,time to live)设置为48小时,那么实体(即潜在客户)与关联特征向量就会在48小时后过期。也就是说,特征存储会自动自行清理,以保证没有旧的实体或特征占用宝贵的在线存储空间。
Feast的另一个实现是Microsoft Azure的特征存储(https://techcommunity.microsoft.com/t5/ai-customer-engineering-team/bringing-feature-store-to-azure-from-microsoft-azure-redis-and/ba-p/2918917)。你可以通过链接--https://techcommunity.microsoft.com/t5/image/serverpage/image-id/323561i3F763F78F483587D/image-size/large?v=v2&px=999,来参考它的架构。它运行在针对低延迟实时AI/ML用例进行过优化的Azure云上,能够支持批处理和流式数据源,并集成到Azure数据和AI生态系统中。各种特征从批处理源(Azure Synapse Serverless SQL、Azure Storage/ADLS)和流式源(Azure Event Hub)被摄取到在线存储处。在线存储使用的是带有Enterprise Tiers of Azure Redis的Azure Cache,包括了通过主动异地复制,来创建具有高达99.999%可用性的全局分布式缓存。因此,如果您的应用已经部署在Azure上,或熟悉Azure生态系统,那么此类特征存储就比较适合。此外,通过使用Enterprise Flash层在分层内存架构上运行Redis,并使用内存(DRAM)和闪存(NVMe或SSD)来存储数据,还可以进一步降低成本。
2.Wix将DIY特征存储作为MLOps平台的基石
流行的网站建设平台Wix(https://www.wix.com/)将特征存储架构用于诸如推荐、生产、溢价、预测、排名、以及垃圾邮件分类器等MLOps平台应用中。虽然Wix能够为超过2亿的注册用户提供服务,但是在任何给定的时间内,通常只有少部分的活跃用户。因此,这对特征存储的实现方式提出了一定的影响。下图源自Wix的ML Engineering领导Ran Romano在TechTalk上的演示文稿(https://youtu.be/E8839ENL-WY?t=2061)。Wix的特征存储中存储着超过90%的点击流,ML模型可以按照网站或用户被触发。Ran解释说,对于生产环境中的实时用例而言,他们需要在几毫秒内提取特征向量,因此需要避免延迟。
来源:https://youtu.be/E8839ENL-WY?t=2061
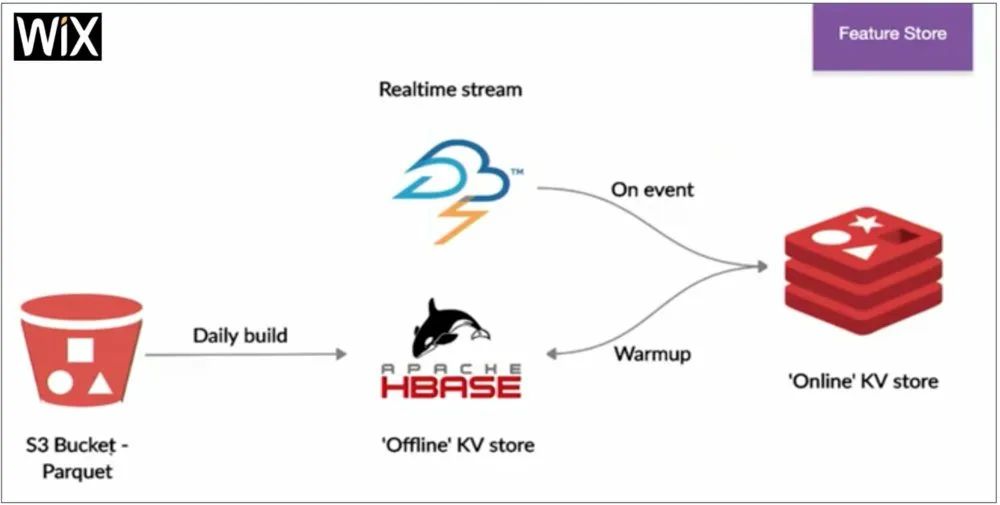
