最近公司日志Kafka集群出现了性能瓶颈,单节点还没达到60W/tps时消息发送就出现了很大延迟,甚至最高超过了10s,截图说明如下:
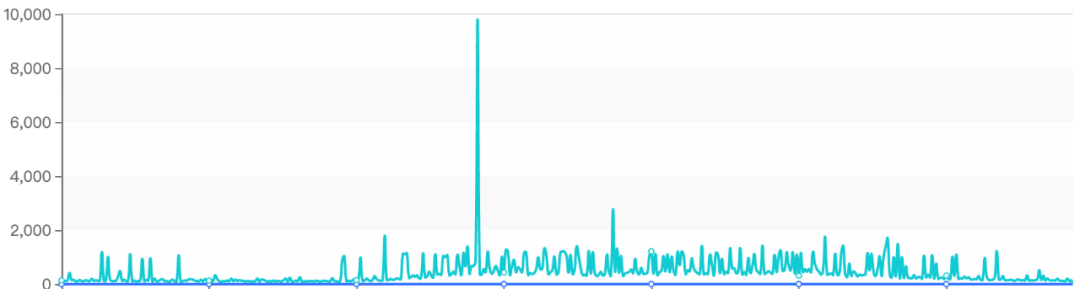
虽说使用的机械磁盘,但这点压力对Kafka来说应该是小菜一碟,这引起了我的警觉,需要对其进行一番诊断了。
通过监控平台观察Kafka集群中相关的监控节点,发现cpu使用率才接近20%左右,磁盘IO等待等指标都并未出现任何异常,那会是什么问题呢?
通常CPU耗时不大,但性能已经明显下降了,我们优先会去排查kafka节点的线程栈,获取线程栈的方法比较简单,命令为:
ps -ef | grep kafka // 获取pid
jstack pid > j1.log
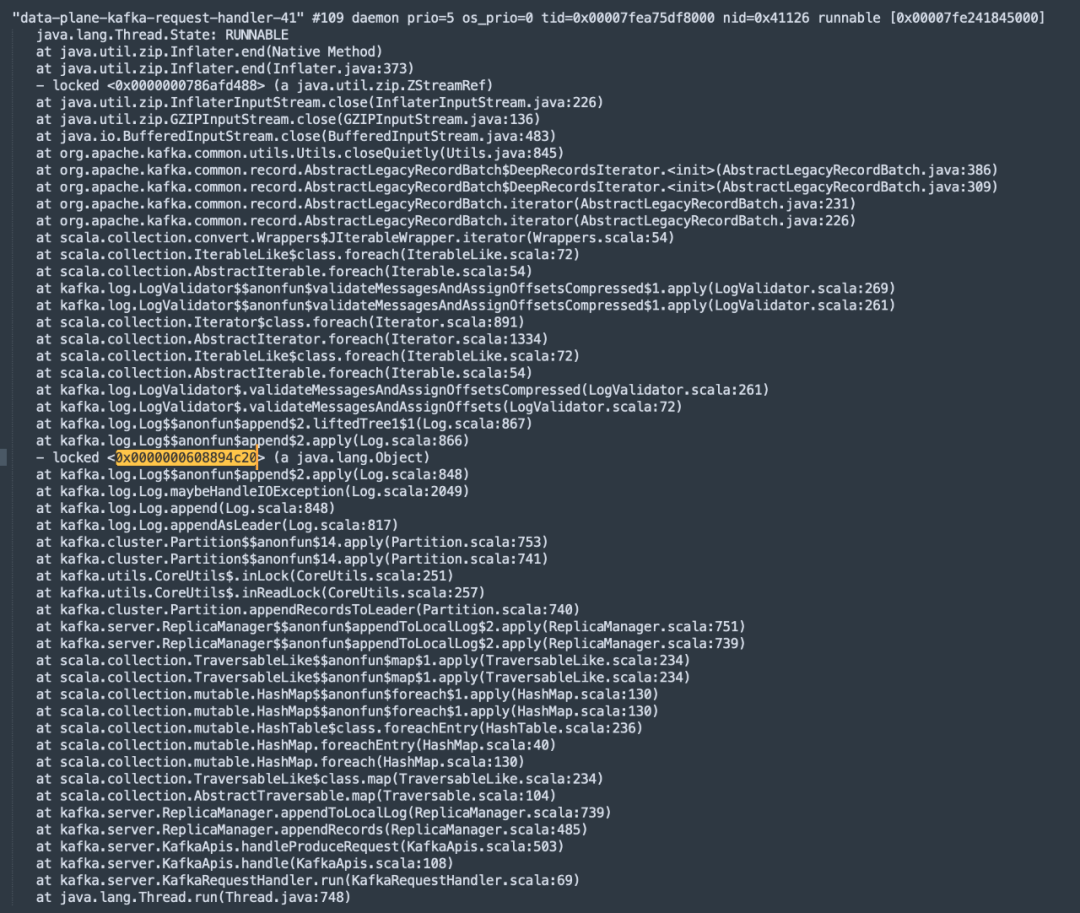