如上图所示,原始数据被存储在AWS Parquet文件的S3存储桶中,并按业务单元(如“编辑”、“餐厅”、“预订”等)以及日期进行分区。在使用Spark SQL的日常构建批处理过程(需要几分钟到几小时)中,所有用户的历史记录特征都会从S3中提取,按用户进行转换和聚合,然后被提取到离线存储(Apache Hbase)中。这种“按用户”的方式,能够加快针对用户的历史查找。一旦系统检测到用户当前处于活动状态,“预热(Warmup)”流程就被触发,该用户的特征则会被加载到比离线存储小得多的、只用来保存活动用户历史记录的在线存储(Redis)中。该“预热”过程通常需要几秒钟。最后,在线特征存储中的特征,会使用来自用户的每个事件(使用Apache Storm)作为“实时”流数据,进行持续更新。
与Feast架构相比,Wix架构的读写速率较低。但是由于它只为在线存储中的活跃用户提供存储特征,而非所有用户,因此在具体化(materialization)和在线存储方面非常高效。而且,活跃用户在Wix中仅占所有注册用户的一小部分,因此也节省了不少空间。
不过,虽然我们从在线存储中检索特征只需几毫秒,但前提是在线存储中已经存在了这些特征。相反,由于预热过程需要几秒钟,那么对于某些变得活跃的用户而言,可能会由于加载相关特征的速度不够快,根据竞态条件(race conditions),用户会因评分过低而导致失败。可见,只要用例不是关键性的流程或任务(如:批准交易或防范欺诈),就可以使用此类架构。
3.商业化特征存储--Tecton
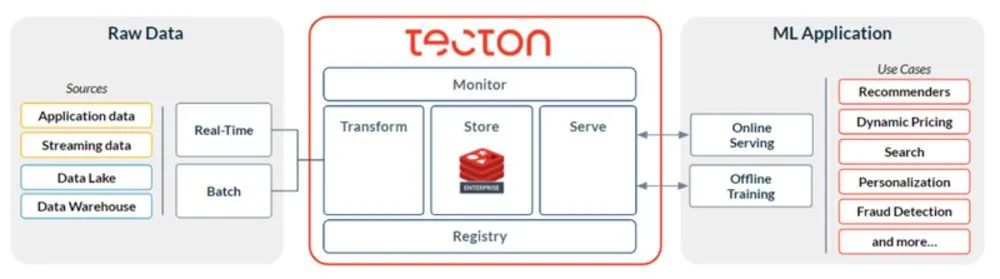
除了批量数据源和流式数据源,商业化的企业特征存储Tecton(https://www.tecton.ai/)架构还支持“开箱即用”的实时数据源(也称为“实时特性”或“实时转变”)。由于Tecton已经能够被特征存储原生支持,因此它更易于实现。
与Feast和Wix的特征存储一样,Tecton也在注册表中定义了各种特征,以便为离线和在线存储进行一次性的逻辑定义,以显著减少训练服务的偏差,进而确保ML模型在生产环境中的高精度。
来源:https://www.tecton.ai/blog/delivering-fast-ml-features-with-tecton-and-redis-enterprise-cloud/
下面我们来看看Tecton在离线存储、在线存储和基准测试等方面的特点:就离线特征存储而言,Tecton支持S3。就在线存储而言,Tecton为客户提供DynamoDB和Redis Enterprise Cloud之间的选择(https://www.tecton.ai/blog/delivering-fast-ml-features-with-tecton-and-redis-enterprise-cloud/)。而在最近的一次演示中,Tecton首席技术官Kevin Stumpf根据公司近期执行的基准测试,给出了有关如何选择在线特征存储的建议,请参见--https://youtu.be/osxzKxiznm4。除了对延迟和吞吐量进行基准测试,Tecton也对在线存储的成本进行了基准测试。其原因在于,对于高吞吐量或低延迟的用例而言,在线存储的成本可能占整个MLOps平台总拥有成本的大部分,因此任何成本的节省都是非常有益的。
Tecton在对用户的典型高吞吐量用例进行基准测试时发现,与DynamoDB相比,Redis Enterprise的速度提高了3倍,同时成本降低了14倍。详细的测试结果请参见--https://www.tecton.ai/blog/announcing-support-for-redis/。可见,除非您只有一个用例,而且它既没有高并发量,又没有严格的延迟要求,那么就可以使用DynamoDB。
4.Lightricks使用商业化特征存储——Qwak
Lightricks是一家专为视频和图像编辑开发移动应用程序的独角兽公司,Facetune就是其著名的自拍编辑APP。它也将特征存储用到了其推荐系统上。
来源:https://www.youtube.com/watch?v=CG2vUCcvnD8&t=1915s
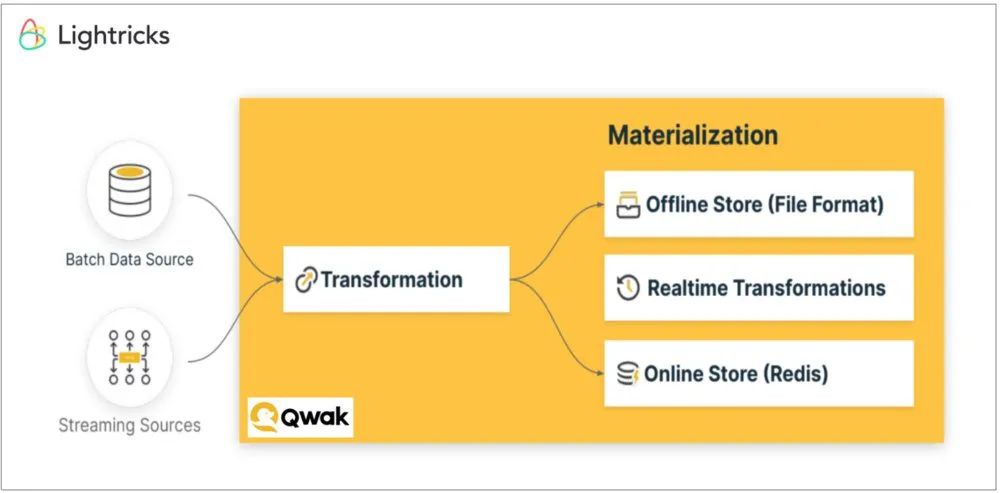
如上图所示,Qwak的特征库也支持开箱即用的三种特征源——批处理、流式和实时特征。这与Tecton十分类似。不过,在使用Qwak特征存储时,他们是从离线存储(使用S3上的Parquet文件)和在线存储(使用Redis)的原始数据源处,将特征具体化到了特征存储中的。这与来自Wix、Feast或Tecton的特征存储示例有所不同。此举动的好处在于,不仅单个特征的转换逻辑,在训练和服务流之间是统一的(就像上面的Feast、Wix和Tecton的特征存储一样),而且实际的转换或特征计算也是统一完成的,这样就进一步减少了训练-服务的偏差。也就是说,拥有源于原始数据的统一离线与在线,可以在生产环境中确保更高的准确性。您可以通过链接--https://drive.google.com/file/d/1KfOMI9C-aitJNPdGB56L-6tA8BBp9gsl/view,了解Qwak的更多有关特征存储架构和组件的内容。
5.小结
通过对上述四种用于实时AI/ML特征存储的基准和架构的讨论,我们可以看到,由于架构、支持的特性类型和选择的组件的不同,它们所产生的特性存储的性能和成本会存在显著的差异。同时,我们也在文中比较了哪一种在线存储的性能最高、最具成本效益,以及该使用哪一种机制或特征服务器,从在线存储中提取特征。
原文链接:https://www.kdnuggets.com/2022/03/feature-stores-realtime-ai-machine-learning.html
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。




