通过上述命令我们就可以获取到kafka进程的堆栈信息,通过查看线程名称中包含kafka-request-handler字眼的线程(Kafka中处理请求),发现了大量的锁等待,具体截图如下所示:
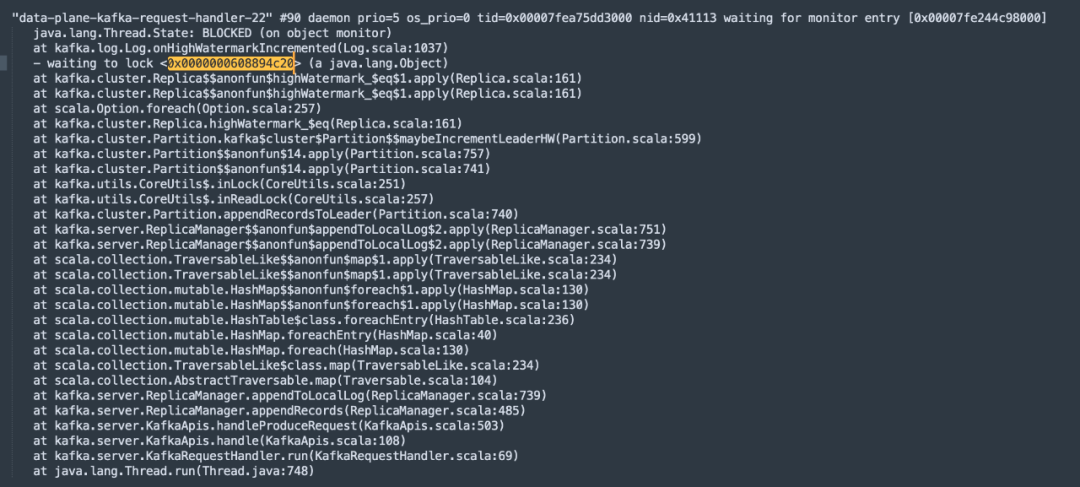
并且在jstack文件中发现很多线程都在等待这把锁,截图如下:
我们先根据线程堆栈查看代码,找到对应的源代码如下图所示:
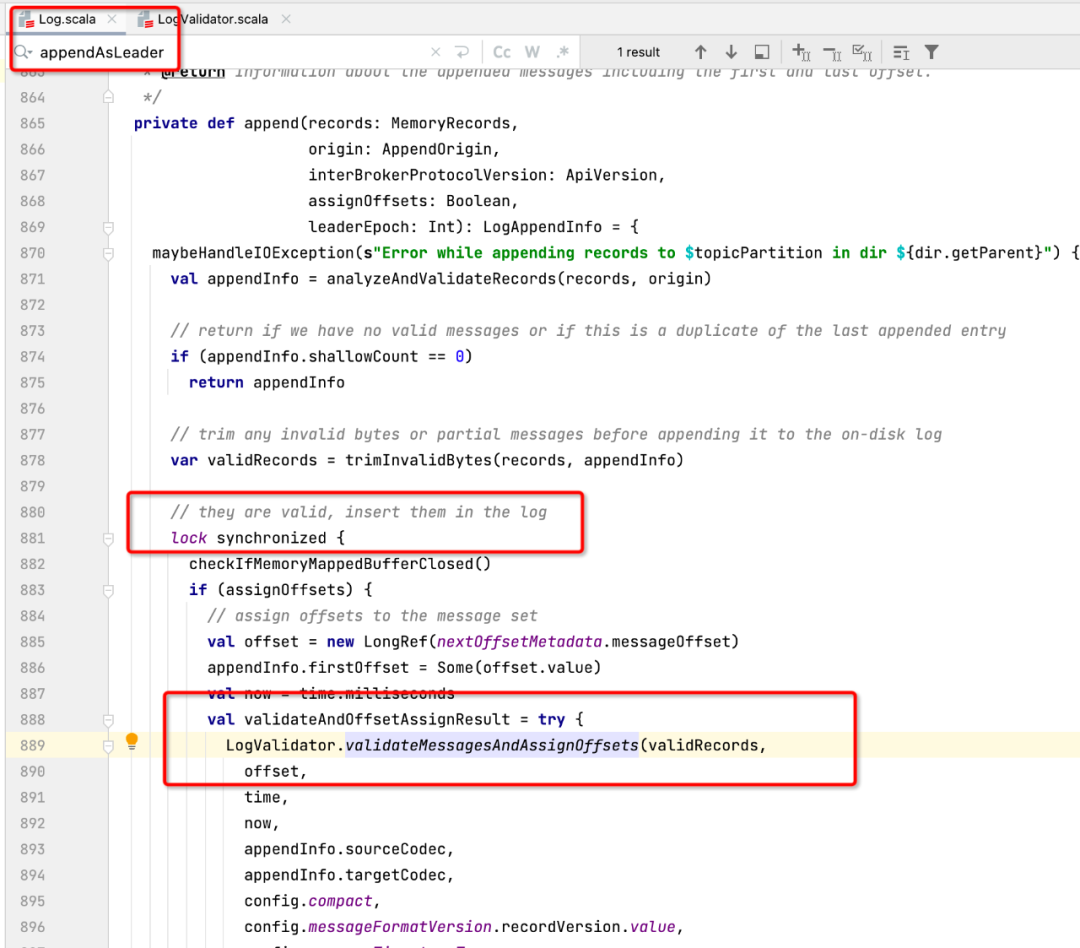
通过阅读源码,这段代码是分区Leader在追加数据时为了保证写入分区时数据的完整性,对分区进行的加锁,即如果对同一个分区收到多个写入请求,则这些请求将串行执行,这个锁时必须的,无法进行优化,但仔细观察线程的调用栈,发现在锁的代码块出现了GZIPInputstream,进行了zip压缩,一个压缩处在锁中,其执行性能注定低下,那在什么时候需要在服务端进行压缩呢?
故我们继续看一下LogValidator的validateMessagesAndAssignOffsets方法,最终调用validateMessagesAndAssignOffsetsCompressed方法,部分代码截图如下所示:
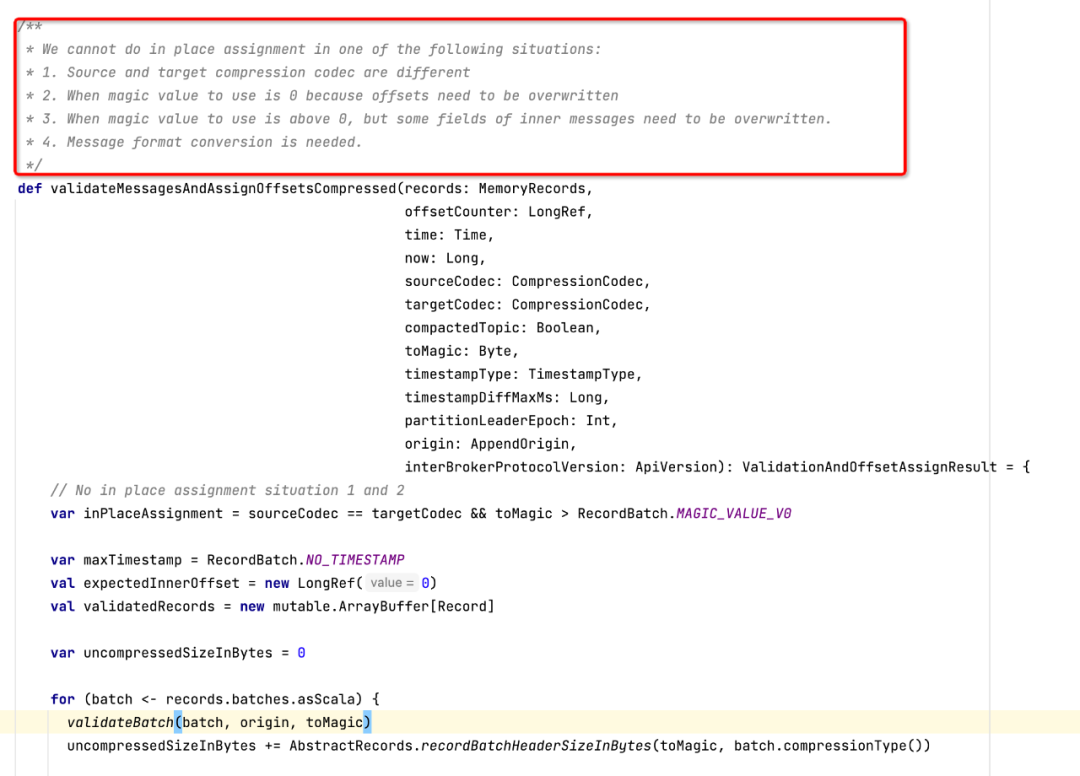
这段代码的注释部分详细介绍了kafka在服务端需要进行压缩的4种情况,对其进行翻译,其实就是两种情况:
- 客户端与服务端端压缩算法不一致
- 客户端与服务端端的消息版本格式不一样,包括offset的表示方法、压缩处理方法
关于客户端与服务端压缩算法不一致,这个基本不会出现,因为服务端通常可以支持多种压缩算法,会根据客户端的压缩算法进行自动匹配。
最有可能的就是服务端与客户端端消息协议版本不一致,如果版本不一致,则需要在服务端重新偏移量,如果使用了压缩机制,则需要重新进行解压缩,然后计算位点,再进行压缩存储,性能消耗极大。
后面排查日志使用端,确实是客户端版本与服务端版本不一致导致,最终需要对客户端进行统一升级。